Choose the Final Translation from NMT and LLM hypotheses Using MBR Decoding: HW-TSC's Submission to the WMT24 General MT Shared Task

0
Sign in to get full access
Overview
- The paper proposes a method for choosing the final translation from multiple hypotheses generated by neural machine translation (NMT) and large language models (LLMs) using Minimum Bayes Risk (MBR) decoding.
- The method was submitted as part of the HW-TSC team's entry to the WMT24 General Machine Translation Shared Task.
- The paper aims to leverage the strengths of both NMT and LLM models to produce high-quality translations.
Plain English Explanation
The paper describes a way to choose the best translation from a set of translation options generated by different machine learning models. The researchers used two types of models - neural machine translation (NMT) and large language models (LLMs).
NMT models are specialized for translating text between languages, while LLMs can generate fluent text on a wide range of topics. The researchers found that combining the outputs of these two types of models can produce better translations than either model alone.
To do this, they used a technique called Minimum Bayes Risk (MBR) decoding. MBR decoding looks at all the possible translation options and chooses the one that is most likely to be the best based on statistical analyses. This helps to select the final translation that combines the strengths of the NMT and LLM models.
The researchers submitted this approach as part of their team's entry to the WMT24 General Machine Translation Shared Task, a competition to develop the best machine translation systems.
Technical Explanation
The paper proposes a novel approach for choosing the final translation from multiple hypotheses generated by neural machine translation (NMT) and large language models (LLMs) using Minimum Bayes Risk (MBR) decoding.
The key elements of the approach are:
-
NMT and LLM Models: The researchers leverage two types of models - NMT models that are specialized for translating between languages, and LLMs that can generate fluent text on a wide range of topics.
-
Hypothesis Generation: The NMT and LLM models are used to generate multiple translation hypotheses for each input sentence.
-
MBR Decoding: The researchers apply MBR decoding to choose the final translation from the set of hypotheses. MBR decoding selects the hypothesis that minimizes the expected loss between the candidate translation and the true (unknown) translation.
-
Loss Functions: The researchers experiment with different loss functions within the MBR framework, including BLEU score and COMET, to evaluate the quality of the translation hypotheses.
The key insight is that by combining the strengths of both NMT and LLM models using MBR decoding, the approach can produce higher quality translations than either model alone.
Critical Analysis
The paper presents a promising approach for leveraging multiple translation models to improve the quality of machine translation. However, there are a few potential limitations and areas for further research:
-
Reliance on MBR Decoding: The performance of the approach is heavily dependent on the effectiveness of the MBR decoding algorithm. Further research may be needed to explore alternative techniques for combining multiple translation hypotheses.
-
Loss Function Selection: The choice of loss function used in the MBR decoding step can have a significant impact on the final translation quality. The paper experiments with BLEU and COMET, but other loss functions may be worth exploring.
-
Scalability to Real-World Scenarios: The paper focuses on evaluating the approach on standard machine translation benchmarks. More research may be needed to understand how it would perform in real-world, large-scale translation tasks.
-
Explainability and Interpretability: As with many machine learning-based approaches, the "black box" nature of the NMT and LLM models used in the approach may make it difficult to understand the reasoning behind the final translations. Improving the explainability of the system could be a valuable avenue for future research.
Despite these potential limitations, the paper presents an interesting and potentially impactful contribution to the field of machine translation by combining the strengths of different models to produce higher quality translations.
Conclusion
The paper proposes a novel approach for choosing the final translation from multiple hypotheses generated by neural machine translation (NMT) and large language models (LLMs) using Minimum Bayes Risk (MBR) decoding. The key idea is to leverage the complementary strengths of NMT and LLM models to produce higher quality translations.
The approach was submitted as part of the HW-TSC team's entry to the WMT24 General Machine Translation Shared Task, demonstrating its potential for real-world applications. While the paper presents a promising contribution, further research may be needed to address potential limitations and explore ways to improve the scalability and interpretability of the system.
