FAGhead: Fully Animate Gaussian Head from Monocular Videos
2406.19070
0
0
Abstract
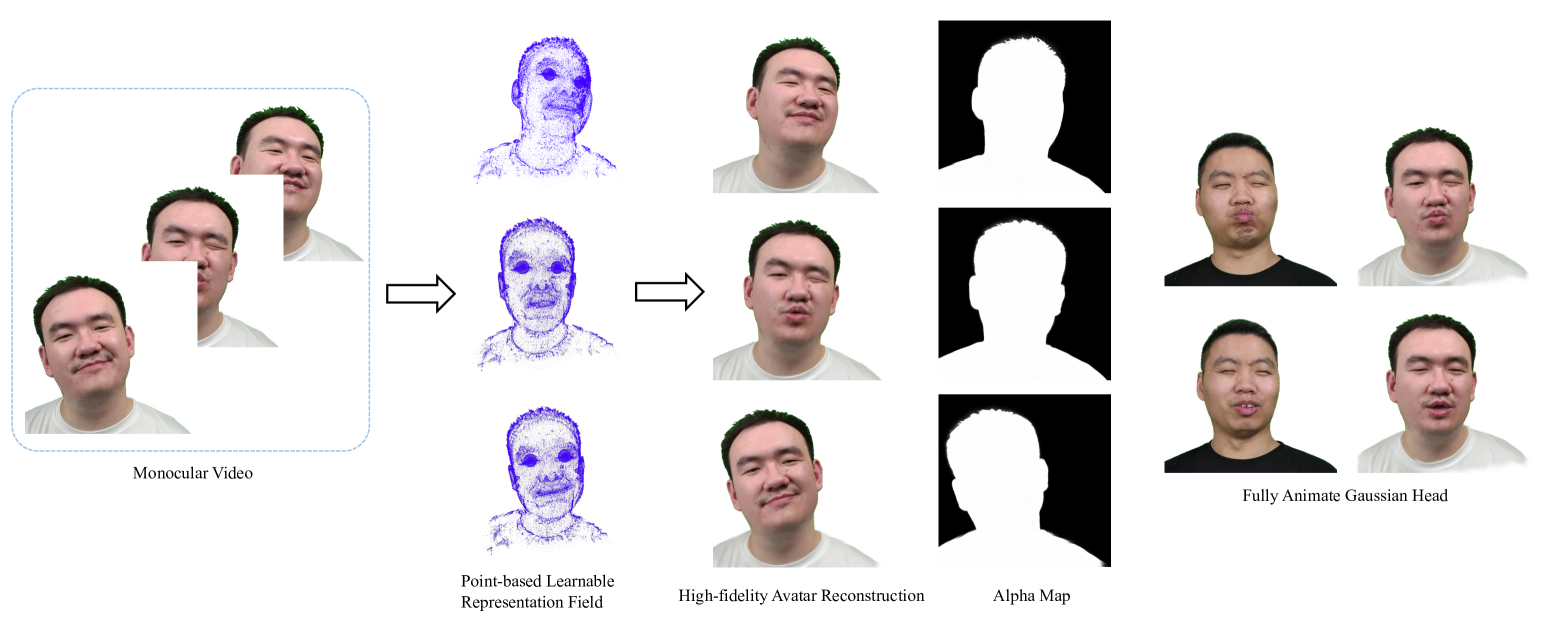
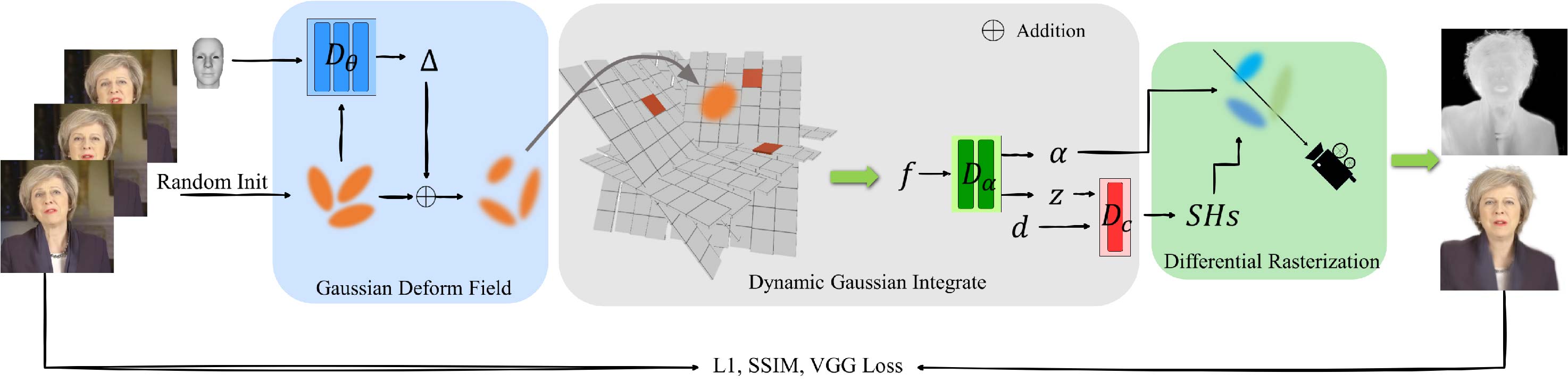
High-fidelity reconstruction of 3D human avatars has a wild application in visual reality. In this paper, we introduce FAGhead, a method that enables fully controllable human portraits from monocular videos. We explicit the traditional 3D morphable meshes (3DMM) and optimize the neutral 3D Gaussians to reconstruct with complex expressions. Furthermore, we employ a novel Point-based Learnable Representation Field (PLRF) with learnable Gaussian point positions to enhance reconstruction performance. Meanwhile, to effectively manage the edges of avatars, we introduced the alpha rendering to supervise the alpha value of each pixel. Extensive experimental results on the open-source datasets and our capturing datasets demonstrate that our approach is able to generate high-fidelity 3D head avatars and fully control the expression and pose of the virtual avatars, which is outperforming than existing works.
Create account to get full access
Overview
- This paper presents FAGhead, a novel method for fully animating Gaussian head models from monocular videos.
- The method can generate high-fidelity, animatable head avatars from a single input video, without requiring specialized hardware or capture setups.
- FAGhead builds upon prior work on Gaussian head avatars and efficient head animation, aiming to combine their advantages for better performance.
Plain English Explanation
The paper describes a new way to create animated 3D head models from regular video footage. The key idea is to use a Gaussian head model - a special type of 3D head shape that can be efficiently represented and animated. The FAGhead method takes a single video of a person's head and face, and automatically generates a fully animatable 3D head avatar that can be used for various applications, like virtual assistants, gaming, or AR/VR.
This is useful because creating high-quality, animated 3D head models typically requires specialized 3D scanning hardware or complex animation setups. FAGhead aims to make this process much simpler and more accessible, by only needing a regular video as input. The method builds on prior work on Gaussian head models and efficient head animation, combining their strengths to create a more advanced solution.
Technical Explanation
The key technical contributions of FAGhead are:
