Exploring Scaling Trends in LLM Robustness

0

Sign in to get full access
Overview
- Explores scaling trends in the robustness of large language models (LLMs)
- Investigates how model size and architecture affect adversarial robustness
- Presents experimental findings on the relationship between model scale and robustness
Plain English Explanation
This research paper examines how the size and structure of large language models (LLMs) impact their ability to withstand adversarial attacks. Adversarial attacks are intentional attempts to trick a model into making mistakes, which is an important issue for the reliability and safety of AI systems.
The researchers conducted experiments to understand how the scale, or size, of LLMs affects their robustness, or resilience, to these adversarial attacks. They looked at how the model architecture, or internal design, also plays a role in determining the model's robustness.
The key findings from this research provide insights into the trade-offs between model scale and robustness. The results suggest that as LLMs become larger and more powerful, they may not necessarily become more robust to adversarial attacks. In fact, the researchers found that there can be an "inverse scaling" effect, where bigger models are actually less robust than smaller ones.
These insights are important for developers and researchers working on large AI models, as they need to carefully consider model size and architecture when optimizing for robustness and reliability, rather than just focusing on increasing model scale.
Technical Explanation
The paper examines how the scaling of large language models (LLMs) impacts their adversarial robustness. The researchers conducted experiments to investigate the relationship between model size, architecture, and resilience to adversarial attacks.
They tested various LLM architectures, including transformer-based models and recurrent neural networks, across a range of model sizes. The models were evaluated on their performance on standard language tasks, as well as their ability to withstand adversarial perturbations.
The results showed that, contrary to common assumptions, larger LLMs are not necessarily more robust to adversarial attacks. In fact, the researchers observed an "inverse scaling" effect, where larger models exhibited lower adversarial robustness compared to their smaller counterparts.
The paper also explored how architectural choices, such as the use of skip connections or different attention mechanisms, can impact a model's robustness. These findings suggest that developers need to carefully consider model design and not solely focus on increasing scale when optimizing for adversarial robustness.
Critical Analysis
The paper provides valuable insights into the complex relationship between LLM scale, architecture, and robustness. However, the authors acknowledge several limitations and areas for future research.
One key limitation is the relatively narrow set of adversarial attack types and datasets used in the experiments. The researchers note that exploring a wider range of attack methods and evaluation scenarios could yield additional insights.
Additionally, the paper does not delve deeply into the underlying mechanisms that drive the observed inverse scaling effect. Further research is needed to better understand the specific architectural and training factors that contribute to this phenomenon.
The authors also highlight the importance of considering potential biases and privacy risks when scaling up LLMs, as these issues can have significant implications for the real-world deployment of these models.
Overall, this research provides a valuable starting point for understanding the nuances of LLM robustness and the need to holistically consider model scale, architecture, and other potential risks when developing large-scale AI systems.
Conclusion
This paper presents an important exploration of the scaling trends in the adversarial robustness of large language models (LLMs). The key findings challenge the assumption that larger models are inherently more robust, and instead reveal an "inverse scaling" effect where bigger models can be less resilient to adversarial attacks.
These insights have significant implications for the development and deployment of large-scale AI systems, as they suggest that model size and architecture need to be carefully balanced with considerations of robustness and reliability. The research also highlights the need for further investigation into the underlying factors that influence LLM robustness, as well as the broader implications of scaling up these powerful models.
By understanding the complex relationship between model scale, architecture, and adversarial robustness, researchers and developers can work towards building more reliable and trustworthy AI systems that can withstand real-world challenges and threats.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Scaling Trends in LLM Robustness
Nikolaus Howe, Micha{l} Zajac, Ian McKenzie, Oskar Hollinsworth, Tom Tseng, Pierre-Luc Bacon, Adam Gleave
Language model capabilities predictably improve from scaling a model's size and training data. Motivated by this, increasingly large language models have been trained, yielding an array of impressive capabilities. Yet these models are vulnerable to adversarial prompts, such as jailbreaks that hijack models to perform undesired behaviors, posing a significant risk of misuse. Prior work indicates that computer vision models become more robust with model and data scaling, raising the question: does language model robustness also improve with scale? We study this question empirically, finding that larger models respond substantially better to adversarial training, but there is little to no benefit from model scale in the absence of explicit defenses.
