Federated Bayesian Deep Learning: The Application of Statistical Aggregation Methods to Bayesian Models
2403.15263
0
0

Abstract
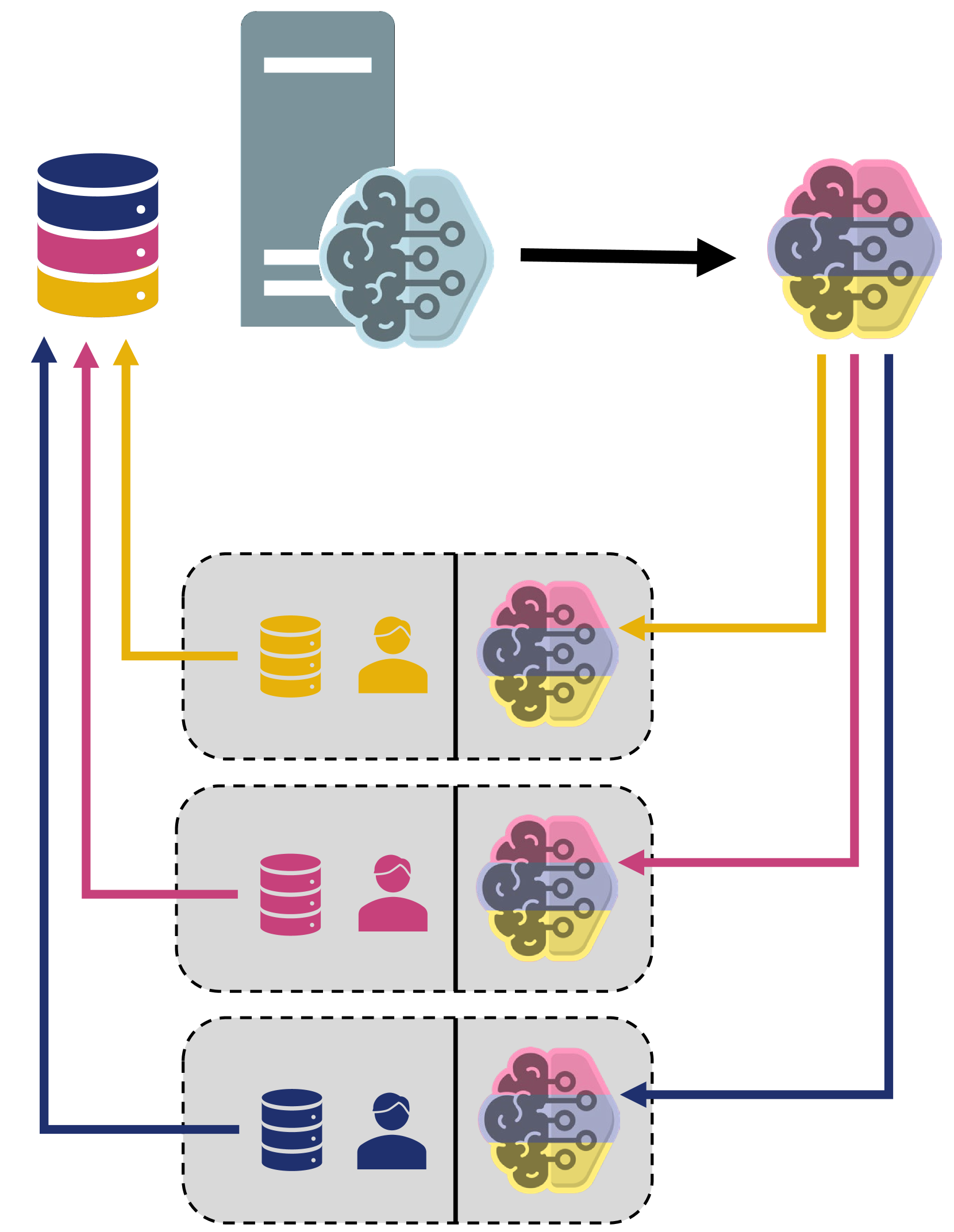
Federated learning (FL) is an approach to training machine learning models that takes advantage of multiple distributed datasets while maintaining data privacy and reducing communication costs associated with sharing local datasets. Aggregation strategies have been developed to pool or fuse the weights and biases of distributed deterministic models; however, modern deterministic deep learning (DL) models are often poorly calibrated and lack the ability to communicate a measure of epistemic uncertainty in prediction, which is desirable for remote sensing platforms and safety-critical applications. Conversely, Bayesian DL models are often well calibrated and capable of quantifying and communicating a measure of epistemic uncertainty along with a competitive prediction accuracy. Unfortunately, because the weights and biases in Bayesian DL models are defined by a probability distribution, simple application of the aggregation methods associated with FL schemes for deterministic models is either impossible or results in sub-optimal performance. In this work, we use independent and identically distributed (IID) and non-IID partitions of the CIFAR-10 dataset and a fully variational ResNet-20 architecture to analyze six different aggregation strategies for Bayesian DL models. Additionally, we analyze the traditional federated averaging approach applied to an approximate Bayesian Monte Carlo dropout model as a lightweight alternative to more complex variational inference methods in FL. We show that aggregation strategy is a key hyperparameter in the design of a Bayesian FL system with downstream effects on accuracy, calibration, uncertainty quantification, training stability, and client compute requirements.
