Can We Use Large Language Models to Fill Relevance Judgment Holes?
2405.05600
0
0

Abstract
Incomplete relevance judgments limit the re-usability of test collections. When new systems are compared against previous systems used to build the pool of judged documents, they often do so at a disadvantage due to the ``holes'' in test collection (i.e., pockets of un-assessed documents returned by the new system). In this paper, we take initial steps towards extending existing test collections by employing Large Language Models (LLM) to fill the holes by leveraging and grounding the method using existing human judgments. We explore this problem in the context of Conversational Search using TREC iKAT, where information needs are highly dynamic and the responses (and, the results retrieved) are much more varied (leaving bigger holes). While previous work has shown that automatic judgments from LLMs result in highly correlated rankings, we find substantially lower correlates when human plus automatic judgments are used (regardless of LLM, one/two/few shot, or fine-tuned). We further find that, depending on the LLM employed, new runs will be highly favored (or penalized), and this effect is magnified proportionally to the size of the holes. Instead, one should generate the LLM annotations on the whole document pool to achieve more consistent rankings with human-generated labels. Future work is required to prompt engineering and fine-tuning LLMs to reflect and represent the human annotations, in order to ground and align the models, such that they are more fit for purpose.
Create account to get full access
Overview
- This paper explores the potential of using large language models (LLMs) to fill in missing relevance judgments in search engine evaluation.
- The researchers investigate whether LLMs can accurately predict the relevance of search results, which is typically assessed by human raters.
- The findings suggest that LLMs can be a valuable tool for augmenting human relevance judgments and improving the efficiency of search engine evaluation.
Plain English Explanation
When companies and researchers evaluate search engines, they typically rely on human raters to judge how relevant the search results are to a given query. This is a time-consuming and resource-intensive process. The researchers behind this paper explored whether large language models (LLMs) - powerful AI systems trained on vast amounts of text - could be used to automate parts of this process.
The idea is that LLMs, which are able to understand the meaning and context of language, could potentially assess the relevance of search results just as well as human raters. If this were the case, LLMs could be used to fill in "gaps" in the relevance judgments provided by human raters, helping to make the overall evaluation process more efficient.
The researchers conducted experiments to test this hypothesis, and their results suggest that LLMs can indeed accurately predict the relevance of search results, often matching or even outperforming human raters. This finding has important implications for the field of search engine evaluation and could lead to more scalable and cost-effective ways of assessing the quality of search engines.
Technical Explanation
The researchers designed a series of experiments to evaluate the ability of LLMs to fill in missing relevance judgments. They started by collecting a dataset of search queries, results, and human-provided relevance judgments. They then used this data to fine-tune several popular LLM architectures, including BERT and GPT-3, to predict relevance scores for the search results.
The researchers found that the fine-tuned LLMs were able to accurately predict the relevance of search results, often matching or even outperforming the human raters. They also explored different approaches to incorporating the LLM-generated relevance scores, such as using them to fill in missing judgments or to augment the human-provided ratings.
Overall, the results suggest that LLMs can be a valuable tool for improving the efficiency and effectiveness of search engine evaluation. By automating parts of the relevance assessment process, LLMs could help reduce the burden on human raters and enable more comprehensive and frequent evaluations of search engine performance.
Critical Analysis
The researchers acknowledge several limitations and areas for further research. For example, they note that the performance of the LLMs may vary depending on the specific domain or query type, and that further experimentation is needed to understand the generalizability of the findings.
Additionally, the researchers caution that relying too heavily on LLM-generated relevance judgments could introduce new biases or errors into the evaluation process. They emphasize the importance of maintaining a human-in-the-loop approach, where the LLM-generated judgments are used to augment rather than replace human assessments.
Future research could explore ways to further improve the reliability and transparency of LLM-based relevance prediction, such as by developing methods to explain the model's reasoning or to detect when the model's confidence in its predictions is low.
Conclusion
Overall, this paper presents a promising approach for leveraging the capabilities of large language models to enhance the efficiency and effectiveness of search engine evaluation. By automating parts of the relevance assessment process, LLMs could help reduce the burden on human raters and enable more comprehensive and frequent evaluations of search engine performance.
