Exploring the traditional NMT model and Large Language Model for chat translation

0
📈
Sign in to get full access
Overview
- Explores the use of traditional neural machine translation (NMT) models and large language models (LLMs) for chat translation
- Compares the performance of NMT and LLM approaches on chat translation tasks
- Investigates strategies for combining NMT and LLM hypotheses to improve translation quality
Plain English Explanation
Machine translation technology has come a long way in recent years, with traditional NMT models and more recent large language models (LLMs) both playing important roles. This paper explores how these two approaches can be used for translating chat messages, which can be challenging due to their informal and conversational nature.
The researchers compared the performance of NMT and LLM models on chat translation tasks, and investigated ways to combine the outputs of these models to improve the overall translation quality. The goal was to leverage the strengths of both approaches to produce more accurate and natural-sounding translations for real-world chat conversations.
Technical Explanation
The paper begins by describing the dataset used for the experiments, which consists of chat messages in multiple languages. The researchers then trained both NMT and LLM models on this data and evaluated their performance on various translation quality metrics.
To improve the translation quality, the researchers explored different strategies for combining the hypotheses generated by the NMT and LLM models. This included methods such as taking the best hypothesis from either model, as well as more sophisticated approaches like using the LLM to rerank the NMT hypotheses.
The results showed that the combined NMT-LLM approach outperformed both the standalone NMT and LLM models, demonstrating the potential benefits of leveraging the complementary strengths of these two translation paradigms.
Critical Analysis
The paper presents a well-designed and rigorous evaluation of the NMT and LLM approaches for chat translation. However, there are a few potential limitations and areas for further research:
-
The dataset used in the experiments, while large, may not fully capture the diversity and complexity of real-world chat conversations. Expanding the dataset and testing the models on more varied chat data could provide additional insights.
-
The researchers focused on combining the NMT and LLM models at the hypothesis level, but there may be other ways to integrate these approaches more deeply, such as jointly training the models or using the LLM to guide the NMT model during the translation process.
-
The paper does not explore the potential fairness and bias implications of using these translation models, which could be an important consideration for real-world applications.
Overall, this paper makes a valuable contribution to the understanding of how NMT and LLM models can be leveraged for improved chat translation, and provides a solid foundation for further research in this area.
Conclusion
