Exploring Multi-view Pixel Contrast for General and Robust Image Forgery Localization

0
Sign in to get full access
Overview
- This paper explores a novel approach to image forgery localization using multi-view pixel contrast.
- The proposed method aims to provide a general and robust solution for detecting and localizing various types of image forgeries.
- The key ideas involve leveraging multi-view information and contrastive learning to enhance the model's ability to distinguish authentic and forged regions in an image.
Plain English Explanation
Exploring Multi-view Pixel Contrast for General and Robust Image Forgery Localization is a research paper that introduces a new technique for identifying and locating image forgeries. Image forgeries occur when parts of an image are manipulated or replaced, making the image deceptive or misleading.
The researchers developed a method that uses multiple viewpoints or perspectives of the same image to help the model better recognize authentic versus forged regions. By comparing the contrast, or differences, between pixels across these multiple views, the model can learn to distinguish genuine image content from manipulated areas.
This approach aims to be more general and robust, meaning it can detect a wide variety of forgery types and is less affected by factors like image resolution or compression. The researchers believe this technique could be useful for applications like media authentication, where identifying manipulated images is crucial.
Technical Explanation
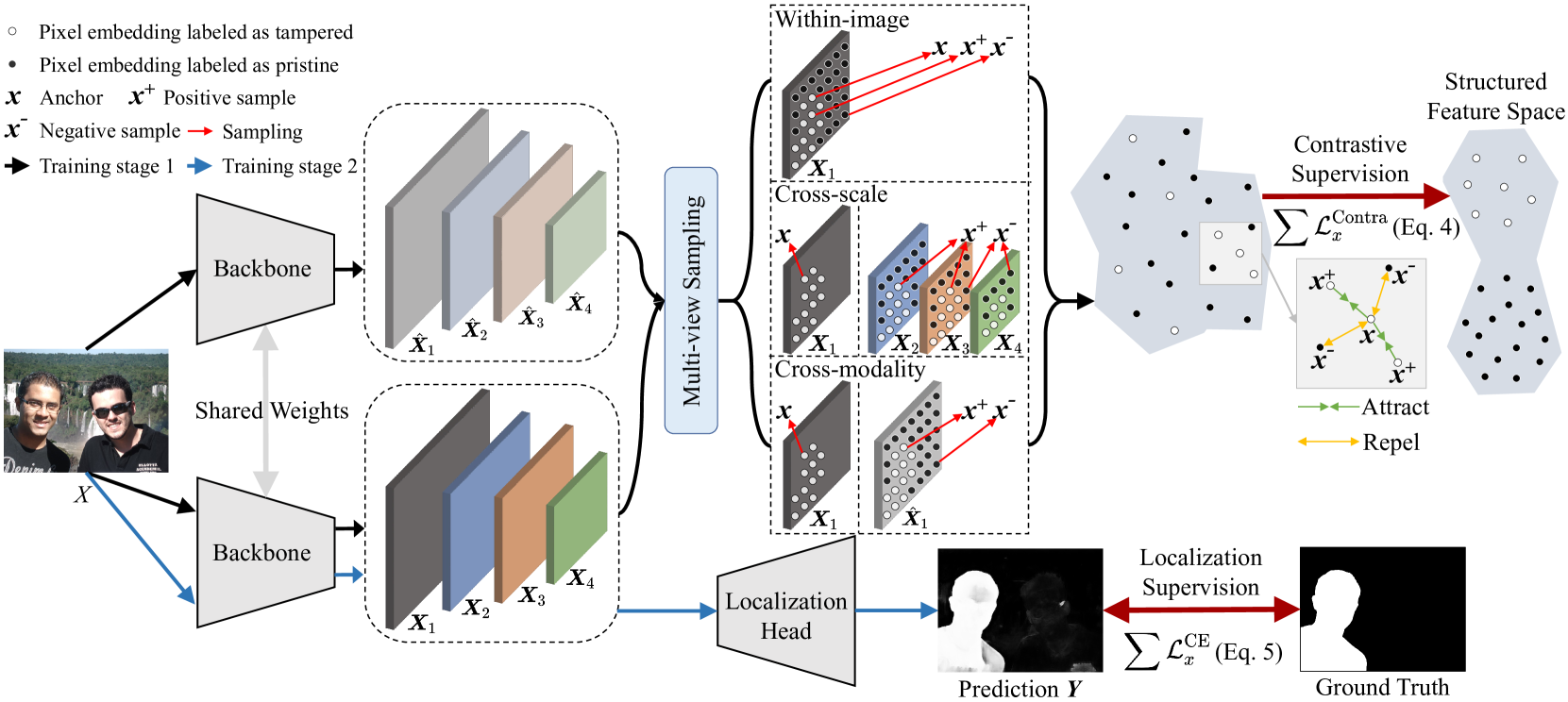
The paper proposes a multi-level asymmetric contrastive learning approach for image forgery localization. The key idea is to leverage multiple views of the same image, such as different image scales or rotations, to learn robust features for distinguishing authentic and forged regions.
