FactorLLM: Factorizing Knowledge via Mixture of Experts for Large Language Models

0

Sign in to get full access
Overview
- Introduces a new approach called FactorLLM that uses a mixture of experts to factorize knowledge in large language models
- Aims to improve the efficiency and effectiveness of large language models by leveraging specialized experts for different types of knowledge
- Proposed method outperforms standard large language models on various benchmarks
Plain English Explanation
FactorLLM is a new technique for large language models that breaks up the model into a "mixture of experts." Instead of a single, monolithic language model, FactorLLM has multiple specialized sub-models, each focusing on a different type of knowledge.
The key idea is that different parts of language and knowledge can be better handled by different expert sub-models. For example, one expert might be better at answering factual questions, while another excels at creative writing. By dividing up the responsibilities, FactorLLM can leverage the strengths of each expert and avoid the limitations of a one-size-fits-all approach.
This modular design allows FactorLLM to be more efficient and effective than standard large language models. The experts can be more compact and specialized, requiring less overall compute power. And by selecting the most relevant expert for each task, FactorLLM can produce higher quality outputs.
The researchers show that FactorLLM outperforms large language models on a variety of benchmarks, demonstrating the potential benefits of this factorized approach to knowledge.
Technical Explanation
The key innovation in FactorLLM is the use of a mixture of experts architecture. Instead of a single large language model, FactorLLM consists of multiple specialized "expert" sub-models, each trained on a different type of knowledge or skill.
These experts are combined using a gating network that dynamically selects the most appropriate expert(s) for a given input. This allows FactorLLM to leverage the unique strengths of each expert, rather than relying on a single model to handle all tasks.
The researchers also introduce techniques to prune and compress the individual experts, making the overall FactorLLM model more efficient without sacrificing performance.
Experiments show that FactorLLM outperforms standard large language models on a range of benchmarks, including question answering, text generation, and few-shot learning tasks. This demonstrates the benefits of the factorized approach to knowledge representation and task-specific expertise.
Critical Analysis
The FactorLLM approach shows promising results, but there are a few potential limitations and areas for further research:
- The paper does not fully explore the interpretability and transparency of the individual expert models. Understanding how each expert contributes to the overall performance could be valuable.
- The training and optimization of the gating network is a critical component, but the paper does not provide extensive details on this process. Further investigation into the gating network design and training is warranted.
- The experiments are conducted on a limited set of tasks and datasets. Evaluating FactorLLM's performance on a wider range of real-world applications would help validate its broader applicability.
- The computational and memory efficiency gains of FactorLLM are promising, but the tradeoffs in terms of training complexity and inference latency should be further analyzed.
Overall, the FactorLLM approach represents an interesting step forward in making large language models more modular, efficient, and effective. Continued research in this direction could lead to more interpretable and adaptable AI systems.
Conclusion
The FactorLLM model introduces a novel approach to factorizing knowledge in large language models using a mixture of specialized expert sub-models. By breaking down the monolithic language model into a more modular architecture, FactorLLM can leverage the unique strengths of each expert to improve performance on a variety of tasks.
The key advantages of FactorLLM include enhanced efficiency, effectiveness, and the potential for greater interpretability compared to standard large language models. While further research is needed to fully understand the tradeoffs and limitations of this approach, the results presented in the paper suggest that factorized knowledge representation could be a fruitful direction for advancing the capabilities and applications of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FactorLLM: Factorizing Knowledge via Mixture of Experts for Large Language Models
Zhongyu Zhao, Menghang Dong, Rongyu Zhang, Wenzhao Zheng, Yunpeng Zhang, Huanrui Yang, Dalong Du, Kurt Keutzer, Shanghang Zhang
Recent research has demonstrated that Feed-Forward Networks (FFNs) in Large Language Models (LLMs) play a pivotal role in storing diverse linguistic and factual knowledge. Conventional methods frequently face challenges due to knowledge confusion stemming from their monolithic and redundant architectures, which calls for more efficient solutions with minimal computational overhead, particularly for LLMs. In this paper, we explore the FFN computation paradigm in LLMs and introduce FactorLLM, a novel approach that decomposes well-trained dense FFNs into sparse sub-networks without requiring any further modifications, while maintaining the same level of performance. Furthermore, we embed a router from the Mixture-of-Experts (MoE), combined with our devised Prior-Approximate (PA) loss term that facilitates the dynamic activation of experts and knowledge adaptation, thereby accelerating computational processes and enhancing performance using minimal training data and fine-tuning steps. FactorLLM thus enables efficient knowledge factorization and activates select groups of experts specifically tailored to designated tasks, emulating the interactive functional segmentation of the human brain. Extensive experiments across various benchmarks demonstrate the effectiveness of our proposed FactorLLM which achieves comparable performance to the source model securing up to 85% model performance while obtaining over a 30% increase in inference speed. Code: https://github.com/zhenwuweihe/FactorLLM.
