MUFASA: Multi-View Fusion and Adaptation Network with Spatial Awareness for Radar Object Detection

0
Sign in to get full access
Overview
- This paper proposes a novel multi-view fusion and adaptation network called MUFASA for radar-based 3D object detection.
- MUFASA leverages spatial awareness and multi-view fusion to improve the performance of radar-based 3D object detection for autonomous driving applications.
- The network architecture combines multiple radar views and adaptively fuses them to capture rich object features and spatial relationships.
Plain English Explanation
MUFASA is a new deep learning system that aims to improve 3D object detection using radar sensors for self-driving cars. Radar sensors can provide valuable 3D information about objects in the environment, but effectively using this data is challenging.
MUFASA addresses this by combining multiple "views" or perspectives from the radar sensor. It fuses these views in an adaptive way to capture rich details about the objects, like their shape and position. This allows MUFASA to detect 3D objects more accurately than previous radar-based systems.
The key idea is that by considering multiple viewpoints and how they relate to each other, MUFASA can build a more comprehensive understanding of the 3D environment. This spatial awareness is a crucial component for reliable object detection in autonomous driving scenarios.
Technical Explanation
The MUFASA architecture consists of several key components:
-
Multi-View Fusion: MUFASA takes radar point clouds from multiple views and fuses them together. This allows the model to leverage complementary information from different perspectives to build a more complete 3D representation of objects.
-
Spatial Awareness: The network is designed with spatial attention mechanisms that explicitly model the spatial relationships between different parts of the radar data. This spatial awareness helps the model better understand the 3D structure of objects.
-
Adaptive Fusion: MUFASA adaptively fuses the multi-view features based on their relative importance. This allows the model to dynamically weight the different views to optimize performance.
-
End-to-End Training: The entire MUFASA pipeline is trained in an end-to-end fashion, allowing the different components to be jointly optimized for 3D object detection.
The experiments in the paper demonstrate that MUFASA outperforms previous state-of-the-art radar-based 3D object detection methods on several benchmark datasets. The spatial awareness and multi-view fusion capabilities are shown to be key factors in this improved performance.
Critical Analysis
The paper provides a thorough technical explanation of the MUFASA architecture and its components. However, it does not deeply discuss potential limitations or areas for future research.
One potential concern is the computational complexity of the model, given the multi-view fusion and spatial attention mechanisms. The authors do not provide detailed runtime or memory usage analysis, which could be important for real-world autonomous driving applications with tight resource constraints.
Additionally, the paper only evaluates MUFASA on relatively small-scale datasets. Further testing on larger, more diverse datasets would help establish the generalizability of the approach.
Conclusion
Overall, the MUFASA paper presents a promising new approach for radar-based 3D object detection. The key innovations of multi-view fusion and spatial awareness show the potential to significantly improve the performance of this critical autonomous driving technology. While there are some unanswered questions, the results demonstrate the value of this research direction and its potential impact on the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MUFASA: Multi-View Fusion and Adaptation Network with Spatial Awareness for Radar Object Detection
