Fair Classification with Partial Feedback: An Exploration-Based Data Collection Approach
2402.11338
0
0
🏷️
Abstract
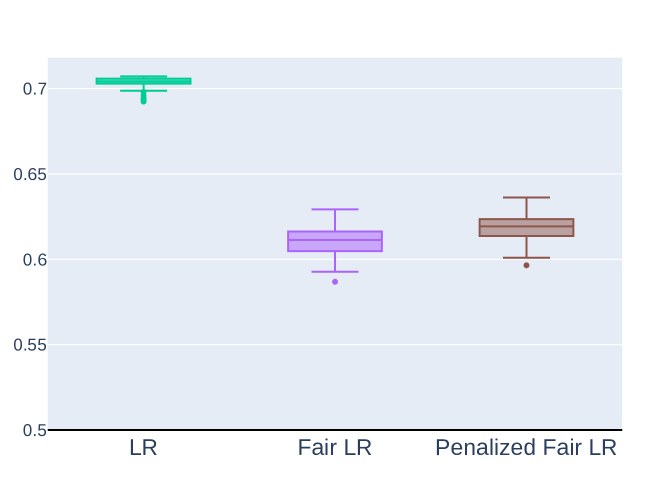
In many predictive contexts (e.g., credit lending), true outcomes are only observed for samples that were positively classified in the past. These past observations, in turn, form training datasets for classifiers that make future predictions. However, such training datasets lack information about the outcomes of samples that were (incorrectly) negatively classified in the past and can lead to erroneous classifiers. We present an approach that trains a classifier using available data and comes with a family of exploration strategies to collect outcome data about subpopulations that otherwise would have been ignored. For any exploration strategy, the approach comes with guarantees that (1) all sub-populations are explored, (2) the fraction of false positives is bounded, and (3) the trained classifier converges to a ``desired'' classifier. The right exploration strategy is context-dependent; it can be chosen to improve learning guarantees and encode context-specific group fairness properties. Evaluation on real-world datasets shows that this approach consistently boosts the quality of collected outcome data and improves the fraction of true positives for all groups, with only a small reduction in predictive utility.
Create account to get full access
Overview
- Predictive models, like those used for credit lending decisions, often have limited data on negative outcomes due to past biases in classification.
- This can lead to erroneous models that perpetuate those biases.
- The paper presents an approach to train a classifier while actively collecting data on underrepresented subpopulations to improve the model.
- The approach provides guarantees around exploring all subpopulations, bounding false positives, and converging to a "desired" classifier.
- The exploration strategy can be chosen to improve learning and incorporate fairness considerations.
- Evaluations show this approach boosts data quality and true positive rates across groups, with only a small reduction in predictive utility.
Plain English Explanation
In many predictive tasks, such as deciding who should be granted a loan, the data available for training models is often biased. This is because the model only has information about people who were approved for loans in the past, while knowing little about those who were denied.
This lack of information on "negative" outcomes can lead the model to make inaccurate predictions, potentially perpetuating the same biases present in the historical data.
The researchers in this paper propose an approach to address this issue. Their method trains a classifier using the available data, but also includes strategies to actively collect outcome data on subgroups that would otherwise be overlooked.
This "exploration" process comes with important guarantees - it ensures all subpopulations are examined, limits the fraction of false positive classifications, and ensures the final trained model converges to a "desired" classifier.
Importantly, the exploration strategy can be tailored to the specific context, allowing incorporation of fairness considerations. For example, the exploration could prioritize underrepresented groups to improve equity.
Evaluations on real-world datasets show this approach consistently improves the quality of the collected data and increases the true positive rate across different groups, with only a small reduction in the model's overall predictive performance.
Technical Explanation
The key technical insight of this paper is that in many predictive contexts, the training data available to machine learning models is inherently biased due to past decisions to grant or deny access to the "true" outcome information.
For example, in credit lending, the model only has data on the repayment behavior of applicants who were approved for loans in the past. It lacks information on the outcomes of those who were incorrectly denied loans previously.
This "selective labels" problem can lead to erroneous classifiers that perpetuate historical biases. To address this, the authors propose an approach that trains a classifier using the available data, but also includes a family of exploration strategies to actively collect outcome data on underrepresented subpopulations.
The exploration strategies come with several key guarantees:
- All subpopulations will be explored to some degree, ensuring comprehensive data collection.