The model architecture consists of a pixel-wise contrastive distillation module that compares pixel-level features across the multiple views. This allows the model to capture subtle differences that may indicate image manipulation. Additionally, a pyramid pixel context adaption network is used to incorporate multi-scale contextual information, further enhancing the model's ability to accurately localize forgeries.
The researchers evaluated their approach on several benchmarks for image forgery detection and localization, demonstrating state-of-the-art performance. They found the multi-view contrast learning was particularly effective at handling diverse forgery types and maintaining robustness to factors like image resolution and compression.
Critical Analysis
The paper presents a well-designed and thorough study on the application of multi-view contrastive learning for image forgery localization. The researchers leveraged several established techniques, such as pixel-wise contrastive distillation and pyramid pixel context adaption, to build a robust and effective solution.
One potential limitation discussed in the paper is the reliance on carefully curated training data, as the model's performance may degrade when presented with real-world forgeries that differ significantly from the examples it was trained on. Additionally, the computational complexity of the multi-view approach could be a concern for deployment in some applications.
Further research could explore techniques to improve the model's generalization to unseen forgery types, potentially through the use of weakly supervised learning or other advanced data augmentation methods. Investigating more efficient architectural designs could also help address the computational challenges.
Conclusion
This paper presents a novel approach to image forgery localization that leverages multi-view pixel contrast learning. The key innovation is the use of multiple viewpoints of an image to enhance the model's ability to distinguish authentic and forged regions, resulting in a more general and robust solution.
The researchers demonstrated state-of-the-art performance on various benchmarks, showcasing the potential of this technique for applications such as media authentication and digital forensics. While the approach has some limitations, the insights and methodologies discussed in this work could inspire further advancements in the field of image manipulation detection and localization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Multi-view Pixel Contrast for General and Robust Image Forgery Localization
Zijie Lou, Gang Cao, Kun Guo, Haochen Zhu, Lifang Yu
Image forgery localization, which aims to segment tampered regions in an image, is a fundamental yet challenging digital forensic task. While some deep learning-based forensic methods have achieved impressive results, they directly learn pixel-to-label mappings without fully exploiting the relationship between pixels in the feature space. To address such deficiency, we propose a Multi-view Pixel-wise Contrastive algorithm (MPC) for image forgery localization. Specifically, we first pre-train the backbone network with the supervised contrastive loss to model pixel relationships from the perspectives of within-image, cross-scale and cross-modality. That is aimed at increasing intra-class compactness and inter-class separability. Then the localization head is fine-tuned using the cross-entropy loss, resulting in a better pixel localizer. The MPC is trained on three different scale training datasets to make a comprehensive and fair comparison with existing image forgery localization algorithms. Extensive experiments on the small, medium and large scale training datasets show that the proposed MPC achieves higher generalization performance and robustness against post-processing than the state-of-the-arts. Code will be available at https://github.com/multimediaFor/MPC.
