Exploring Selective Layer Fine-Tuning in Federated Learning

0
Sign in to get full access
Overview
- Explores the idea of selective layer fine-tuning in federated learning, where only certain layers of a model are updated during the federated training process.
- Aims to improve the performance of federated learning by customizing the fine-tuning process for each client.
- Proposes a framework for selecting the layers to fine-tune based on the unique characteristics of each client's data.
Plain English Explanation
Federated learning is a way of training machine learning models without sharing the raw data from different devices or users. Instead, the model is trained on each device, and the updates are sent to a central server to create a combined, improved model.
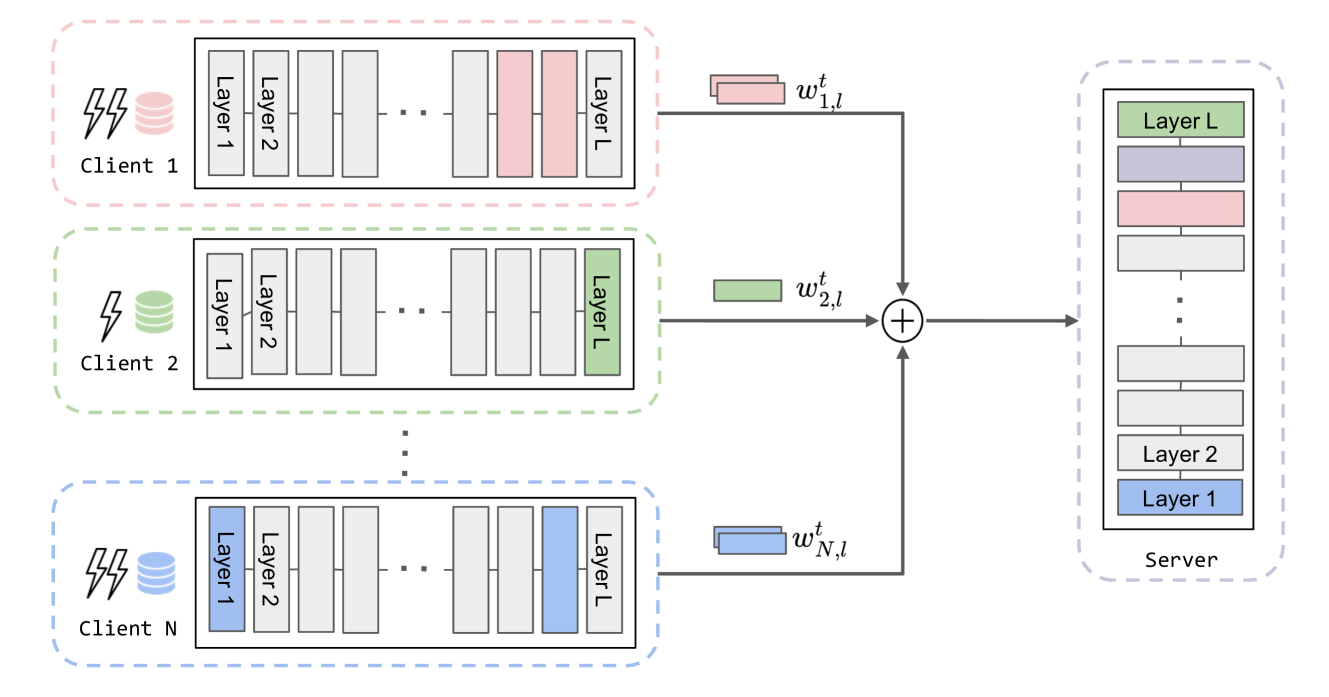
This paper looks at a specific approach called "selective layer fine-tuning" in federated learning. The idea is that instead of fine-tuning the entire model on each device, you can just fine-tune certain layers of the model. This can be more efficient and lead to better performance.
The key insight is that different devices or users may have different kinds of data, so the optimal layers to fine-tune may vary. The paper proposes a framework to automatically select the best layers to fine-tune for each client, based on the characteristics of their data. This "customized" fine-tuning process can improve the overall performance of the federated learning system.
Technical Explanation
The paper formulates the problem of selective layer fine-tuning in federated learning as an optimization problem. The goal is to find the optimal set of layers to fine-tune for each client, given their local data characteristics.
The proposed framework consists of three main components:
- Layer Importance Estimation: Analyzes the importance of each layer in the model for a given client's data, using techniques like layer-wise relevance propagation.
- Layer Selection: Selects the optimal set of layers to fine-tune for each client, based on the layer importance estimates and a budget constraint.
- Federated Fine-Tuning: Performs the federated fine-tuning process, updating only the selected layers for each client.
The authors evaluate their approach on various benchmark datasets and show that selective layer fine-tuning can outperform traditional federated learning and other fine-tuning strategies, especially when clients have heterogeneous data distributions.
Critical Analysis
The paper provides a solid theoretical foundation and experimental validation for the selective layer fine-tuning approach in federated learning. However, there are a few potential limitations and areas for further research:
- The layer importance estimation method relies on layer-wise relevance propagation, which may not capture all the nuances of how different layers contribute to the model's performance for a given client. Alternative layer importance estimation techniques could be explored.
- The paper assumes that the layer selection process can be formulated as a constrained optimization problem. In practice, this optimization may be computationally intensive, especially for large models and many clients. More efficient layer selection algorithms could be investigated.
- The experiments are conducted on relatively simple benchmark datasets. Applying the selective layer fine-tuning approach to more complex, real-world federated learning scenarios, such as those involving unbalanced or sparse data, would be valuable.
- The paper does not address potential issues like communication efficiency, privacy preservation, or model convergence in the federated fine-tuning process. These practical considerations should be explored in future work.
Conclusion
The paper presents a novel approach to improving federated learning by selectively fine-tuning the layers of a machine learning model based on the unique characteristics of each client's data. This customized fine-tuning strategy can lead to better model performance compared to traditional federated learning or other fine-tuning methods.
The proposed framework provides a solid foundation for further research and development in the area of personalized and efficient federated learning. By considering the heterogeneity of client data and tailoring the model updates accordingly, the selective layer fine-tuning approach holds promise for real-world federated learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Selective Layer Fine-Tuning in Federated Learning
Yuchang Sun, Yuexiang Xie, Bolin Ding, Yaliang Li, Jun Zhang
Federated learning (FL) has emerged as a promising paradigm for fine-tuning foundation models using distributed data in a privacy-preserving manner. Under limited computational resources, clients often find it more practical to fine-tune a selected subset of layers, rather than the entire model, based on their task-specific data. In this study, we provide a thorough theoretical exploration of selective layer fine-tuning in FL, emphasizing a flexible approach that allows the clients to adjust their selected layers according to their local data and resources. We theoretically demonstrate that the layer selection strategy has a significant impact on model convergence in two critical aspects: the importance of selected layers and the heterogeneous choices across clients. Drawing from these insights, we further propose a strategic layer selection method that utilizes local gradients and regulates layer selections across clients. The extensive experiments on both image and text datasets demonstrate the effectiveness of the proposed strategy compared with several baselines, highlighting its advances in identifying critical layers that adapt to the client heterogeneity and training dynamics in FL.
Read more9/27/2024