Read more7/29/2024
0
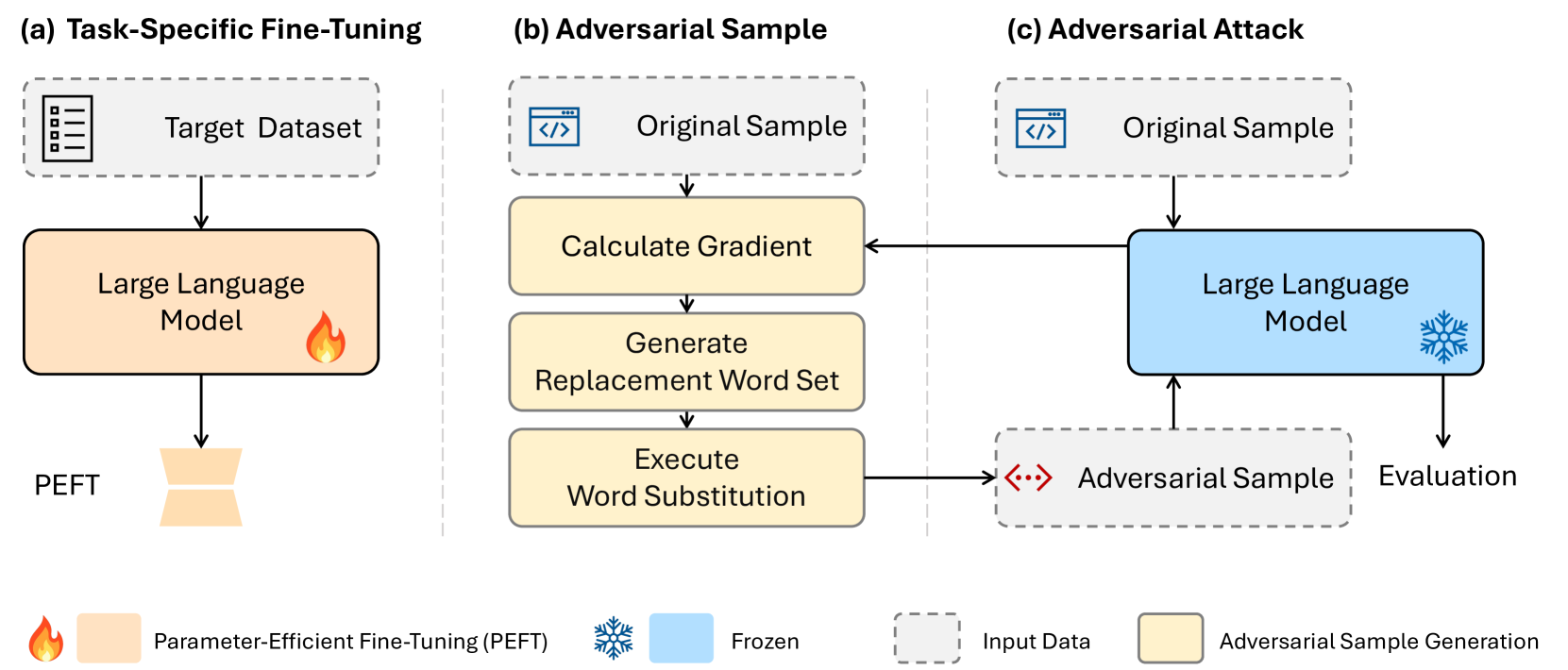
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
Read more9/16/2024
0
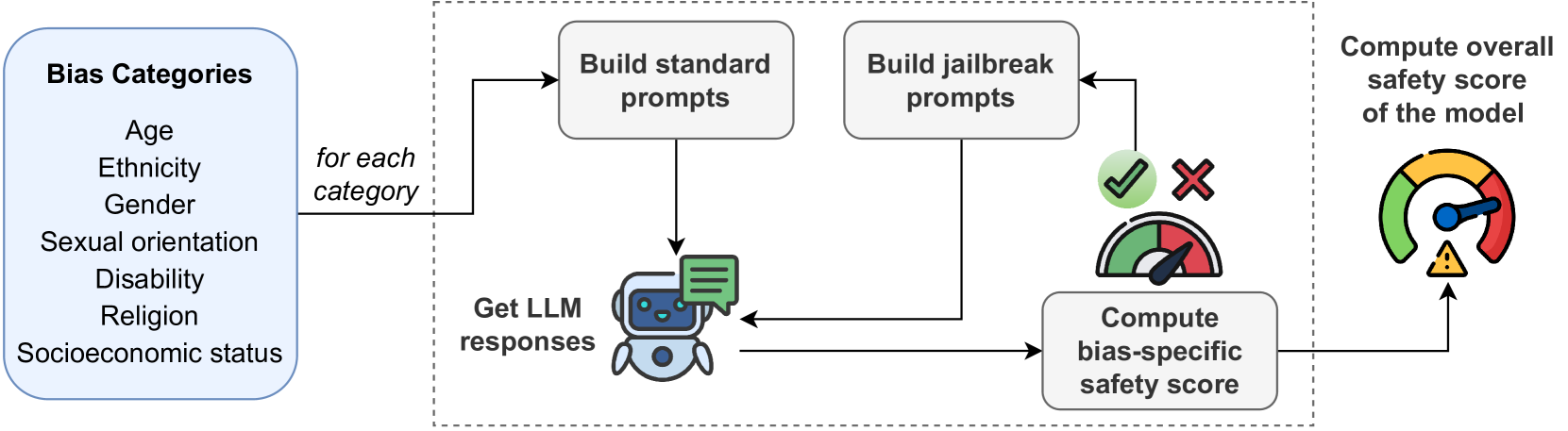
Are Large Language Models Really Bias-Free? Jailbreak Prompts for Assessing Adversarial Robustness to Bias Elicitation
Riccardo Cantini, Giada Cosenza, Alessio Orsino, Domenico Talia
Large Language Models (LLMs) have revolutionized artificial intelligence, demonstrating remarkable computational power and linguistic capabilities. However, these models are inherently prone to various biases stemming from their training data. These include selection, linguistic, and confirmation biases, along with common stereotypes related to gender, ethnicity, sexual orientation, religion, socioeconomic status, disability, and age. This study explores the presence of these biases within the responses given by the most recent LLMs, analyzing the impact on their fairness and reliability. We also investigate how known prompt engineering techniques can be exploited to effectively reveal hidden biases of LLMs, testing their adversarial robustness against jailbreak prompts specially crafted for bias elicitation. Extensive experiments are conducted using the most widespread LLMs at different scales, confirming that LLMs can still be manipulated to produce biased or inappropriate responses, despite their advanced capabilities and sophisticated alignment processes. Our findings underscore the importance of enhancing mitigation techniques to address these safety issues, toward a more sustainable and inclusive artificial intelligence.
Read more7/12/2024
0
Inverse Scaling: When Bigger Isn't Better
Ian R. McKenzie, Alexander Lyzhov, Michael Pieler, Alicia Parrish, Aaron Mueller, Ameya Prabhu, Euan McLean, Aaron Kirtland, Alexis Ross, Alisa Liu, Andrew Gritsevskiy, Daniel Wurgaft, Derik Kauffman, Gabriel Recchia, Jiacheng Liu, Joe Cavanagh, Max Weiss, Sicong Huang, The Floating Droid, Tom Tseng, Tomasz Korbak, Xudong Shen, Yuhui Zhang, Zhengping Zhou, Najoung Kim, Samuel R. Bowman, Ethan Perez
Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
Read more5/14/2024