FedSelect: Personalized Federated Learning with Customized Selection of Parameters for Fine-Tuning

0

Sign in to get full access
Overview
- The paper presents a novel approach called "FedSelect" for personalized federated learning, where each client can customize the parameters they use for fine-tuning a shared model.
- FedSelect aims to improve the performance of federated learning by allowing clients to focus on the most relevant model parameters based on their local data and tasks.
- The key idea is to give clients the flexibility to select a subset of parameters to fine-tune, rather than updating the entire model.
Plain English Explanation
FedSelect is a new technique for federated learning, which is a way of training machine learning models using data from many different devices or clients, without requiring the raw data to be shared. In traditional federated learning, all clients update the same set of model parameters, but FedSelect allows each client to customize which parameters they want to fine-tune based on their own data and needs.
The main advantage of this approach is that it can lead to better performance for each individual client, since they can focus on tuning the most relevant parts of the model for their specific use case. Imagine you have a machine learning model that can recognize different types of animals. A client who mostly deals with dogs may want to fine-tune the parameters related to dog recognition, while a client who works with cats may focus on tuning the cat-related parameters. By allowing this personalization, FedSelect can help the model perform better for each individual client's needs.
The paper demonstrates through experiments that FedSelect can indeed outperform traditional federated learning approaches, particularly when the clients have diverse data distributions or tasks. This flexibility to customize the model updates can be very beneficial in real-world federated learning scenarios where clients have varying requirements and data.
Technical Explanation
The key idea behind FedSelect is to give clients the ability to select a subset of the model parameters to fine-tune, rather than updating the entire model during the federated learning process. This is achieved by introducing a "selection vector" for each client, which indicates which parameters they want to focus on.
The FedSelect algorithm works as follows:
- The server initializes a global model and shares it with all clients.
- Each client selects a subset of the model parameters to fine-tune based on their local data and tasks, and updates the corresponding entries in their selection vector.
- Clients perform local training on their selected parameters and send the updated parameters and selection vectors back to the server.
- The server aggregates the updates from all clients, weighted by their selection vectors, to produce the next global model.
- The process repeats for multiple rounds until convergence.
The paper evaluates FedSelect on several benchmark datasets and compares it to traditional federated learning approaches. The results show that FedSelect can significantly outperform these baselines, especially when the clients have diverse data distributions or tasks.
Critical Analysis
The paper presents a compelling approach to improving the performance of federated learning by allowing for personalized parameter selection. The key strength of FedSelect is its flexibility, which can be particularly beneficial in real-world scenarios where clients have varying data and requirements.
One potential limitation mentioned in the paper is that FedSelect may be more computationally expensive than standard federated learning, as clients need to maintain and update their own selection vectors. The authors argue that this overhead is manageable, but it would be valuable to see a more detailed analysis of the computational and communication costs.
Additionally, the paper focuses on demonstrating the benefits of FedSelect in terms of model performance, but does not delve into other important considerations such as privacy, fairness, and interpretability. Further research could explore how FedSelect interacts with these crucial aspects of federated learning.
Overall, FedSelect represents an interesting and promising direction for advancing the field of federated learning, and the paper provides a solid foundation for future work in this area.
Conclusion
The FedSelect approach presented in this paper offers a novel way to improve the performance of federated learning by allowing clients to customize the model parameters they fine-tune. By giving clients the flexibility to focus on the most relevant parts of the model, FedSelect can lead to better outcomes for individual clients, particularly in scenarios where they have diverse data or tasks.
While the paper demonstrates the benefits of FedSelect through experiments, there are still some open questions and areas for further research, such as the computational costs and the interplay with other important considerations like privacy and fairness. Nevertheless, this work represents an important step forward in the field of federated learning and provides a promising direction for future developments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FedSelect: Personalized Federated Learning with Customized Selection of Parameters for Fine-Tuning
Rishub Tamirisa, Chulin Xie, Wenxuan Bao, Andy Zhou, Ron Arel, Aviv Shamsian
Standard federated learning approaches suffer when client data distributions have sufficient heterogeneity. Recent methods addressed the client data heterogeneity issue via personalized federated learning (PFL) - a class of FL algorithms aiming to personalize learned global knowledge to better suit the clients' local data distributions. Existing PFL methods usually decouple global updates in deep neural networks by performing personalization on particular layers (i.e. classifier heads) and global aggregation for the rest of the network. However, preselecting network layers for personalization may result in suboptimal storage of global knowledge. In this work, we propose FedSelect, a novel PFL algorithm inspired by the iterative subnetwork discovery procedure used for the Lottery Ticket Hypothesis. FedSelect incrementally expands subnetworks to personalize client parameters, concurrently conducting global aggregations on the remaining parameters. This approach enables the personalization of both client parameters and subnetwork structure during the training process. Finally, we show that FedSelect outperforms recent state-of-the-art PFL algorithms under challenging client data heterogeneity settings and demonstrates robustness to various real-world distributional shifts. Our code is available at https://github.com/lapisrocks/fedselect.
Read more4/4/2024

