Exploring Lightweight Federated Learning for Distributed Load Forecasting
2404.03320
0
0

Abstract
Federated Learning (FL) is a distributed learning scheme that enables deep learning to be applied to sensitive data streams and applications in a privacy-preserving manner. This paper focuses on the use of FL for analyzing smart energy meter data with the aim to achieve comparable accuracy to state-of-the-art methods for load forecasting while ensuring the privacy of individual meter data. We show that with a lightweight fully connected deep neural network, we are able to achieve forecasting accuracy comparable to existing schemes, both at each meter source and at the aggregator, by utilising the FL framework. The use of lightweight models further reduces the energy and resource consumption caused by complex deep-learning models, making this approach ideally suited for deployment across resource-constrained smart meter systems. With our proposed lightweight model, we are able to achieve an overall average load forecasting RMSE of 0.17, with the model having a negligible energy overhead of 50 mWh when performing training and inference on an Arduino Uno platform.
Create account to get full access
Overview
- This paper explores the use of a lightweight federated learning (FL) approach for distributed load forecasting.
- FL allows multiple parties to collaboratively train a machine learning model without sharing their private data.
- The proposed approach aims to make FL more efficient and practical for load forecasting applications.
Plain English Explanation
The paper looks at using a special kind of machine learning called federated learning (FL) for forecasting electricity demand, also known as load forecasting. In traditional machine learning, data from different sources is gathered in one place to train a model. But in FL, the model is trained across many different locations without sharing the raw data. This helps protect people's privacy.
The researchers wanted to make FL more practical for load forecasting, which is an important task for managing electricity grids. Load forecasting predicts how much electricity will be needed in the future, so the grid can be prepared. The researchers developed a "lightweight" version of FL that is more efficient and easier to use for this application.
The key idea is to train a base model on a central server, then have individual locations fine-tune that model using their own data. This reduces the amount of data and computations needed at each location, making FL more feasible. The researchers tested this approach on real-world electricity demand data and found it performed well compared to other methods.
Technical Explanation
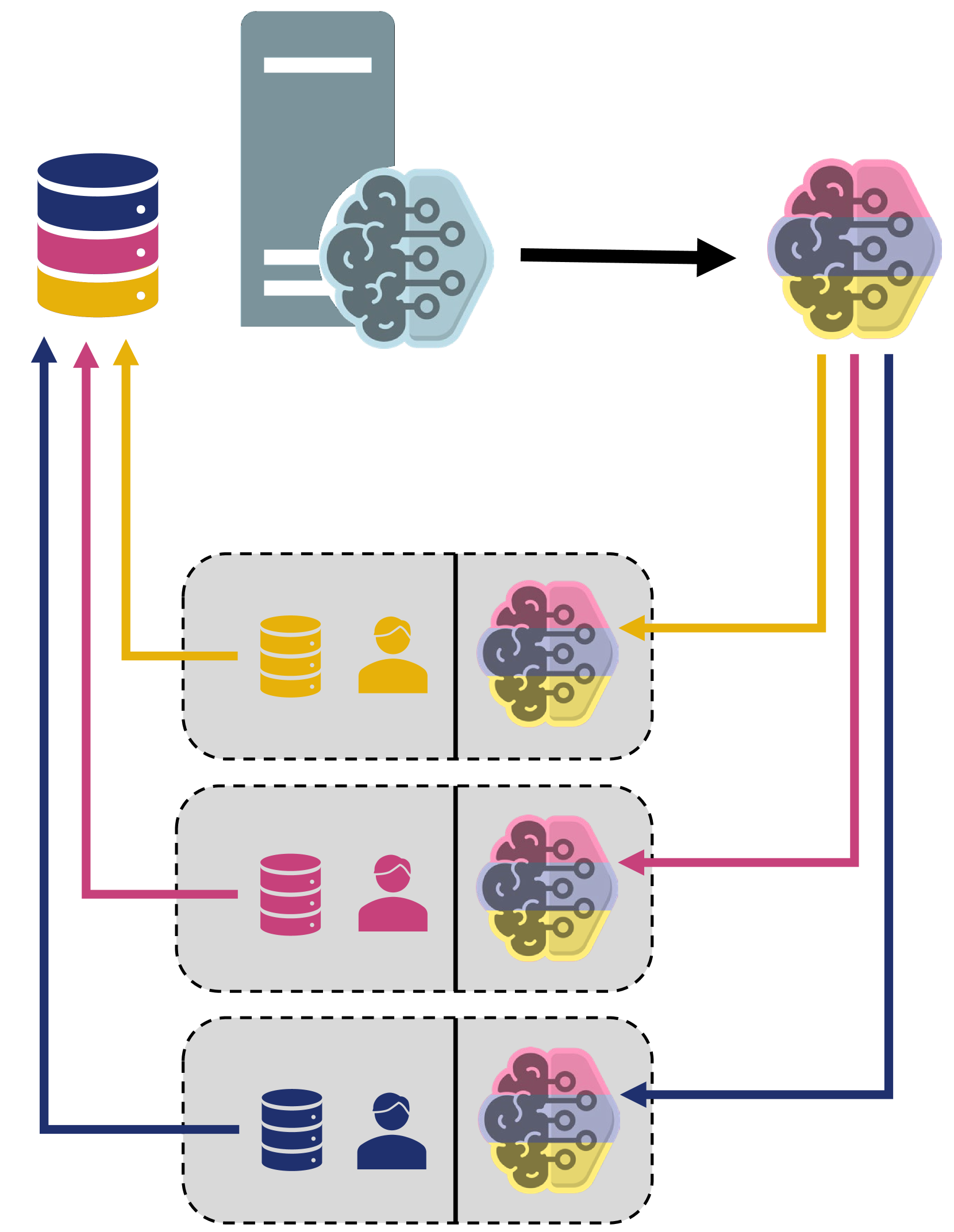
The paper proposes a lightweight federated learning (FL) framework for distributed load forecasting. In this approach, a base model is first trained on a central server using pooled data from multiple locations. Then, each individual location fine-tunes the base model using their own local data.