Overall, the paper offers an interesting novel paradigm for combining multiple machine translation models to enhance the performance of machine translation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Choose the Final Translation from NMT and LLM hypotheses Using MBR Decoding: HW-TSC's Submission to the WMT24 General MT Shared Task
Zhanglin Wu, Daimeng Wei, Zongyao Li, Hengchao Shang, Jiaxin Guo, Shaojun Li, Zhiqiang Rao, Yuanchang Luo, Ning Xie, Hao Yang
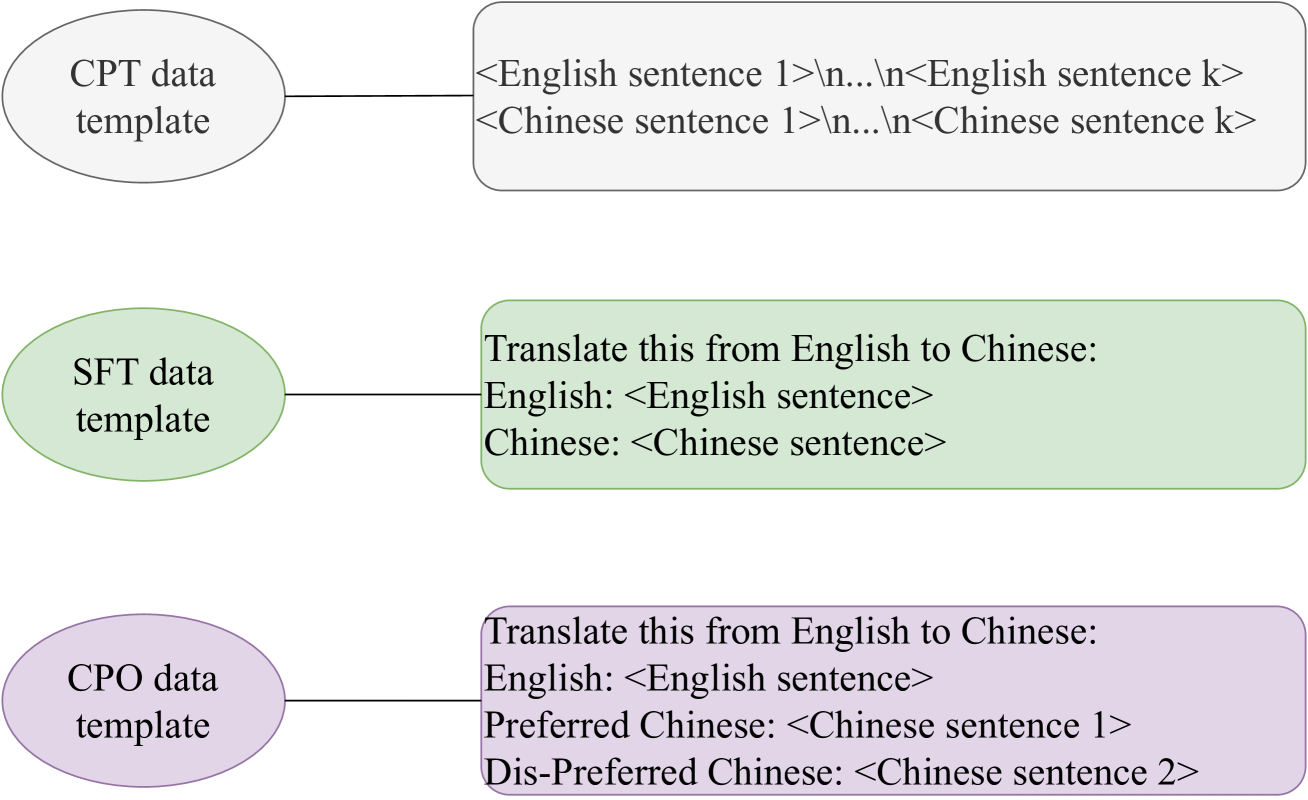
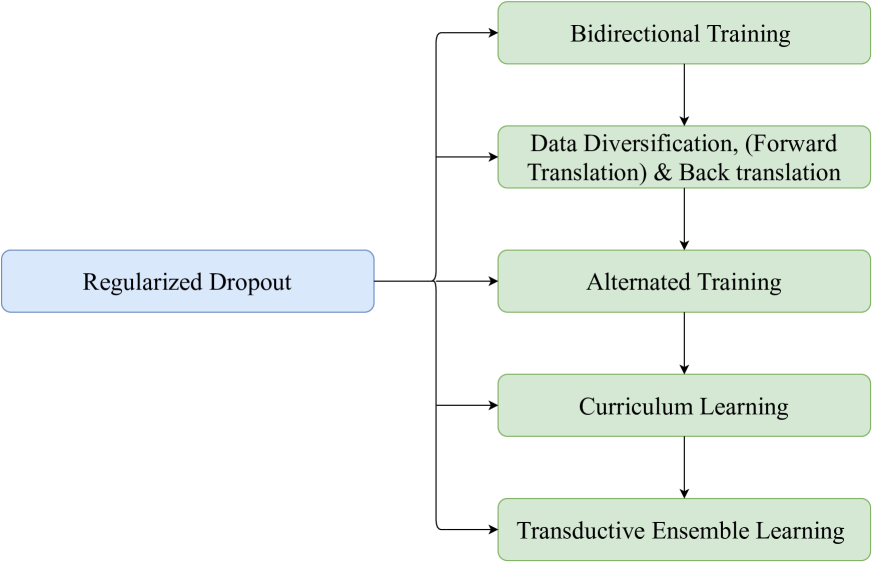
This paper presents the submission of Huawei Translate Services Center (HW-TSC) to the WMT24 general machine translation (MT) shared task, where we participate in the English to Chinese (en2zh) language pair. Similar to previous years' work, we use training strategies such as regularized dropout, bidirectional training, data diversification, forward translation, back translation, alternated training, curriculum learning, and transductive ensemble learning to train the neural machine translation (NMT) model based on the deep Transformer-big architecture. The difference is that we also use continue pre-training, supervised fine-tuning, and contrastive preference optimization to train the large language model (LLM) based MT model. By using Minimum Bayesian risk (MBR) decoding to select the final translation from multiple hypotheses for NMT and LLM-based MT models, our submission receives competitive results in the final evaluation.
Read more9/24/2024
0
HW-TSC's Submission to the CCMT 2024 Machine Translation Tasks
Zhanglin Wu, Yuanchang Luo, Daimeng Wei, Jiawei Zheng, Bin Wei, Zongyao Li, Hengchao Shang, Jiaxin Guo, Shaojun Li, Weidong Zhang, Ning Xie, Hao Yang
This paper presents the submission of Huawei Translation Services Center (HW-TSC) to machine translation tasks of the 20th China Conference on Machine Translation (CCMT 2024). We participate in the bilingual machine translation task and multi-domain machine translation task. For these two translation tasks, we use training strategies such as regularized dropout, bidirectional training, data diversification, forward translation, back translation, alternated training, curriculum learning, and transductive ensemble learning to train neural machine translation (NMT) models based on the deep Transformer-big architecture. Furthermore, to explore whether large language model (LLM) can help improve the translation quality of NMT systems, we use supervised fine-tuning to train llama2-13b as an Automatic post-editing (APE) model to improve the translation results of the NMT model on the multi-domain machine translation task. By using these plyometric strategies, our submission achieves a competitive result in the final evaluation.
