FADet: A Multi-sensor 3D Object Detection Network based on Local Featured Attention

0

Sign in to get full access
Overview
- This paper presents FADet, a multi-sensor 3D object detection network that leverages local featured attention to improve performance.
- FADet combines data from various sensors, such as cameras and LiDAR, to generate accurate 3D object detections.
- The key innovation is the use of a local featured attention mechanism, which helps the network focus on the most relevant features for object detection.
Plain English Explanation
The paper describes a system called FADet that is designed to detect 3D objects in the real world using data from multiple sensors. This is an important task for applications like self-driving cars, where accurately identifying the position and type of objects in the environment is crucial for safe navigation.
FADet combines information from cameras, which capture visual imagery, and LiDAR sensors, which measure the distance to objects using laser beams. By fusing the data from these complementary sensors, FADet can create a more complete and accurate understanding of the 3D environment compared to using a single sensor alone.
The key innovation in FADet is the use of a "local featured attention" mechanism. This allows the system to focus on the most relevant features for object detection, rather than treating all parts of the sensor data equally. This helps the network make more informed decisions about the presence and attributes of objects.
Technical Explanation
The FADet paper presents a multi-sensor 3D object detection network that leverages a local featured attention mechanism. The authors combine data from cameras and LiDAR sensors to generate accurate 3D object detections.
The network architecture consists of several components:
- Sensor Fusion Module: This module takes the raw sensor data (camera images and LiDAR point clouds) and fuses them into a unified feature representation.
- Local Featured Attention Module: This is the key innovation of the paper. It allows the network to focus on the most relevant local features for object detection, rather than treating all parts of the input equally.
- Detection Head: This final module takes the fused and attended features and generates the final 3D object detections, including the bounding box, class, and other attributes.
The authors evaluate FADet on several benchmark datasets for 3D object detection, including KITTI and nuScenes. They show that FADet outperforms state-of-the-art single-sensor and multi-sensor 3D object detection methods, demonstrating the effectiveness of the local featured attention mechanism.
Critical Analysis
The FADet paper presents a well-designed and thorough evaluation of their proposed 3D object detection system. The use of local featured attention is a compelling innovation that helps the network focus on the most relevant information for accurate object detection.
However, the paper does not address certain limitations or potential issues with the approach. For example, the performance of FADet may be sensitive to the quality and calibration of the input sensors, as poor sensor data could degrade the final object detections. Additionally, the computational complexity of the local featured attention module may limit the real-time performance of the system, which is crucial for applications like autonomous driving.
Further research could explore ways to improve the efficiency of the attention mechanism, perhaps by incorporating techniques from the field of efficient deep learning. Investigating the robustness of FADet to noisy or incomplete sensor data would also be a valuable direction for future work.
Overall, the FADet paper presents a promising approach to multi-sensor 3D object detection, and the local featured attention mechanism is a novel and impactful contribution to the field.
Conclusion
The FADet paper introduces a multi-sensor 3D object detection network that leverages a local featured attention mechanism to improve performance. By fusing data from cameras and LiDAR sensors, FADet can generate accurate 3D object detections, which are critical for applications like autonomous driving.
The key innovation of the paper is the use of local featured attention, which allows the network to focus on the most relevant features for object detection. This helps the system make more informed decisions and outperform state-of-the-art 3D object detection methods.
While the paper presents a thorough evaluation of FADet, there are opportunities for further research to address potential limitations, such as the sensitivity to sensor quality and the computational complexity of the attention mechanism. Nonetheless, the FADet paper is a valuable contribution to the field of multi-sensor 3D object detection and has the potential to advance the development of safer and more capable autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FADet: A Multi-sensor 3D Object Detection Network based on Local Featured Attention
Ziang Guo, Zakhar Yagudin, Selamawit Asfaw, Artem Lykov, Dzmitry Tsetserukou
Camera, LiDAR and radar are common perception sensors for autonomous driving tasks. Robust prediction of 3D object detection is optimally based on the fusion of these sensors. To exploit their abilities wisely remains a challenge because each of these sensors has its own characteristics. In this paper, we propose FADet, a multi-sensor 3D detection network, which specifically studies the characteristics of different sensors based on our local featured attention modules. For camera images, we propose dual-attention-based sub-module. For LiDAR point clouds, triple-attention-based sub-module is utilized while mixed-attention-based sub-module is applied for features of radar points. With local featured attention sub-modules, our FADet has effective detection results in long-tail and complex scenes from camera, LiDAR and radar input. On NuScenes validation dataset, FADet achieves state-of-the-art performance on LiDAR-camera object detection tasks with 71.8% NDS and 69.0% mAP, at the same time, on radar-camera object detection tasks with 51.7% NDS and 40.3% mAP. Code will be released at https://github.com/ZionGo6/FADet.