-
A neural network architecture that can regress a fully animatable Gaussian head model from a single input video of a person's head and face. This allows generating high-fidelity, 3D head avatars without the need for specialized capture setups.
-
A novel training strategy that uses a combination of self-supervision, differentiable rendering, and adversarial losses to ensure the generated head models are faithful to the input video and can be animated realistically.
-
Extensive experiments demonstrating that FAGhead outperforms state-of-the-art methods like GomAvatar and FlashAvatar in terms of animation quality, facial detail, and computational efficiency.
The paper also provides ablation studies and qualitative results to validate the effectiveness of the proposed approach.
Critical Analysis
One potential limitation of FAGhead is that it relies on the assumption that the input video captures a person's head and face in a relatively frontal pose. While the method claims to handle some variations in head pose, significant changes in viewing angle or occlusions may still pose challenges.
Additionally, the paper does not explore the generalization capabilities of the method to diverse populations, which is an important consideration for real-world applications. Further research may be needed to ensure the approach works robustly across different ages, ethnicities, and individual variations.
Overall, the FAGhead method represents a promising step towards more accessible and efficient creation of animatable 3D head avatars. However, as with any AI-based system, there may be limitations and potential biases that should be carefully considered and addressed in future work.
Conclusion
The FAGhead method introduced in this paper addresses an important problem in the field of 3D head avatar generation and animation. By leveraging Gaussian head models and a novel neural network architecture, the approach can create high-fidelity, fully animatable 3D head avatars from a single input video, without requiring specialized hardware or complex capture setups.
This innovation has the potential to make 3D head avatar creation more accessible and practical for a wide range of applications, from virtual assistants and game characters to augmented reality and telepresence systems. As the authors demonstrate, FAGhead outperforms state-of-the-art methods in terms of animation quality, facial detail, and computational efficiency.
