Exploring Layerwise Adversarial Robustness Through the Lens of t-SNE

0
Sign in to get full access
Overview
- The paper explores the relationship between the adversarial robustness of neural networks and their latent space representations using t-SNE, a dimensionality reduction technique.
- The authors investigate how the robustness of different layers in a neural network changes as the network is trained to be more robust.
- They use t-SNE to visualize the latent space representations and study how these representations change with increased robustness.
Plain English Explanation
The paper looks at how neural networks, which are a type of artificial intelligence, can be made more resistant to adversarial examples. Adversarial examples are small changes to the input of a neural network that can cause it to make incorrect predictions. The researchers use a technique called t-SNE to visualize the internal representations of the neural network as it is trained to be more robust.
t-SNE is a way to take the high-dimensional data inside a neural network and project it down into a 2D or 3D space that is easier for humans to understand. By looking at how this 2D or 3D representation changes as the network becomes more robust, the researchers can see how the internal structure of the network is changing.
The key insight from the paper is that as the network becomes more robust, the latent space representations (the internal structures) of the different layers in the network change in different ways. Some layers become more robust faster than others. This suggests that to make a neural network truly robust, you need to consider the robustness of each individual layer, not just the overall network.
Technical Explanation
The paper begins by providing background on adversarial examples and t-SNE, a dimensionality reduction technique used to visualize high-dimensional data.
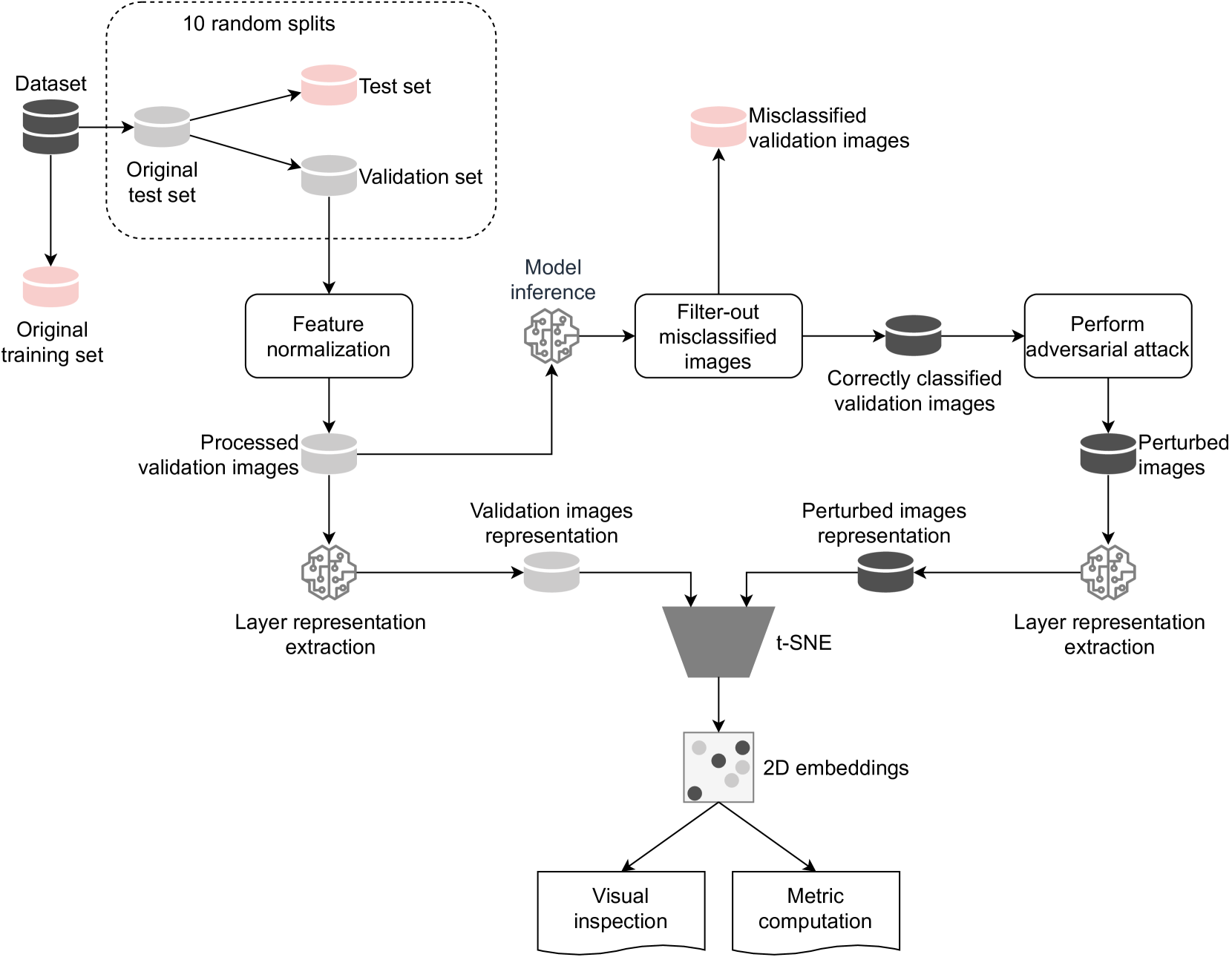
The authors then describe their experimental setup, where they train neural networks on the CIFAR-10 dataset and use adversarial training to make the networks more robust to adversarial examples. They then use t-SNE to visualize the latent space representations of the different layers in the network as the training progresses.
The key findings from the experiments are:
- The robustness of different layers in the network changes at different rates as the network is trained to be more robust. Some layers become more robust faster than others.
- The t-SNE visualizations show that the latent space representations of the different layers also change in different ways as the network becomes more robust.
- The authors hypothesize that this layerwise difference in robustness and representation change is due to the different functions that the layers perform in the network.
Overall, the paper suggests that to truly understand and improve the adversarial robustness of neural networks, it is important to look at the robustness and internal representations of the individual layers, not just the overall network performance.