0
FedSelect: Customized Selection of Parameters for Fine-Tuning during Personalized Federated Learning
Rishub Tamirisa, John Won, Chengjun Lu, Ron Arel, Andy Zhou
Recent advancements in federated learning (FL) seek to increase client-level performance by fine-tuning client parameters on local data or personalizing architectures for the local task. Existing methods for such personalization either prune a global model or fine-tune a global model on a local client distribution. However, these existing methods either personalize at the expense of retaining important global knowledge, or predetermine network layers for fine-tuning, resulting in suboptimal storage of global knowledge within client models. Enlightened by the lottery ticket hypothesis, we first introduce a hypothesis for finding optimal client subnetworks to locally fine-tune while leaving the rest of the parameters frozen. We then propose a novel FL framework, FedSelect, using this procedure that directly personalizes both client subnetwork structure and parameters, via the simultaneous discovery of optimal parameters for personalization and the rest of parameters for global aggregation during training. We show that this method achieves promising results on CIFAR-10.
Read more6/11/2024

0
FedSelect: Personalized Federated Learning with Customized Selection of Parameters for Fine-Tuning
Rishub Tamirisa, Chulin Xie, Wenxuan Bao, Andy Zhou, Ron Arel, Aviv Shamsian
Standard federated learning approaches suffer when client data distributions have sufficient heterogeneity. Recent methods addressed the client data heterogeneity issue via personalized federated learning (PFL) - a class of FL algorithms aiming to personalize learned global knowledge to better suit the clients' local data distributions. Existing PFL methods usually decouple global updates in deep neural networks by performing personalization on particular layers (i.e. classifier heads) and global aggregation for the rest of the network. However, preselecting network layers for personalization may result in suboptimal storage of global knowledge. In this work, we propose FedSelect, a novel PFL algorithm inspired by the iterative subnetwork discovery procedure used for the Lottery Ticket Hypothesis. FedSelect incrementally expands subnetworks to personalize client parameters, concurrently conducting global aggregations on the remaining parameters. This approach enables the personalization of both client parameters and subnetwork structure during the training process. Finally, we show that FedSelect outperforms recent state-of-the-art PFL algorithms under challenging client data heterogeneity settings and demonstrates robustness to various real-world distributional shifts. Our code is available at https://github.com/lapisrocks/fedselect.
Read more4/4/2024

0
FedPFT: Federated Proxy Fine-Tuning of Foundation Models
Zhaopeng Peng, Xiaoliang Fan, Yufan Chen, Zheng Wang, Shirui Pan, Chenglu Wen, Ruisheng Zhang, Cheng Wang
Adapting Foundation Models (FMs) for downstream tasks through Federated Learning (FL) emerges a promising strategy for protecting data privacy and valuable FMs. Existing methods fine-tune FM by allocating sub-FM to clients in FL, however, leading to suboptimal performance due to insufficient tuning and inevitable error accumulations of gradients. In this paper, we propose Federated Proxy Fine-Tuning (FedPFT), a novel method enhancing FMs adaptation in downstream tasks through FL by two key modules. First, the sub-FM construction module employs a layer-wise compression approach, facilitating comprehensive FM fine-tuning across all layers by emphasizing those crucial neurons. Second, the sub-FM alignment module conducts a two-step distillations-layer-level and neuron-level-before and during FL fine-tuning respectively, to reduce error of gradient by accurately aligning sub-FM with FM under theoretical guarantees. Experimental results on seven commonly used datasets (i.e., four text and three vision) demonstrate the superiority of FedPFT.
Read more4/30/2024