While the method has some limitations, the core technical contributions and the promising results presented in this paper suggest that FAGhead represents a significant advancement in the field of 3D head avatar generation and animation. Further research and development in this area could lead to even more accessible and realistic solutions for creating virtual human representations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
GaussianHead: High-fidelity Head Avatars with Learnable Gaussian Derivation
Jie Wang, Jiu-Cheng Xie, Xianyan Li, Feng Xu, Chi-Man Pun, Hao Gao
0
0
Constructing vivid 3D head avatars for given subjects and realizing a series of animations on them is valuable yet challenging. This paper presents GaussianHead, which models the actional human head with anisotropic 3D Gaussians. In our framework, a motion deformation field and multi-resolution tri-plane are constructed respectively to deal with the head's dynamic geometry and complex texture. Notably, we impose an exclusive derivation scheme on each Gaussian, which generates its multiple doppelgangers through a set of learnable parameters for position transformation. With this design, we can compactly and accurately encode the appearance information of Gaussians, even those fitting the head's particular components with sophisticated structures. In addition, an inherited derivation strategy for newly added Gaussians is adopted to facilitate training acceleration. Extensive experiments show that our method can produce high-fidelity renderings, outperforming state-of-the-art approaches in reconstruction, cross-identity reenactment, and novel view synthesis tasks. Our code is available at: https://github.com/chiehwangs/gaussian-head.
5/31/2024
GoMAvatar: Efficient Animatable Human Modeling from Monocular Video Using Gaussians-on-Mesh
Jing Wen, Xiaoming Zhao, Zhongzheng Ren, Alexander G. Schwing, Shenlong Wang
0
0
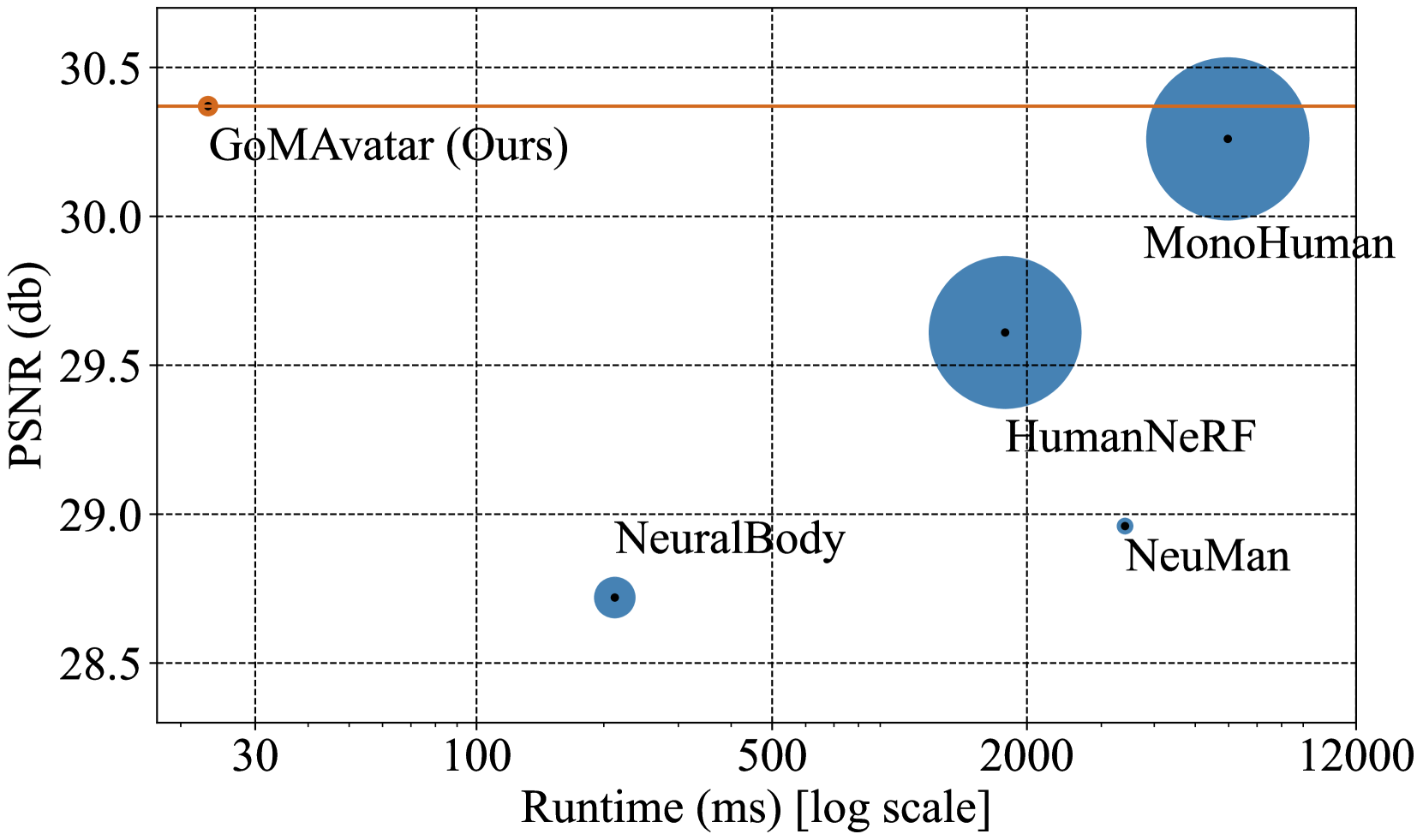
We introduce GoMAvatar, a novel approach for real-time, memory-efficient, high-quality animatable human modeling. GoMAvatar takes as input a single monocular video to create a digital avatar capable of re-articulation in new poses and real-time rendering from novel viewpoints, while seamlessly integrating with rasterization-based graphics pipelines. Central to our method is the Gaussians-on-Mesh representation, a hybrid 3D model combining rendering quality and speed of Gaussian splatting with geometry modeling and compatibility of deformable meshes. We assess GoMAvatar on ZJU-MoCap data and various YouTube videos. GoMAvatar matches or surpasses current monocular human modeling algorithms in rendering quality and significantly outperforms them in computational efficiency (43 FPS) while being memory-efficient (3.63 MB per subject).
4/12/2024
📊