Read more5/21/2024
0
MUFASA: Multi-View Fusion and Adaptation Network with Spatial Awareness for Radar Object Detection
Xiangyuan Peng, Miao Tang, Huawei Sun, Kay Bierzynski, Lorenzo Servadei, Robert Wille
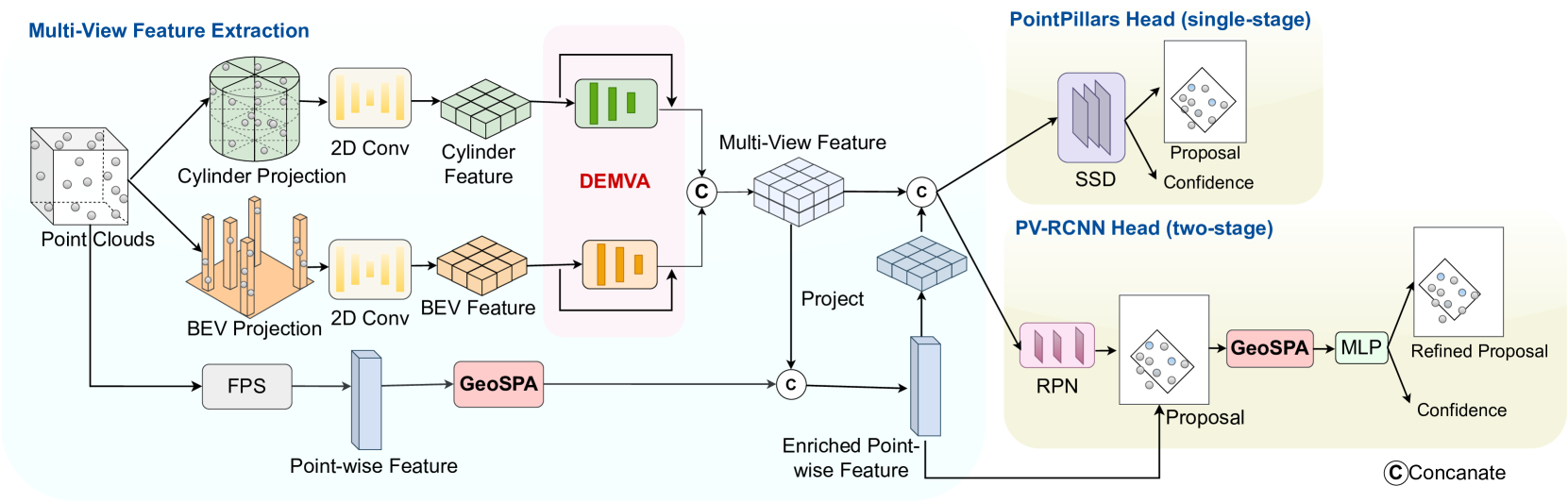
In recent years, approaches based on radar object detection have made significant progress in autonomous driving systems due to their robustness under adverse weather compared to LiDAR. However, the sparsity of radar point clouds poses challenges in achieving precise object detection, highlighting the importance of effective and comprehensive feature extraction technologies. To address this challenge, this paper introduces a comprehensive feature extraction method for radar point clouds. This study first enhances the capability of detection networks by using a plug-and-play module, GeoSPA. It leverages the Lalonde features to explore local geometric patterns. Additionally, a distributed multi-view attention mechanism, DEMVA, is designed to integrate the shared information across the entire dataset with the global information of each individual frame. By employing the two modules, we present our method, MUFASA, which enhances object detection performance through improved feature extraction. The approach is evaluated on the VoD and TJ4DRaDSet datasets to demonstrate its effectiveness. In particular, we achieve state-of-the-art results among radar-based methods on the VoD dataset with the mAP of 50.24%.