Read more6/21/2024
🌐
0
Multi-spectral Class Center Network for Face Manipulation Detection and Localization
Changtao Miao, Qi Chu, Zhentao Tan, Zhenchao Jin, Tao Gong, Wanyi Zhuang, Yue Wu, Bin Liu, Honggang Hu, Nenghai Yu
As deepfake content proliferates online, advancing face manipulation forensics has become crucial. To combat this emerging threat, previous methods mainly focus on studying how to distinguish authentic and manipulated face images. Although impressive, image-level classification lacks explainability and is limited to specific application scenarios, spurring recent research on pixel-level prediction for face manipulation forensics. However, existing forgery localization methods suffer from exploring frequency-based forgery traces in the localization network. In this paper, we observe that multi-frequency spectrum information is effective for identifying tampered regions. To this end, a novel Multi-Spectral Class Center Network (MSCCNet) is proposed for face manipulation detection and localization. Specifically, we design a Multi-Spectral Class Center (MSCC) module to learn more generalizable and multi-frequency features. Based on the features of different frequency bands, the MSCC module collects multi-spectral class centers and computes pixel-to-class relations. Applying multi-spectral class-level representations suppresses the semantic information of the visual concepts which is insensitive to manipulated regions of forgery images. Furthermore, we propose a Multi-level Features Aggregation (MFA) module to employ more low-level forgery artifacts and structural textures. Meanwhile, we conduct a comprehensive localization benchmark based on pixel-level FF++ and Dolos datasets. Experimental results quantitatively and qualitatively demonstrate the effectiveness and superiority of the proposed MSCCNet. We expect this work to inspire more studies on pixel-level face manipulation localization. The codes are available (https://github.com/miaoct/MSCCNet).
Read more7/16/2024
👀
0
New!Reducing Semantic Ambiguity In Domain Adaptive Semantic Segmentation Via Probabilistic Prototypical Pixel Contrast
Xiaoke Hao, Shiyu Liu, Chuanbo Feng, Ye Zhu
Domain adaptation aims to reduce the model degradation on the target domain caused by the domain shift between the source and target domains. Although encouraging performance has been achieved by combining cognitive learning with the self-training paradigm, they suffer from ambiguous scenarios caused by scale, illumination, or overlapping when deploying deterministic embedding. To address these issues, we propose probabilistic proto-typical pixel contrast (PPPC), a universal adaptation framework that models each pixel embedding as a probability via multivariate Gaussian distribution to fully exploit the uncertainty within them, eventually improving the representation quality of the model. In addition, we derive prototypes from probability estimation posterior probability estimation which helps to push the decision boundary away from the ambiguity points. Moreover, we employ an efficient method to compute similarity between distributions, eliminating the need for sampling and reparameterization, thereby significantly reducing computational overhead. Further, we dynamically select the ambiguous crops at the image level to enlarge the number of boundary points involved in contrastive learning, which benefits the establishment of precise distributions for each category. Extensive experimentation demonstrates that PPPC not only helps to address ambiguity at the pixel level, yielding discriminative representations but also achieves significant improvements in both synthetic-to-real and day-to-night adaptation tasks. It surpasses the previous state-of-the-art (SOTA) by +5.2% mIoU in the most challenging daytime-to-nighttime adaptation scenario, exhibiting stronger generalization on other unseen datasets. The code and models are available at https://github.com/DarlingInTheSV/Probabilistic-Prototypical-Pixel-Contrast.