0
FedSelect: Customized Selection of Parameters for Fine-Tuning during Personalized Federated Learning
Rishub Tamirisa, John Won, Chengjun Lu, Ron Arel, Andy Zhou
Recent advancements in federated learning (FL) seek to increase client-level performance by fine-tuning client parameters on local data or personalizing architectures for the local task. Existing methods for such personalization either prune a global model or fine-tune a global model on a local client distribution. However, these existing methods either personalize at the expense of retaining important global knowledge, or predetermine network layers for fine-tuning, resulting in suboptimal storage of global knowledge within client models. Enlightened by the lottery ticket hypothesis, we first introduce a hypothesis for finding optimal client subnetworks to locally fine-tune while leaving the rest of the parameters frozen. We then propose a novel FL framework, FedSelect, using this procedure that directly personalizes both client subnetwork structure and parameters, via the simultaneous discovery of optimal parameters for personalization and the rest of parameters for global aggregation during training. We show that this method achieves promising results on CIFAR-10.
Read more6/11/2024
0
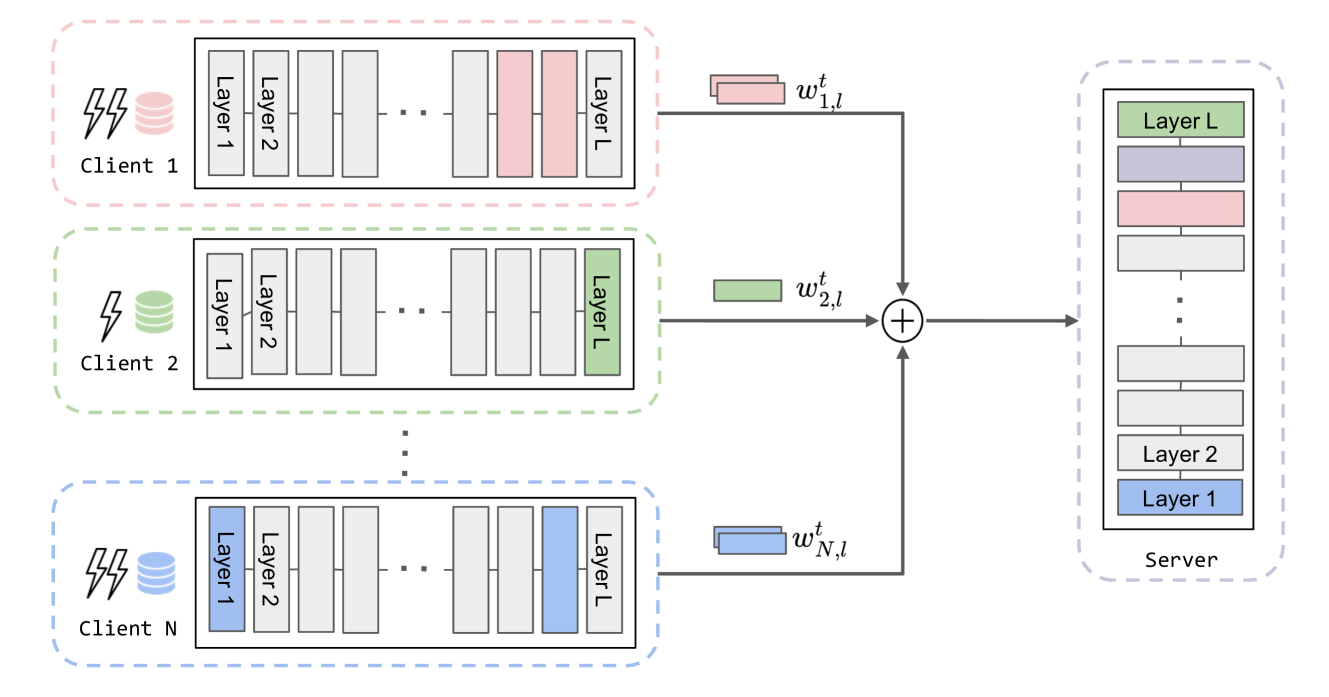
Exploring Selective Layer Fine-Tuning in Federated Learning
Yuchang Sun, Yuexiang Xie, Bolin Ding, Yaliang Li, Jun Zhang
Federated learning (FL) has emerged as a promising paradigm for fine-tuning foundation models using distributed data in a privacy-preserving manner. Under limited computational resources, clients often find it more practical to fine-tune a selected subset of layers, rather than the entire model, based on their task-specific data. In this study, we provide a thorough theoretical exploration of selective layer fine-tuning in FL, emphasizing a flexible approach that allows the clients to adjust their selected layers according to their local data and resources. We theoretically demonstrate that the layer selection strategy has a significant impact on model convergence in two critical aspects: the importance of selected layers and the heterogeneous choices across clients. Drawing from these insights, we further propose a strategic layer selection method that utilizes local gradients and regulates layer selections across clients. The extensive experiments on both image and text datasets demonstrate the effectiveness of the proposed strategy compared with several baselines, highlighting its advances in identifying critical layers that adapt to the client heterogeneity and training dynamics in FL.
Read more9/27/2024
📶
0
Personalized Federated Learning Techniques: Empirical Analysis
Azal Ahmad Khan, Ahmad Faraz Khan, Haider Ali, Ali Anwar
Personalized Federated Learning (pFL) holds immense promise for tailoring machine learning models to individual users while preserving data privacy. However, achieving optimal performance in pFL often requires a careful balancing act between memory overhead costs and model accuracy. This paper delves into the trade-offs inherent in pFL, offering valuable insights for selecting the right algorithms for diverse real-world scenarios. We empirically evaluate ten prominent pFL techniques across various datasets and data splits, uncovering significant differences in their performance. Our study reveals interesting insights into how pFL methods that utilize personalized (local) aggregation exhibit the fastest convergence due to their efficiency in communication and computation. Conversely, fine-tuning methods face limitations in handling data heterogeneity and potential adversarial attacks while multi-objective learning methods achieve higher accuracy at the cost of additional training and resource consumption. Our study emphasizes the critical role of communication efficiency in scaling pFL, demonstrating how it can significantly affect resource usage in real-world deployments.
Read more9/12/2024