Read more8/2/2024

0
SparseDet: A Simple and Effective Framework for Fully Sparse LiDAR-based 3D Object Detection
Lin Liu, Ziying Song, Qiming Xia, Feiyang Jia, Caiyan Jia, Lei Yang, Hongyu Pan
LiDAR-based sparse 3D object detection plays a crucial role in autonomous driving applications due to its computational efficiency advantages. Existing methods either use the features of a single central voxel as an object proxy, or treat an aggregated cluster of foreground points as an object proxy. However, the former lacks the ability to aggregate contextual information, resulting in insufficient information expression in object proxies. The latter relies on multi-stage pipelines and auxiliary tasks, which reduce the inference speed. To maintain the efficiency of the sparse framework while fully aggregating contextual information, in this work, we propose SparseDet which designs sparse queries as object proxies. It introduces two key modules, the Local Multi-scale Feature Aggregation (LMFA) module and the Global Feature Aggregation (GFA) module, aiming to fully capture the contextual information, thereby enhancing the ability of the proxies to represent objects. Where LMFA sub-module achieves feature fusion across different scales for sparse key voxels %which does this through via coordinate transformations and using nearest neighbor relationships to capture object-level details and local contextual information, GFA sub-module uses self-attention mechanisms to selectively aggregate the features of the key voxels across the entire scene for capturing scene-level contextual information. Experiments on nuScenes and KITTI demonstrate the effectiveness of our method. Specifically, on nuScene, SparseDet surpasses the previous best sparse detector VoxelNeXt by 2.2% mAP with 13.5 FPS, and on KITTI, it surpasses VoxelNeXt by 1.12% $mathbf{AP_{3D}}$ on hard level tasks with 17.9 FPS.
Read more6/18/2024

0
RCBEVDet++: Toward High-accuracy Radar-Camera Fusion 3D Perception Network
Zhiwei Lin, Zhe Liu, Yongtao Wang, Le Zhang, Ce Zhu
Perceiving the surrounding environment is a fundamental task in autonomous driving. To obtain highly accurate perception results, modern autonomous driving systems typically employ multi-modal sensors to collect comprehensive environmental data. Among these, the radar-camera multi-modal perception system is especially favored for its excellent sensing capabilities and cost-effectiveness. However, the substantial modality differences between radar and camera sensors pose challenges in fusing information. To address this problem, this paper presents RCBEVDet, a radar-camera fusion 3D object detection framework. Specifically, RCBEVDet is developed from an existing camera-based 3D object detector, supplemented by a specially designed radar feature extractor, RadarBEVNet, and a Cross-Attention Multi-layer Fusion (CAMF) module. Firstly, RadarBEVNet encodes sparse radar points into a dense bird's-eye-view (BEV) feature using a dual-stream radar backbone and a Radar Cross Section aware BEV encoder. Secondly, the CAMF module utilizes a deformable attention mechanism to align radar and camera BEV features and adopts channel and spatial fusion layers to fuse them. To further enhance RCBEVDet's capabilities, we introduce RCBEVDet++, which advances the CAMF through sparse fusion, supports query-based multi-view camera perception models, and adapts to a broader range of perception tasks. Extensive experiments on the nuScenes show that our method integrates seamlessly with existing camera-based 3D perception models and improves their performance across various perception tasks. Furthermore, our method achieves state-of-the-art radar-camera fusion results in 3D object detection, BEV semantic segmentation, and 3D multi-object tracking tasks. Notably, with ViT-L as the image backbone, RCBEVDet++ achieves 72.73 NDS and 67.34 mAP in 3D object detection without test-time augmentation or model ensembling.
Read more9/10/2024