Read more8/23/2024

0
FedMoE: Personalized Federated Learning via Heterogeneous Mixture of Experts
Hanzi Mei, Dongqi Cai, Ao Zhou, Shangguang Wang, Mengwei Xu
As Large Language Models (LLMs) push the boundaries of AI capabilities, their demand for data is growing. Much of this data is private and distributed across edge devices, making Federated Learning (FL) a de-facto alternative for fine-tuning (i.e., FedLLM). However, it faces significant challenges due to the inherent heterogeneity among clients, including varying data distributions and diverse task types. Towards a versatile FedLLM, we replace traditional dense model with a sparsely-activated Mixture-of-Experts (MoE) architecture, whose parallel feed-forward networks enable greater flexibility. To make it more practical in resource-constrained environments, we present FedMoE, the efficient personalized FL framework to address data heterogeneity, constructing an optimal sub-MoE for each client and bringing the knowledge back to global MoE. FedMoE is composed of two fine-tuning stages. In the first stage, FedMoE simplifies the problem by conducting a heuristic search based on observed activation patterns, which identifies a suboptimal submodel for each client. In the second stage, these submodels are distributed to clients for further training and returned for server aggregating through a novel modular aggregation strategy. Meanwhile, FedMoE progressively adjusts the submodels to optimal through global expert recommendation. Experimental results demonstrate the superiority of our method over previous personalized FL methods.
Read more8/22/2024
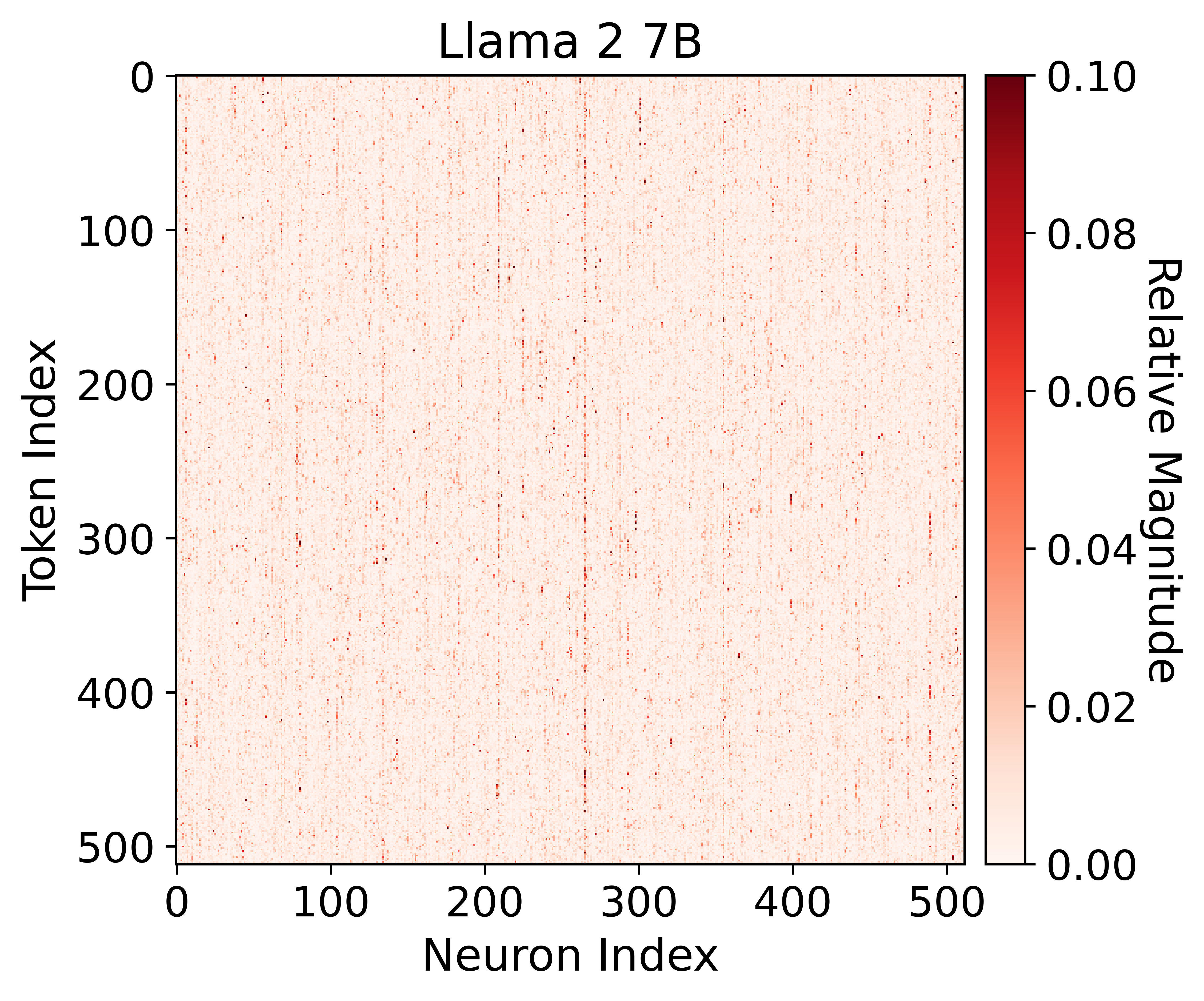
0
Prompt-prompted Mixture of Experts for Efficient LLM Generation
Harry Dong, Beidi Chen, Yuejie Chi
With the development of transformer-based large language models (LLMs), they have been applied to many fields due to their remarkable utility, but this comes at a considerable computational cost at deployment. Fortunately, some methods such as pruning or constructing a mixture of experts (MoE) aim at exploiting sparsity in transformer feedforward (FF) blocks to gain boosts in speed and reduction in memory requirements. However, these techniques can be very costly and inflexible in practice, as they often