Low-Resource Self-Supervised Learning with SSL-Enhanced TTS
2309.17020
0
0
🚀
Abstract
Self-supervised learning (SSL) techniques have achieved remarkable results in various speech processing tasks. Nonetheless, a significant challenge remains in reducing the reliance on vast amounts of speech data for pre-training. This paper proposes to address this challenge by leveraging synthetic speech to augment a low-resource pre-training corpus. We construct a high-quality text-to-speech (TTS) system with limited resources using SSL features and generate a large synthetic corpus for pre-training. Experimental results demonstrate that our proposed approach effectively reduces the demand for speech data by 90% with only slight performance degradation. To the best of our knowledge, this is the first work aiming to enhance low-resource self-supervised learning in speech processing.
Create account to get full access
Overview
- Researchers have achieved impressive results using self-supervised learning (SSL) techniques in speech processing tasks.
- However, a key challenge remains in reducing the need for large amounts of speech data for pre-training these models.
- This paper proposes a novel approach to address this challenge by leveraging synthetic speech to augment a low-resource pre-training corpus.
Plain English Explanation
The paper explores a way to improve self-supervised learning for speech processing without requiring as much real speech data. The researchers built a high-quality text-to-speech (TTS) system using limited resources and self-supervised learning features. They then used this TTS system to generate a large synthetic speech corpus, which they used to pre-train their speech models.
The key insight is that by supplementing a small amount of real speech data with a much larger amount of synthetic speech, the models can still learn effective representations without needing vast quantities of real data. This could be particularly useful for low-data regimes or resource-constrained settings where collecting large speech datasets is challenging.
Technical Explanation
The researchers constructed a high-quality TTS system using SSL features, even with limited resources. They then generated a large synthetic speech corpus and used it to pre-train their speech models, along with a small amount of real speech data.
Experimental results showed that this approach could reduce the demand for speech data by 90% with only a slight performance degradation. To the best of the authors' knowledge, this is the first work to explore enhancing low-resource self-supervised learning in speech processing using synthetic speech.
Critical Analysis
The paper presents a promising approach to address the data-hungry nature of self-supervised learning for speech tasks. By leveraging synthetic speech, the researchers were able to significantly reduce the required amount of real speech data with only a minor impact on performance.
However, the authors acknowledge that the quality and characteristics of the synthetic speech may still differ from real speech, which could limit the effectiveness of this approach. Further research is needed to understand the extent to which synthetic speech can effectively substitute for real data in various speech processing tasks and domains.
Conclusion
This paper introduces a novel technique to enhance low-resource self-supervised learning in speech processing by using synthetic speech to augment the pre-training corpus. The results demonstrate that this approach can significantly reduce the demand for real speech data while maintaining reasonable performance, which could have important implications for building speech systems in resource-constrained settings. As the field continues to explore ways to reduce reliance on large datasets, this work offers a promising direction for further research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
An Initial Investigation of Language Adaptation for TTS Systems under Low-resource Scenarios
Cheng Gong, Erica Cooper, Xin Wang, Chunyu Qiang, Mengzhe Geng, Dan Wells, Longbiao Wang, Jianwu Dang, Marc Tessier, Aidan Pine, Korin Richmond, Junichi Yamagishi
0
0
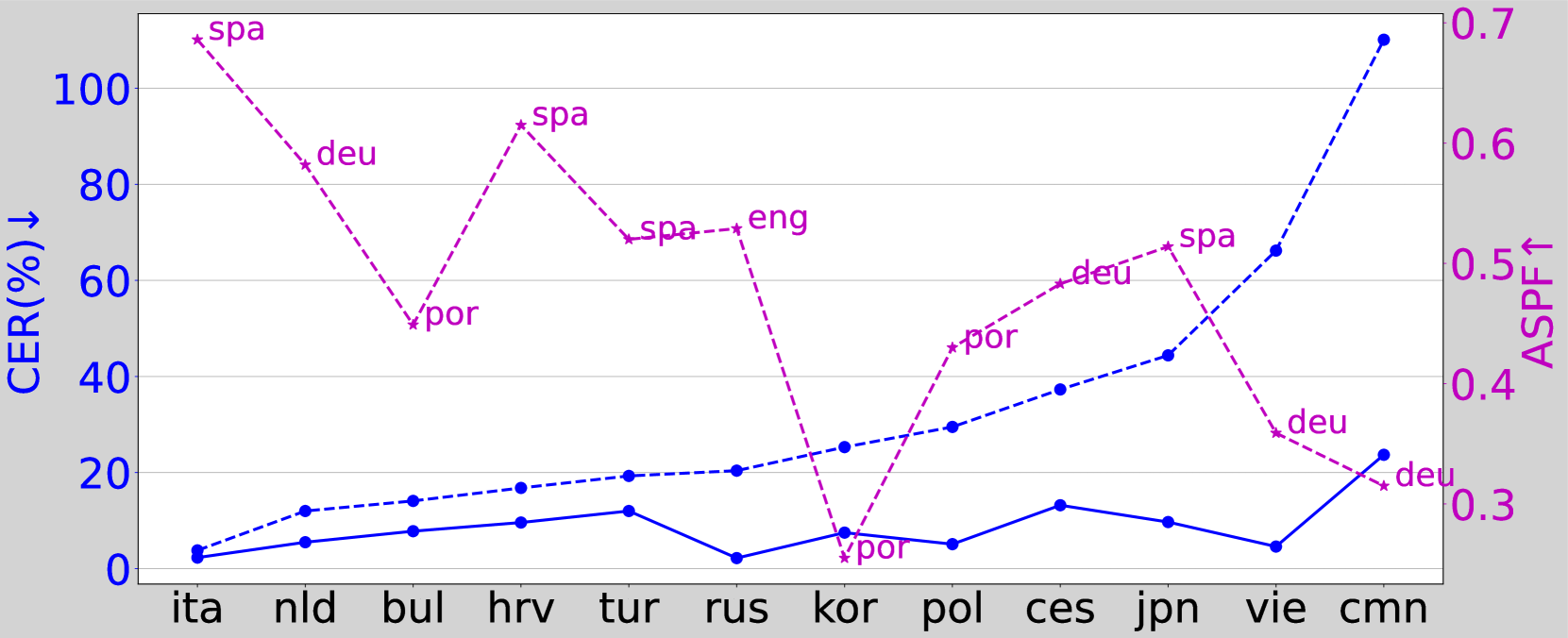
Self-supervised learning (SSL) representations from massively multilingual models offer a promising solution for low-resource language speech tasks. Despite advancements, language adaptation in TTS systems remains an open problem. This paper explores the language adaptation capability of ZMM-TTS, a recent SSL-based multilingual TTS system proposed in our previous work. We conducted experiments on 12 languages using limited data with various fine-tuning configurations. We demonstrate that the similarity in phonetics between the pre-training and target languages, as well as the language category, affects the target language's adaptation performance. Additionally, we find that the fine-tuning dataset size and number of speakers influence adaptability. Surprisingly, we also observed that using paired data for fine-tuning is not always optimal compared to audio-only data. Beyond speech intelligibility, our analysis covers speaker similarity, language identification, and predicted MOS.