This research paper highlights the potential of combining traditional NMT models and more recent LLMs to enhance the quality of chat translation. By exploring different strategies for integrating the strengths of these two approaches, the researchers were able to demonstrate improved translation performance compared to using either model alone.
The findings from this work could have important implications for real-world applications of machine translation, particularly in the context of informal, conversational communication like chat messages. As machine translation technology continues to evolve, the ability to accurately and naturally translate these types of messages will become increasingly valuable for global communication and collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Exploring the traditional NMT model and Large Language Model for chat translation
Jinlong Yang, Hengchao Shang, Daimeng Wei, Jiaxin Guo, Zongyao Li, Zhanglin Wu, Zhiqiang Rao, Shaojun Li, Yuhao Xie, Yuanchang Luo, Jiawei Zheng, Bin Wei, Hao Yang
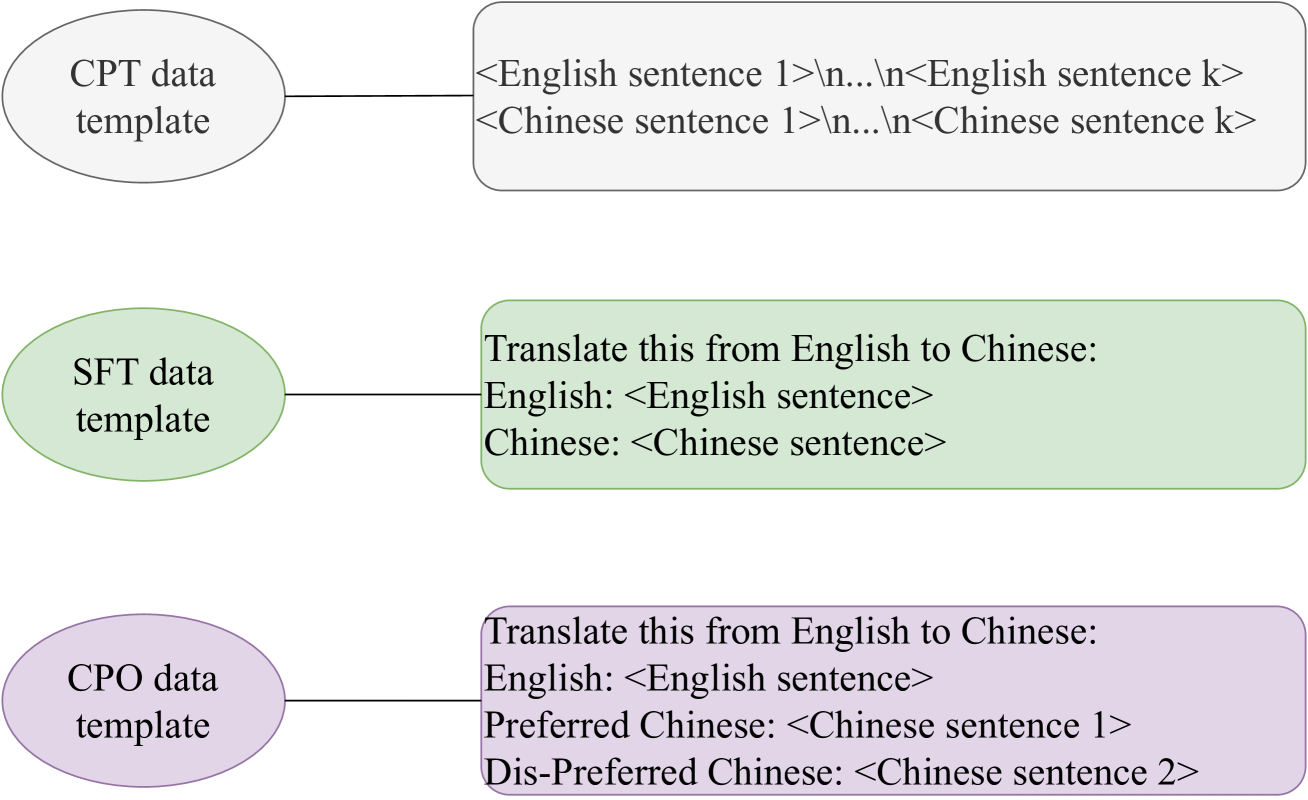
This paper describes the submissions of Huawei Translation Services Center(HW-TSC) to WMT24 chat translation shared task on English$leftrightarrow$Germany (en-de) bidirection. The experiments involved fine-tuning models using chat data and exploring various strategies, including Minimum Bayesian Risk (MBR) decoding and self-training. The results show significant performance improvements in certain directions, with the MBR self-training method achieving the best results. The Large Language Model also discusses the challenges and potential avenues for further research in the field of chat translation.
Read more9/26/2024
0
Choose the Final Translation from NMT and LLM hypotheses Using MBR Decoding: HW-TSC's Submission to the WMT24 General MT Shared Task
Zhanglin Wu, Daimeng Wei, Zongyao Li, Hengchao Shang, Jiaxin Guo, Shaojun Li, Zhiqiang Rao, Yuanchang Luo, Ning Xie, Hao Yang
This paper presents the submission of Huawei Translate Services Center (HW-TSC) to the WMT24 general machine translation (MT) shared task, where we participate in the English to Chinese (en2zh) language pair. Similar to previous years' work, we use training strategies such as regularized dropout, bidirectional training, data diversification, forward translation, back translation, alternated training, curriculum learning, and transductive ensemble learning to train the neural machine translation (NMT) model based on the deep Transformer-big architecture. The difference is that we also use continue pre-training, supervised fine-tuning, and contrastive preference optimization to train the large language model (LLM) based MT model. By using Minimum Bayesian risk (MBR) decoding to select the final translation from multiple hypotheses for NMT and LLM-based MT models, our submission receives competitive results in the final evaluation.
Read more9/24/2024
💬
0
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
Read more6/17/2024

0
GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
Read more5/17/2024