require training or are restricted to specific types of architectures. To address this, we introduce GRIFFIN, a novel training-free and calibration-free method that selects unique FF experts at the sequence level for efficient generation across a plethora of LLMs with different non-ReLU activation functions. This is possible due to a critical observation that many trained LLMs naturally produce highly structured FF activation patterns within a sequence, which we call flocking. Despite our method's simplicity, we show with 50% of the FF parameters, GRIFFIN maintains the original model's performance with little to no degradation on a variety of classification and generation tasks, all while improving latency (e.g. 1.29$times$ and 1.25$times$ speed-ups in Gemma 7B and Llama 2 13B, respectively, on an NVIDIA L40). Code is available at https://github.com/hdong920/GRIFFIN.
Read more8/13/2024

0
LLaMA-MoE: Building Mixture-of-Experts from LLaMA with Continual Pre-training
Tong Zhu, Xiaoye Qu, Daize Dong, Jiacheng Ruan, Jingqi Tong, Conghui He, Yu Cheng
Mixture-of-Experts (MoE) has gained increasing popularity as a promising framework for scaling up large language models (LLMs). However, training MoE from scratch in a large-scale setting still suffers from data-hungry and instability problems. Motivated by this limit, we investigate building MoE models from existing dense large language models. Specifically, based on the well-known LLaMA-2 7B model, we obtain an MoE model by: (1) Expert Construction, which partitions the parameters of original Feed-Forward Networks (FFNs) into multiple experts; (2) Continual Pre-training, which further trains the transformed MoE model and additional gate networks. In this paper, we comprehensively explore different methods for expert construction and various data sampling strategies for continual pre-training. After these stages, our LLaMA-MoE models could maintain language abilities and route the input tokens to specific experts with part of the parameters activated. Empirically, by training 200B tokens, LLaMA-MoE-3.5B models significantly outperform dense models that contain similar activation parameters. The source codes and models are available at https://github.com/pjlab-sys4nlp/llama-moe .
Read more6/26/2024