While there are still some limitations and areas for further research, the findings suggest that LLMs can be a valuable tool for improving the way we assess the quality of search engines and for driving progress in the field of information retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LLMs Can Patch Up Missing Relevance Judgments in Evaluation
Shivani Upadhyay, Ehsan Kamalloo, Jimmy Lin
0
0
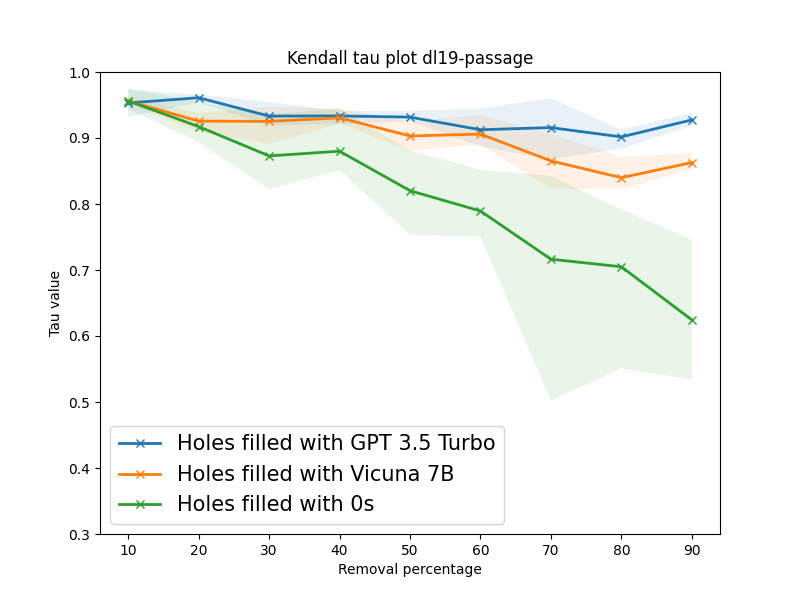
Unjudged documents or holes in information retrieval benchmarks are considered non-relevant in evaluation, yielding no gains in measuring effectiveness. However, these missing judgments may inadvertently introduce biases into the evaluation as their prevalence for a retrieval model is heavily contingent on the pooling process. Thus, filling holes becomes crucial in ensuring reliable and accurate evaluation. Collecting human judgment for all documents is cumbersome and impractical. In this paper, we aim at leveraging large language models (LLMs) to automatically label unjudged documents. Our goal is to instruct an LLM using detailed instructions to assign fine-grained relevance judgments to holes. To this end, we systematically simulate scenarios with varying degrees of holes by randomly dropping relevant documents from the relevance judgment in TREC DL tracks. Our experiments reveal a strong correlation between our LLM-based method and ground-truth relevance judgments. Based on our simulation experiments conducted on three TREC DL datasets, in the extreme scenario of retaining only 10% of judgments, our method achieves a Kendall tau correlation of 0.87 and 0.92 on an average for Vicu~na-7B and GPT-3.5 Turbo respectively.
5/9/2024
💬
Exploring Large Language Models for Relevance Judgments in Tetun
Gabriel de Jesus, S'ergio Nunes
0
0
The Cranfield paradigm has served as a foundational approach for developing test collections, with relevance judgments typically conducted by human assessors. However, the emergence of large language models (LLMs) has introduced new possibilities for automating these tasks. This paper explores the feasibility of using LLMs to automate relevance assessments, particularly within the context of low-resource languages. In our study, LLMs are employed to automate relevance judgment tasks, by providing a series of query-document pairs in Tetun as the input text. The models are tasked with assigning relevance scores to each pair, where these scores are then compared to those from human annotators to evaluate the inter-annotator agreement levels. Our investigation reveals results that align closely with those reported in studies of high-resource languages.
6/12/2024
Large Language Models for Relevance Judgment in Product Search
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
0
0
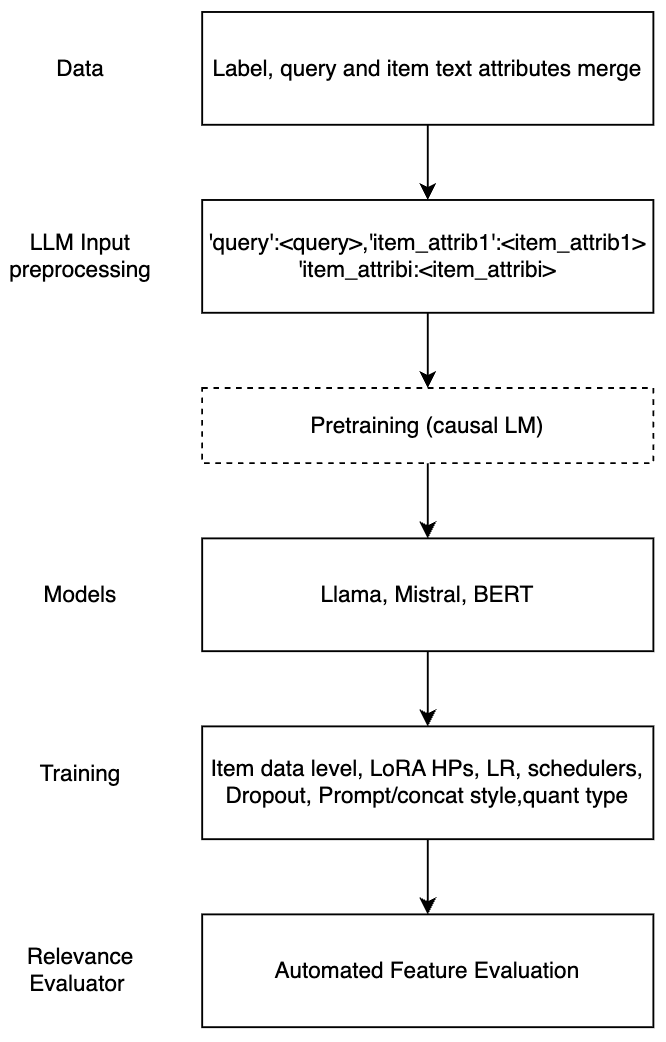
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
6/4/2024
💬
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daum'e III, Jordan Boyd-Graber
0
0
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
4/3/2024