Read more9/30/2024
📈
0
Exploring the traditional NMT model and Large Language Model for chat translation
Jinlong Yang, Hengchao Shang, Daimeng Wei, Jiaxin Guo, Zongyao Li, Zhanglin Wu, Zhiqiang Rao, Shaojun Li, Yuhao Xie, Yuanchang Luo, Jiawei Zheng, Bin Wei, Hao Yang
This paper describes the submissions of Huawei Translation Services Center(HW-TSC) to WMT24 chat translation shared task on English$leftrightarrow$Germany (en-de) bidirection. The experiments involved fine-tuning models using chat data and exploring various strategies, including Minimum Bayesian Risk (MBR) decoding and self-training. The results show significant performance improvements in certain directions, with the MBR self-training method achieving the best results. The Large Language Model also discusses the challenges and potential avenues for further research in the field of chat translation.
Read more9/26/2024
0
Multilingual Transfer and Domain Adaptation for Low-Resource Languages of Spain
Yuanchang Luo, Zhanglin Wu, Daimeng Wei, Hengchao Shang, Zongyao Li, Jiaxin Guo, Zhiqiang Rao, Shaojun Li, Jinlong Yang, Yuhao Xie, Jiawei Zheng Bin Wei, Hao Yang
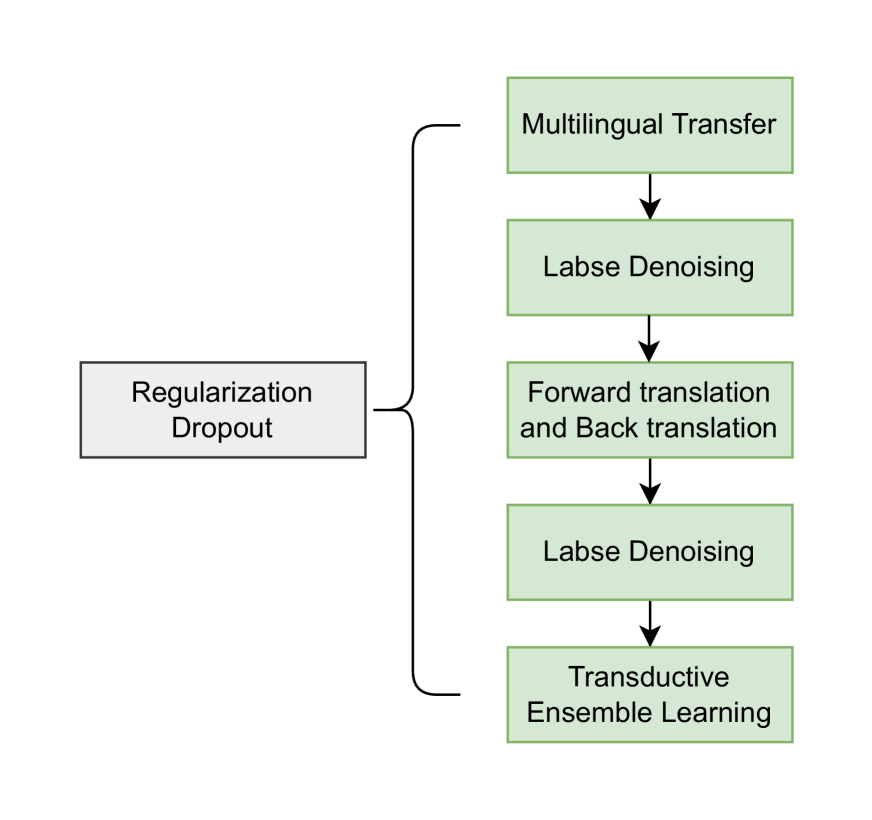
This article introduces the submission status of the Translation into Low-Resource Languages of Spain task at (WMT 2024) by Huawei Translation Service Center (HW-TSC). We participated in three translation tasks: spanish to aragonese (es-arg), spanish to aranese (es-arn), and spanish to asturian (es-ast). For these three translation tasks, we use training strategies such as multilingual transfer, regularized dropout, forward translation and back translation, labse denoising, transduction ensemble learning and other strategies to neural machine translation (NMT) model based on training deep transformer-big architecture. By using these enhancement strategies, our submission achieved a competitive result in the final evaluation.
Read more9/25/2024