Create account to get full access
Overview
- This paper introduces Federated Bayesian Deep Learning (FBDL), a framework that combines Bayesian deep learning with federated learning techniques to enable distributed training of Bayesian models.
- The key innovations include methods for statistical aggregation of local Bayesian models and a novel algorithm for federated Bayesian optimization.
- The paper demonstrates the effectiveness of FBDL on several real-world applications, including distributed load forecasting, federated reinforcement learning, and personalized recommendation systems.
Plain English Explanation
Federated learning is a technique that allows multiple devices or organizations to train a machine learning model together, without sharing their private data. This approach can help address privacy concerns and make it easier to train models on distributed data.
In this paper, the researchers extend federated learning to the domain of Bayesian deep learning. Bayesian models are a type of machine learning that can quantify uncertainty, which is important for many real-world applications. However, training Bayesian models is computationally intensive, especially when the data is spread across multiple devices or organizations.
The researchers' Federated Bayesian Deep Learning (FBDL) framework allows Bayesian deep learning models to be trained in a federated setting. This involves developing new methods for aggregating the local Bayesian models trained on each device, as well as a novel algorithm for federated Bayesian optimization, which is used to tune the model hyperparameters.
The researchers demonstrate the effectiveness of FBDL on several real-world problems, including distributed load forecasting, federated reinforcement learning, and personalized recommendation systems. These applications show how FBDL can leverage the strengths of Bayesian modeling while overcoming the challenges of distributed data and computation.
Technical Explanation
The key technical contributions of this paper are:
-
Statistical Aggregation of Local Bayesian Models: The researchers develop new methods for aggregating the local Bayesian models trained on each device in the federated setting. This includes techniques for averaging the model parameters as well as the model uncertainty estimates.
-
Federated Bayesian Optimization: The researchers propose a novel algorithm for performing Bayesian optimization in the federated setting. This is used to tune the hyperparameters of the Bayesian deep learning models, which is critical for their performance.
-
Federated Bayesian Deep Learning Framework: The researchers integrate the statistical aggregation and federated Bayesian optimization techniques into a unified FBDL framework. This framework can be applied to a variety of Bayesian deep learning problems in a federated setting.
The paper demonstrates the effectiveness of FBDL on several real-world applications. For example, in the distributed load forecasting task, FBDL is used to train Bayesian neural networks on data from multiple power substations, without requiring the substations to share their private data. Similarly, in the federated reinforcement learning and personalized recommendation tasks, FBDL enables the training of Bayesian models on data distributed across multiple devices or organizations.
Critical Analysis
The researchers have made a compelling case for the benefits of FBDL, particularly in addressing the challenges of training Bayesian models on distributed data. However, the paper also acknowledges several limitations and areas for future work:
-
Communication Efficiency: The federated learning approach can still incur significant communication overhead, especially for the Bayesian optimization step. Further research is needed to optimize the communication protocols and reduce the bandwidth requirements.
-
Heterogeneous Devices: The current FBDL framework assumes that all the participating devices have similar computational capabilities. Extending the approach to handle heterogeneous devices with varying resources would be an important next step.
-
Scalability: The paper demonstrates FBDL on relatively small-scale problems. Scaling the framework to large-scale, [real-world applications with high-dimensional data and many clients would be a valuable contribution.
Overall, the Federated Bayesian Deep Learning framework presented in this paper is a promising step towards enabling the benefits of Bayesian modeling in distributed, privacy-preserving machine learning settings. The specific techniques and the demonstrated applications provide a solid foundation for further research and development in this area.
Conclusion
This paper introduces Federated Bayesian Deep Learning (FBDL), a framework that combines Bayesian deep learning with federated learning techniques. FBDL allows Bayesian models to be trained on distributed data, without requiring the participating devices or organizations to share their private information.