Critical Analysis
The paper provides a novel and interesting perspective on the problem of adversarial robustness in neural networks. By using t-SNE to visualize the internal representations of the network, the authors are able to gain insights that would not be possible from simply looking at the overall network performance.
However, the paper does have some limitations. The experiments are conducted on a relatively simple dataset (CIFAR-10) and a small number of network architectures. It would be valuable to see if the same patterns hold true for more complex datasets and network architectures.
Additionally, the paper does not provide a clear mechanistic explanation for why the different layers in the network exhibit different robustness and representation changes. More research would be needed to fully understand the underlying reasons for these observations.
Despite these limitations, the paper makes an important contribution by highlighting the value of looking at the internal structure of neural networks when studying adversarial robustness. This could inform the development of new techniques for improving the robustness of neural networks.
Conclusion
The paper presents an interesting exploration of the relationship between adversarial robustness and latent space representations in neural networks. By using t-SNE to visualize the internal structure of the networks, the authors uncover important insights about how the robustness and representations of different layers change as the networks are trained to be more robust.
This work suggests that a holistic, layer-by-layer approach may be necessary to truly understand and improve the adversarial robustness of neural networks. The findings could have implications for the development of more robust neural network architectures and training techniques.
Overall, the paper provides a valuable contribution to the ongoing research on adversarial robustness and highlights the power of using visualization techniques like t-SNE to gain deeper insights into the inner workings of neural networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Layerwise Adversarial Robustness Through the Lens of t-SNE
In^es Valentim, Nuno Antunes, Nuno Lourenc{c}o
Adversarial examples, designed to trick Artificial Neural Networks (ANNs) into producing wrong outputs, highlight vulnerabilities in these models. Exploring these weaknesses is crucial for developing defenses, and so, we propose a method to assess the adversarial robustness of image-classifying ANNs. The t-distributed Stochastic Neighbor Embedding (t-SNE) technique is used for visual inspection, and a metric, which compares the clean and perturbed embeddings, helps pinpoint weak spots in the layers. Analyzing two ANNs on CIFAR-10, one designed by humans and another via NeuroEvolution, we found that differences between clean and perturbed representations emerge early on, in the feature extraction layers, affecting subsequent classification. The findings with our metric are supported by the visual analysis of the t-SNE maps.