Xiangyuan Peng, Miao Tang, Huawei Sun, Kay Bierzynski, Lorenzo Servadei, Robert Wille
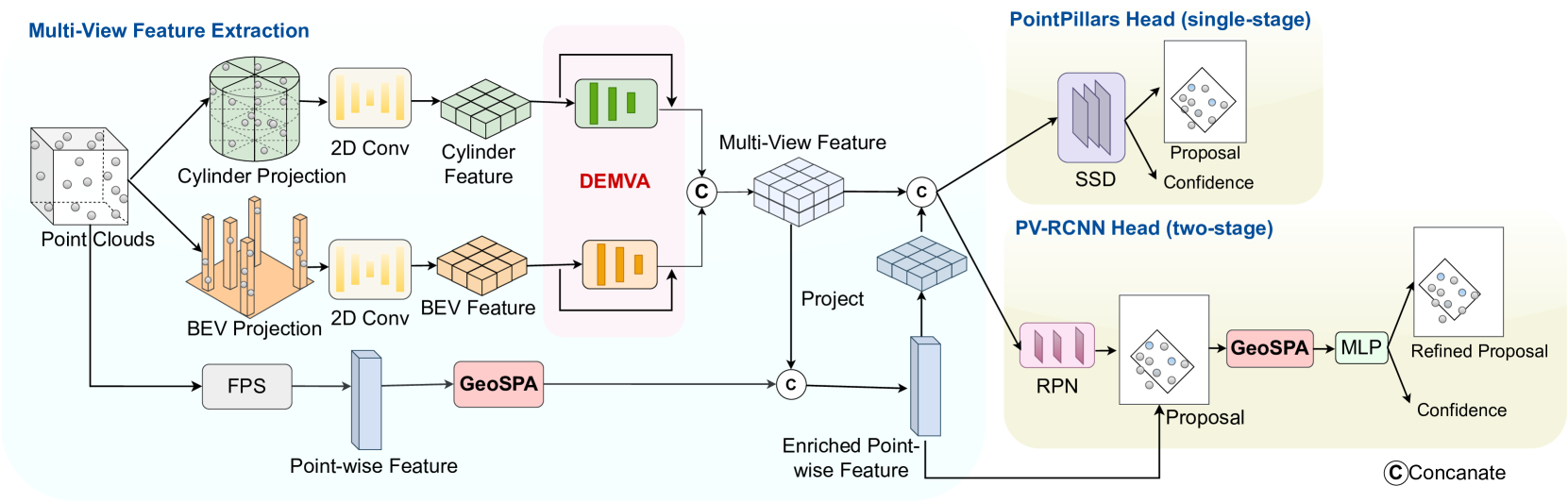
In recent years, approaches based on radar object detection have made significant progress in autonomous driving systems due to their robustness under adverse weather compared to LiDAR. However, the sparsity of radar point clouds poses challenges in achieving precise object detection, highlighting the importance of effective and comprehensive feature extraction technologies. To address this challenge, this paper introduces a comprehensive feature extraction method for radar point clouds. This study first enhances the capability of detection networks by using a plug-and-play module, GeoSPA. It leverages the Lalonde features to explore local geometric patterns. Additionally, a distributed multi-view attention mechanism, DEMVA, is designed to integrate the shared information across the entire dataset with the global information of each individual frame. By employing the two modules, we present our method, MUFASA, which enhances object detection performance through improved feature extraction. The approach is evaluated on the VoD and TJ4DRaDSet datasets to demonstrate its effectiveness. In particular, we achieve state-of-the-art results among radar-based methods on the VoD dataset with the mAP of 50.24%.
Read more8/2/2024

0
FADet: A Multi-sensor 3D Object Detection Network based on Local Featured Attention
Ziang Guo, Zakhar Yagudin, Selamawit Asfaw, Artem Lykov, Dzmitry Tsetserukou
Camera, LiDAR and radar are common perception sensors for autonomous driving tasks. Robust prediction of 3D object detection is optimally based on the fusion of these sensors. To exploit their abilities wisely remains a challenge because each of these sensors has its own characteristics. In this paper, we propose FADet, a multi-sensor 3D detection network, which specifically studies the characteristics of different sensors based on our local featured attention modules. For camera images, we propose dual-attention-based sub-module. For LiDAR point clouds, triple-attention-based sub-module is utilized while mixed-attention-based sub-module is applied for features of radar points. With local featured attention sub-modules, our FADet has effective detection results in long-tail and complex scenes from camera, LiDAR and radar input. On NuScenes validation dataset, FADet achieves state-of-the-art performance on LiDAR-camera object detection tasks with 71.8% NDS and 69.0% mAP, at the same time, on radar-camera object detection tasks with 51.7% NDS and 40.3% mAP. Code will be released at https://github.com/ZionGo6/FADet.
Read more5/21/2024

0
Deep Learning-Based Robust Multi-Object Tracking via Fusion of mmWave Radar and Camera Sensors
Lei Cheng, Arindam Sengupta, Siyang Cao
Autonomous driving holds great promise in addressing traffic safety concerns by leveraging artificial intelligence and sensor technology. Multi-Object Tracking plays a critical role in ensuring safer and more efficient navigation through complex traffic scenarios. This paper presents a novel deep learning-based method that integrates radar and camera data to enhance the accuracy and robustness of Multi-Object Tracking in autonomous driving systems. The proposed method leverages a Bi-directional Long Short-Term Memory network to incorporate long-term temporal information and improve motion prediction. An appearance feature model inspired by FaceNet is used to establish associations between objects across different frames, ensuring consistent tracking. A tri-output mechanism is employed, consisting of individual outputs for radar and camera sensors and a fusion output, to provide robustness against sensor failures and produce accurate tracking results. Through extensive evaluations of real-world datasets, our approach demonstrates remarkable improvements in tracking accuracy, ensuring reliable performance even in low-visibility scenarios.