FlashAvatar: High-fidelity Head Avatar with Efficient Gaussian Embedding
Jun Xiang, Xuan Gao, Yudong Guo, Juyong Zhang
0
0
We propose FlashAvatar, a novel and lightweight 3D animatable avatar representation that could reconstruct a digital avatar from a short monocular video sequence in minutes and render high-fidelity photo-realistic images at 300FPS on a consumer-grade GPU. To achieve this, we maintain a uniform 3D Gaussian field embedded in the surface of a parametric face model and learn extra spatial offset to model non-surface regions and subtle facial details. While full use of geometric priors can capture high-frequency facial details and preserve exaggerated expressions, proper initialization can help reduce the number of Gaussians, thus enabling super-fast rendering speed. Extensive experimental results demonstrate that FlashAvatar outperforms existing works regarding visual quality and personalized details and is almost an order of magnitude faster in rendering speed. Project page: https://ustc3dv.github.io/FlashAvatar/
4/1/2024

NPGA: Neural Parametric Gaussian Avatars
Simon Giebenhain, Tobias Kirschstein, Martin Runz, Lourdes Agapito, Matthias Nie{ss}ner
0
0
The creation of high-fidelity, digital versions of human heads is an important stepping stone in the process of further integrating virtual components into our everyday lives. Constructing such avatars is a challenging research problem, due to a high demand for photo-realism and real-time rendering performance. In this work, we propose Neural Parametric Gaussian Avatars (NPGA), a data-driven approach to create high-fidelity, controllable avatars from multi-view video recordings. We build our method around 3D Gaussian Splatting for its highly efficient rendering and to inherit the topological flexibility of point clouds. In contrast to previous work, we condition our avatars' dynamics on the rich expression space of neural parametric head models (NPHM), instead of mesh-based 3DMMs. To this end, we distill the backward deformation field of our underlying NPHM into forward deformations which are compatible with rasterization-based rendering. All remaining fine-scale, expression-dependent details are learned from the multi-view videos. To increase the representational capacity of our avatars, we augment the canonical Gaussian point cloud using per-primitive latent features which govern its dynamic behavior. To regularize this increased dynamic expressivity, we propose Laplacian terms on the latent features and predicted dynamics. We evaluate our method on the public NeRSemble dataset, demonstrating that NPGA significantly outperforms the previous state-of-the-art avatars on the self-reenactment task by 2.6 PSNR. Furthermore, we demonstrate accurate animation capabilities from real-world monocular videos.
5/30/2024