The key innovations in FBDL include new methods for statistically aggregating local Bayesian models and a novel algorithm for performing federated Bayesian optimization. The researchers demonstrate the effectiveness of FBDL on several real-world applications, including distributed load forecasting, federated reinforcement learning, and personalized recommendation systems.
While the paper highlights the considerable potential of FBDL, it also acknowledges several important limitations and areas for future work, such as improving communication efficiency, handling heterogeneous devices, and scaling the framework to larger, more complex problems. Addressing these challenges will be crucial for realizing the full potential of Bayesian modeling in federated learning settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024
Optimisation of federated learning settings under statistical heterogeneity variations
Basem Suleiman, Muhammad Johan Alibasa, Rizka Widyarini Purwanto, Lewis Jeffries, Ali Anaissi, Jacky Song
0
0
Federated Learning (FL) enables local devices to collaboratively learn a shared predictive model by only periodically sharing model parameters with a central aggregator. However, FL can be disadvantaged by statistical heterogeneity produced by the diversity in each local devices data distribution, which creates different levels of Independent and Identically Distributed (IID) data. Furthermore, this can be more complex when optimising different combinations of FL parameters and choosing optimal aggregation. In this paper, we present an empirical analysis of different FL training parameters and aggregators over various levels of statistical heterogeneity on three datasets. We propose a systematic data partition strategy to simulate different levels of statistical heterogeneity and a metric to measure the level of IID. Additionally, we empirically identify the best FL model and key parameters for datasets of different characteristics. On the basis of these, we present recommended guidelines for FL parameters and aggregators to optimise model performance under different levels of IID and with different datasets
6/11/2024
🔮
FedAgg: Adaptive Federated Learning with Aggregated Gradients
Wenhao Yuan, Xuehe Wang
0
0
Federated Learning (FL) has emerged as a pivotal paradigm within distributed model training, facilitating collaboration among multiple devices to refine a shared model, harnessing their respective datasets as orchestrated by a central server, while ensuring the localization of private data. Nonetheless, the non-independent-and-identically-distributed (Non-IID) data generated on heterogeneous clients and the incessant information exchange among participants may markedly impede training efficacy and retard the convergence rate. In this paper, we refine the conventional stochastic gradient descent (SGD) methodology by introducing aggregated gradients at each local training epoch and propose an adaptive learning rate iterative algorithm that concerns the divergence between local and average parameters. To surmount the obstacle that acquiring other clients' local information, we introduce the mean-field approach by leveraging two mean-field terms to approximately estimate the average local parameters and gradients over time in a manner that precludes the need for local information exchange among clients and design the decentralized adaptive learning rate for each client. Through meticulous theoretical analysis, we provide a robust convergence guarantee for our proposed algorithm and ensure its wide applicability. Our numerical experiments substantiate the superiority of our framework in comparison with existing state-of-the-art FL strategies for enhancing model performance and accelerating convergence rate under IID and Non-IID data distributions.
4/15/2024
📊
StatAvg: Mitigating Data Heterogeneity in Federated Learning for Intrusion Detection Systems
Pavlos S. Bouzinis, Panagiotis Radoglou-Grammatikis, Ioannis Makris, Thomas Lagkas, Vasileios Argyriou, Georgios Th. Papadopoulos, Panagiotis Sarigiannidis, George K. Karagiannidis
0
0
Federated learning (FL) is a decentralized learning technique that enables participating devices to collaboratively build a shared Machine Leaning (ML) or Deep Learning (DL) model without revealing their raw data to a third party. Due to its privacy-preserving nature, FL has sparked widespread attention for building Intrusion Detection Systems (IDS) within the realm of cybersecurity. However, the data heterogeneity across participating domains and entities presents significant challenges for the reliable implementation of an FL-based IDS. In this paper, we propose an effective method called Statistical Averaging (StatAvg) to alleviate non-independently and identically (non-iid) distributed features across local clients' data in FL. In particular, StatAvg allows the FL clients to share their individual data statistics with the server, which then aggregates this information to produce global statistics. The latter are shared with the clients and used for universal data normalisation. It is worth mentioning that StatAvg can seamlessly integrate with any FL aggregation strategy, as it occurs before the actual FL training process. The proposed method is evaluated against baseline approaches using datasets for network and host Artificial Intelligence (AI)-powered IDS. The experimental results demonstrate the efficiency of StatAvg in mitigating non-iid feature distributions across the FL clients compared to the baseline methods.
5/24/2024