Read more7/12/2024
0
Boosting 3D Object Detection with Semantic-Aware Multi-Branch Framework
Hao Jing, Anhong Wang, Lijun Zhao, Yakun Yang, Donghan Bu, Jing Zhang, Yifan Zhang, Junhui Hou
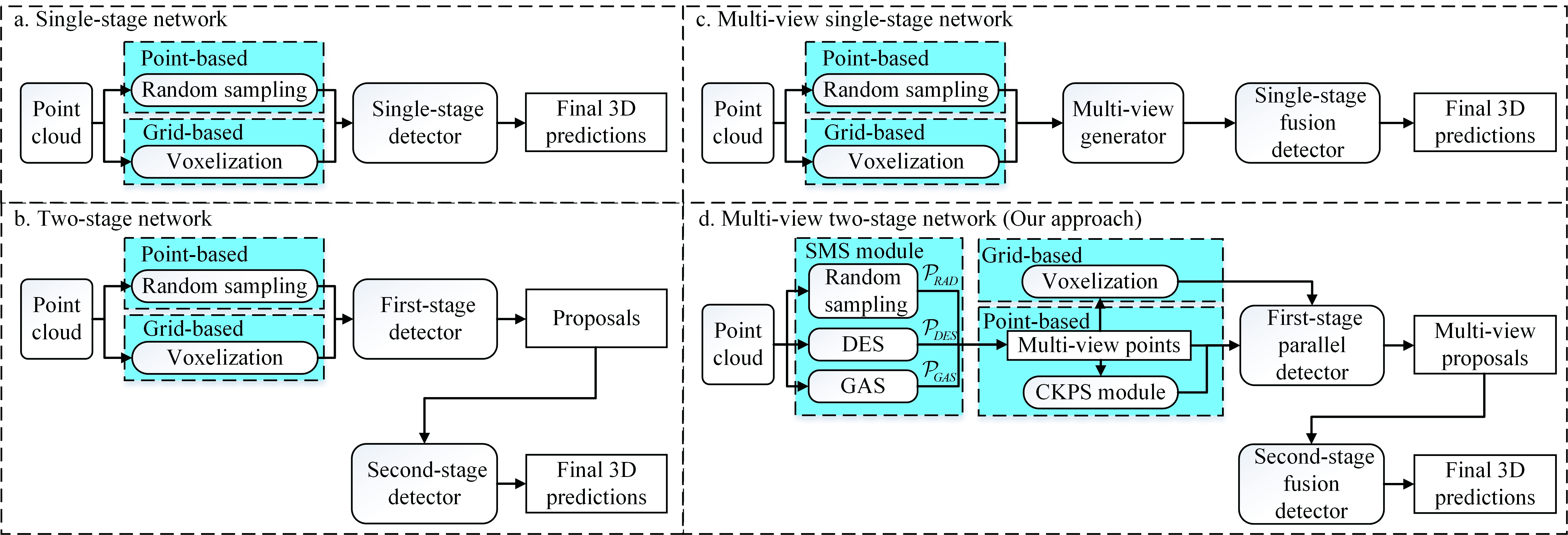
In autonomous driving, LiDAR sensors are vital for acquiring 3D point clouds, providing reliable geometric information. However, traditional sampling methods of preprocessing often ignore semantic features, leading to detail loss and ground point interference in 3D object detection. To address this, we propose a multi-branch two-stage 3D object detection framework using a Semantic-aware Multi-branch Sampling (SMS) module and multi-view consistency constraints. The SMS module includes random sampling, Density Equalization Sampling (DES) for enhancing distant objects, and Ground Abandonment Sampling (GAS) to focus on non-ground points. The sampled multi-view points are processed through a Consistent KeyPoint Selection (CKPS) module to generate consistent keypoint masks for efficient proposal sampling. The first-stage detector uses multi-branch parallel learning with multi-view consistency loss for feature aggregation, while the second-stage detector fuses multi-view data through a Multi-View Fusion Pooling (MVFP) module to precisely predict 3D objects. The experimental results on KITTI 3D object detection benchmark dataset show that our method achieves excellent detection performance improvement for a variety of backbones, especially for low-performance backbones with the simple network structures.
Read more7/9/2024