Read more6/21/2024
🤿
0
t-viSNE: Interactive Assessment and Interpretation of t-SNE Projections
Angelos Chatzimparmpas, Rafael M. Martins, Andreas Kerren
t-Distributed Stochastic Neighbor Embedding (t-SNE) for the visualization of multidimensional data has proven to be a popular approach, with successful applications in a wide range of domains. Despite their usefulness, t-SNE projections can be hard to interpret or even misleading, which hurts the trustworthiness of the results. Understanding the details of t-SNE itself and the reasons behind specific patterns in its output may be a daunting task, especially for non-experts in dimensionality reduction. In this work, we present t-viSNE, an interactive tool for the visual exploration of t-SNE projections that enables analysts to inspect different aspects of their accuracy and meaning, such as the effects of hyper-parameters, distance and neighborhood preservation, densities and costs of specific neighborhoods, and the correlations between dimensions and visual patterns. We propose a coherent, accessible, and well-integrated collection of different views for the visualization of t-SNE projections. The applicability and usability of t-viSNE are demonstrated through hypothetical usage scenarios with real data sets. Finally, we present the results of a user study where the tool's effectiveness was evaluated. By bringing to light information that would normally be lost after running t-SNE, we hope to support analysts in using t-SNE and making its results better understandable.
Read more4/19/2024
🧠
0
Adversarially Robust Spiking Neural Networks Through Conversion
Ozan Ozdenizci, Robert Legenstein
Spiking neural networks (SNNs) provide an energy-efficient alternative to a variety of artificial neural network (ANN) based AI applications. As the progress in neuromorphic computing with SNNs expands their use in applications, the problem of adversarial robustness of SNNs becomes more pronounced. To the contrary of the widely explored end-to-end adversarial training based solutions, we address the limited progress in scalable robust SNN training methods by proposing an adversarially robust ANN-to-SNN conversion algorithm. Our method provides an efficient approach to embrace various computationally demanding robust learning objectives that have been proposed for ANNs. During a post-conversion robust finetuning phase, our method adversarially optimizes both layer-wise firing thresholds and synaptic connectivity weights of the SNN to maintain transferred robustness gains from the pre-trained ANN. We perform experimental evaluations in a novel setting proposed to rigorously assess the robustness of SNNs, where numerous adaptive adversarial attacks that account for the spike-based operation dynamics are considered. Results show that our approach yields a scalable state-of-the-art solution for adversarially robust deep SNNs with low-latency.
Read more4/15/2024

0
An Embedding is Worth a Thousand Noisy Labels
Francesco Di Salvo, Sebastian Doerrich, Ines Rieger, Christian Ledig
The performance of deep neural networks scales with dataset size and label quality, rendering the efficient mitigation of low-quality data annotations crucial for building robust and cost-effective systems. Existing strategies to address label noise exhibit severe limitations due to computational complexity and application dependency. In this work, we propose WANN, a Weighted Adaptive Nearest Neighbor approach that builds on self-supervised feature representations obtained from foundation models. To guide the weighted voting scheme, we introduce a reliability score, which measures the likelihood of a data label being correct. WANN outperforms reference methods, including a linear layer trained with robust loss functions, on diverse datasets of varying size and under various noise types and severities. WANN also exhibits superior generalization on imbalanced data compared to both Adaptive-NNs (ANN) and fixed k-NNs. Furthermore, the proposed weighting scheme enhances supervised dimensionality reduction under noisy labels. This yields a significant boost in classification performance with 10x and 100x smaller image embeddings, minimizing latency and storage requirements. Our approach, emphasizing efficiency and explainability, emerges as a simple, robust solution to overcome the inherent limitations of deep neural network training. The code is available at https://github.com/francescodisalvo05/wann-noisy-labels .
Read more8/27/2024