This two-stage training process reduces the computational and memory requirements at the local sites, making the FL approach more practical and scalable. The central server aggregates model updates from the local sites and periodically updates the base model accordingly.
The authors evaluate their approach on real-world electricity demand datasets from several locations. They compare the performance of their lightweight FL method against centralized training, as well as a traditional federated learning approach. The results show that the proposed lightweight FL framework can achieve comparable or better forecasting accuracy compared to the other methods, while significantly reducing the resource requirements at the local sites.
Critical Analysis
The paper presents a compelling approach to making federated learning more practical for distributed load forecasting applications. By adopting a two-stage training process, the authors are able to mitigate some of the key challenges of traditional FL, such as high computational and communication costs at the local sites.
However, the paper does not extensively explore the potential limitations or drawbacks of this approach. For example, it is unclear how the lightweight FL framework would perform in scenarios with highly heterogeneous data across the local sites, or how sensitive the approach is to the quality and quantity of the central server's training data.
Additionally, the authors do not discuss potential privacy or security concerns that may arise from the central server aggregating and updating the base model. While FL is designed to protect user privacy, the specifics of how this is achieved in the proposed framework are not fully addressed.
Further research could investigate the robustness and generalizability of the lightweight FL approach, as well as explore ways to enhance the privacy-preserving properties of the framework. Evaluating the approach on a wider range of load forecasting datasets and real-world deployment scenarios would also help validate the practicality and benefits of this technique.
Conclusion
The paper presents a promising lightweight federated learning approach for distributed load forecasting, which aims to make FL more efficient and practical for this important application. By reducing the computational and communication requirements at the local sites, the proposed framework has the potential to enable widespread adoption of FL-based load forecasting systems.
While the paper demonstrates the effectiveness of this approach through experiments on real-world data, further research is needed to fully understand its limitations and explore ways to enhance its robustness and privacy-preserving properties. Overall, this work represents an important step towards making federated learning a more viable and impactful tool for managing and predicting electricity demand in distributed energy systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
Addressing Heterogeneity in Federated Load Forecasting with Personalization Layers
Shourya Bose, Yu Zhang, Kibaek Kim
0
0
The advent of smart meters has enabled pervasive collection of energy consumption data for training short-term load forecasting models. In response to privacy concerns, federated learning (FL) has been proposed as a privacy-preserving approach for training, but the quality of trained models degrades as client data becomes heterogeneous. In this paper we propose the use of personalization layers for load forecasting in a general framework called PL-FL. We show that PL-FL outperforms FL and purely local training, while requiring lower communication bandwidth than FL. This is done through extensive simulations on three different datasets from the NREL ComStock repository.
4/3/2024
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024
📊
Bridging Data Barriers among Participants: Assessing the Potential of Geoenergy through Federated Learning
Weike Peng, Jiaxin Gao, Yuntian Chen, Shengwei Wang
0
0
Machine learning algorithms emerge as a promising approach in energy fields, but its practical is hindered by data barriers, stemming from high collection costs and privacy concerns. This study introduces a novel federated learning (FL) framework based on XGBoost models, enabling safe collaborative modeling with accessible yet concealed data from multiple parties. Hyperparameter tuning of the models is achieved through Bayesian Optimization. To ascertain the merits of the proposed FL-XGBoost method, a comparative analysis is conducted between separate and centralized models to address a classical binary classification problem in geoenergy sector. The results reveal that the proposed FL framework strikes an optimal balance between privacy and accuracy. FL models demonstrate superior accuracy and generalization capabilities compared to separate models, particularly for participants with limited data or low correlation features and offers significant privacy benefits compared to centralized model. The aggregated optimization approach within the FL agreement proves effective in tuning hyperparameters. This study opens new avenues for assessing unconventional reservoirs through collaborative and privacy-preserving FL techniques.
4/30/2024

Federated Bayesian Deep Learning: The Application of Statistical Aggregation Methods to Bayesian Models
John Fischer, Marko Orescanin, Justin Loomis, Patrick McClure
0
0
Federated learning (FL) is an approach to training machine learning models that takes advantage of multiple distributed datasets while maintaining data privacy and reducing communication costs associated with sharing local datasets. Aggregation strategies have been developed to pool or fuse the weights and biases of distributed deterministic models; however, modern deterministic deep learning (DL) models are often poorly calibrated and lack the ability to communicate a measure of epistemic uncertainty in prediction, which is desirable for remote sensing platforms and safety-critical applications. Conversely, Bayesian DL models are often well calibrated and capable of quantifying and communicating a measure of epistemic uncertainty along with a competitive prediction accuracy. Unfortunately, because the weights and biases in Bayesian DL models are defined by a probability distribution, simple application of the aggregation methods associated with FL schemes for deterministic models is either impossible or results in sub-optimal performance. In this work, we use independent and identically distributed (IID) and non-IID partitions of the CIFAR-10 dataset and a fully variational ResNet-20 architecture to analyze six different aggregation strategies for Bayesian DL models. Additionally, we analyze the traditional federated averaging approach applied to an approximate Bayesian Monte Carlo dropout model as a lightweight alternative to more complex variational inference methods in FL. We show that aggregation strategy is a key hyperparameter in the design of a Bayesian FL system with downstream effects on accuracy, calibration, uncertainty quantification, training stability, and client compute requirements.
4/8/2024