Read more9/30/2024
0
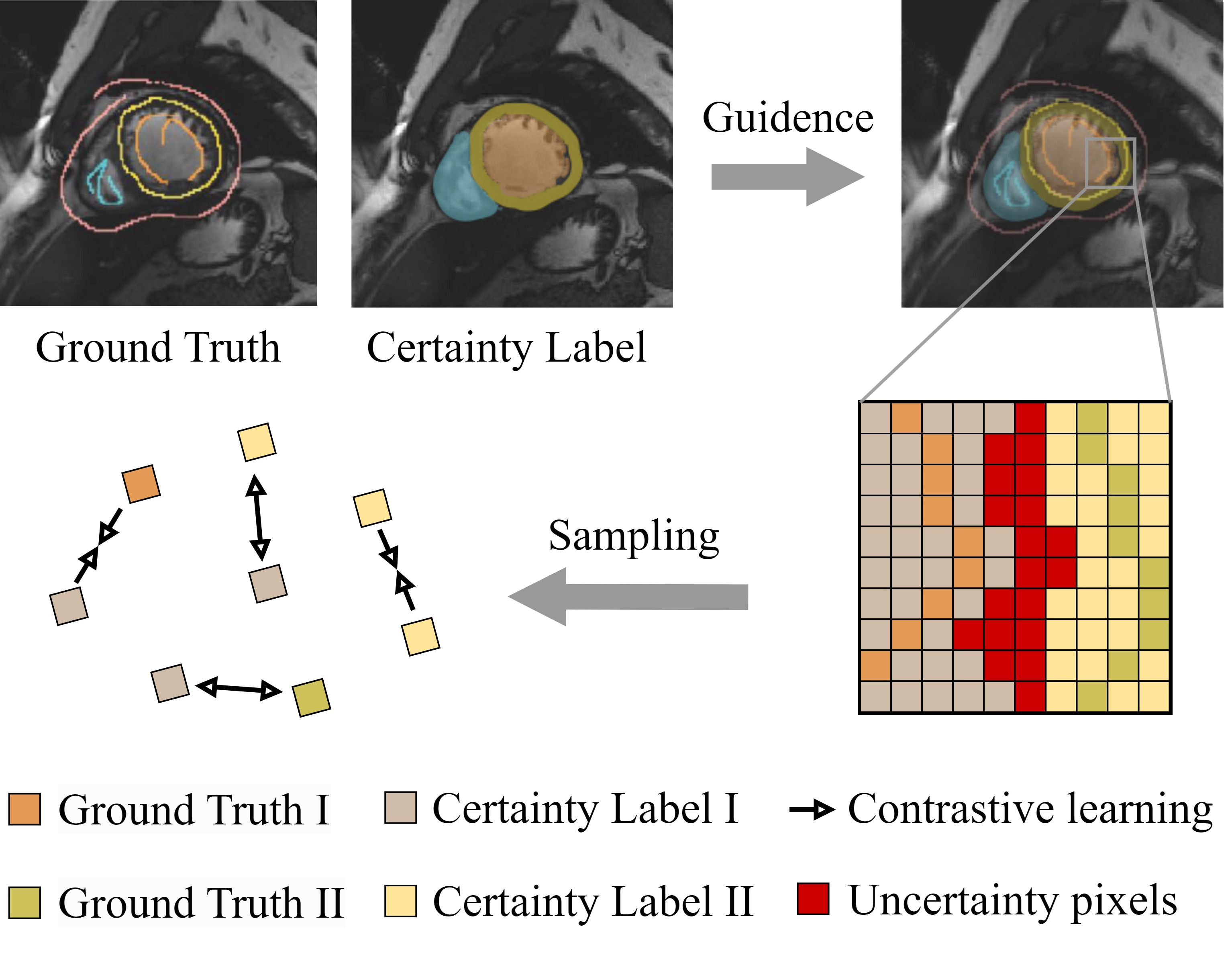
PCLMix: Weakly Supervised Medical Image Segmentation via Pixel-Level Contrastive Learning and Dynamic Mix Augmentation
Yu Lei, Haolun Luo, Lituan Wang, Zhenwei Zhang, Lei Zhang
In weakly supervised medical image segmentation, the absence of structural priors and the discreteness of class feature distribution present a challenge, i.e., how to accurately propagate supervision signals from local to global regions without excessively spreading them to other irrelevant regions? To address this, we propose a novel weakly supervised medical image segmentation framework named PCLMix, comprising dynamic mix augmentation, pixel-level contrastive learning, and consistency regularization strategies. Specifically, PCLMix is built upon a heterogeneous dual-decoder backbone, addressing the absence of structural priors through a strategy of dynamic mix augmentation during training. To handle the discrete distribution of class features, PCLMix incorporates pixel-level contrastive learning based on prediction uncertainty, effectively enhancing the model's ability to differentiate inter-class pixel differences and intra-class consistency. Furthermore, to reinforce segmentation consistency and robustness, PCLMix employs an auxiliary decoder for dual consistency regularization. In the inference phase, the auxiliary decoder will be dropped and no computation complexity is increased. Extensive experiments on the ACDC dataset demonstrate that PCLMix appropriately propagates local supervision signals to the global scale, further narrowing the gap between weakly supervised and fully supervised segmentation methods. Our code is available at https://github.com/Torpedo2648/PCLMix.
Read more5/21/2024