6/14/2024
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
0
0
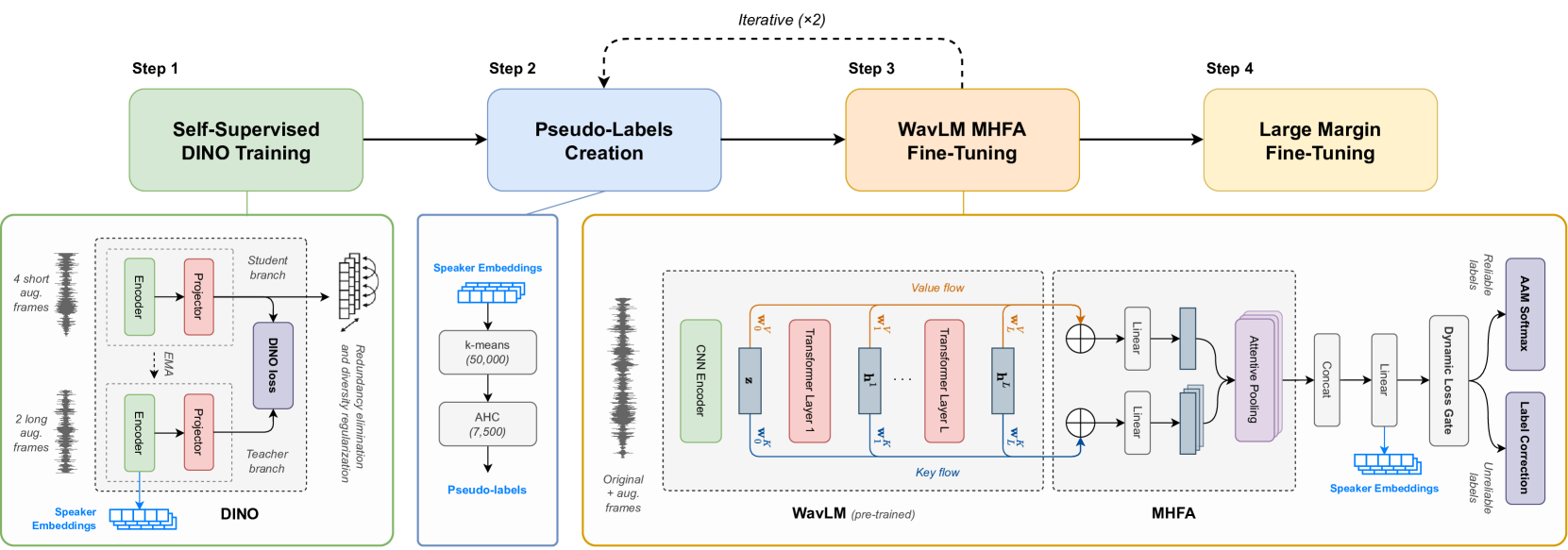
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
6/5/2024

Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
0
0
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
6/13/2024
Leveraging Synthetic Audio Data for End-to-End Low-Resource Speech Translation
Yasmin Moslem
0
0
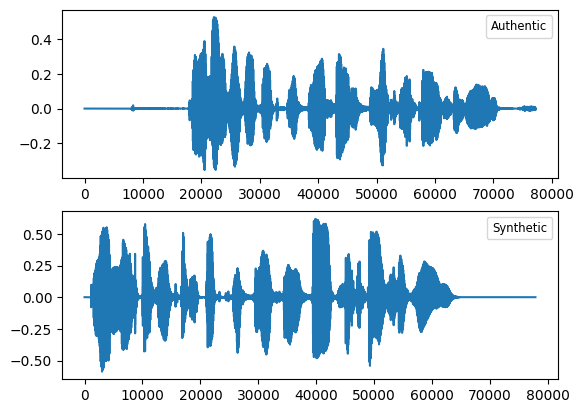
This paper describes our system submission to the International Conference on Spoken Language Translation (IWSLT 2024) for Irish-to-English speech translation. We built end-to-end systems based on Whisper, and employed a number of data augmentation techniques, such as speech back-translation and noise augmentation. We investigate the effect of using synthetic audio data and discuss several methods for enriching signal diversity.
6/28/2024