- The fraction of false positive classifications will be bounded, limiting harm.
- The trained classifier will converge to a "desired" classifier, defined by the specific context and fairness objectives.
The right exploration strategy is context-dependent and can be chosen to improve learning guarantees and incorporate group fairness properties. For example, the exploration could prioritize data collection on disadvantaged groups to improve equitable model performance.
Evaluations on real-world datasets show this approach consistently improves the quality of the collected data and the true positive rate across different groups, with only a small reduction in overall predictive utility. This demonstrates the value of the proposed method in addressing the selective labels problem and training fairer, more accurate predictive models.
Critical Analysis
The paper presents a compelling technical approach to address the selective labels problem, which is a significant challenge in many real-world predictive contexts. The theoretical guarantees around exploration, false positive rates, and model convergence are particularly valuable.
However, the authors acknowledge several limitations and areas for further research. For example, the approach assumes the existence of a "desired" classifier, which may be difficult to define in practice, especially when considering complex notions of fairness. Differentially Private Fair Binary Classifications and Intrinsic Fairness-Accuracy Tradeoffs under Equalized Odds explore related challenges in defining and achieving fairness in predictive models.
Additionally, the evaluation is limited to a few real-world datasets, and the authors note that the effectiveness of the exploration strategies may depend on the specific context and dataset characteristics. Further research is needed to understand how the approach generalizes to a wider range of applications and data environments.
Another potential concern is the practical implementation and deployment of the proposed exploration strategies. While the theoretical foundations are solid, the operational details of how to collect additional outcome data in a real-world setting may present significant challenges, such as obtaining user consent, managing ethical and legal considerations, and ensuring the exploration process does not cause unintended harm.
Overall, this paper presents an important and technically rigorous contribution to the growing body of research on addressing selective labels and fairness in predictive modeling. The proposed approach offers a promising direction, but further work is needed to fully understand its broader applicability and practical implications.
Conclusion
This paper tackles the critical challenge of selective labels in predictive modeling, where training data is inherently biased due to past decisions to grant or deny access to "true" outcome information. The authors present an approach that trains a classifier using available data, while also including exploration strategies to actively collect outcome data on underrepresented subpopulations.
The key strengths of this approach are the theoretical guarantees around exploring all subpopulations, bounding false positive rates, and converging to a "desired" classifier. Importantly, the exploration strategy can be tailored to the specific context, allowing for the incorporation of fairness considerations.
Evaluations on real-world datasets demonstrate the method's ability to consistently improve the quality of collected data and increase true positive rates across different groups, with only a small reduction in overall predictive utility. This highlights the value of the proposed technique in addressing selective labels and training fairer, more accurate predictive models.
While the paper presents a compelling technical contribution, further research is needed to fully understand the broader applicability of the approach, the practical challenges of implementation, and the nuances of defining "desired" classifiers in complex real-world settings. Nonetheless, this work represents an important step forward in the ongoing effort to develop more equitable and reliable predictive systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Fair Generalized Linear Mixed Models
Jan Pablo Burgard, Jo~ao Vitor Pamplona
0
0
When using machine learning for automated prediction, it is important to account for fairness in the prediction. Fairness in machine learning aims to ensure that biases in the data and model inaccuracies do not lead to discriminatory decisions. E.g., predictions from fair machine learning models should not discriminate against sensitive variables such as sexual orientation and ethnicity. The training data often in obtained from social surveys. In social surveys, oftentimes the data collection process is a strata sampling, e.g. due to cost restrictions. In strata samples, the assumption of independence between the observation is not fulfilled. Hence, if the machine learning models do not account for the strata correlations, the results may be biased. Especially high is the bias in cases where the strata assignment is correlated to the variable of interest. We present in this paper an algorithm that can handle both problems simultaneously, and we demonstrate the impact of stratified sampling on the quality of fair machine learning predictions in a reproducible simulation study.
5/24/2024
Fairness Without Harm: An Influence-Guided Active Sampling Approach
Jinlong Pang, Jialu Wang, Zhaowei Zhu, Yuanshun Yao, Chen Qian, Yang Liu
0
0
The pursuit of fairness in machine learning (ML), ensuring that the models do not exhibit biases toward protected demographic groups, typically results in a compromise scenario. This compromise can be explained by a Pareto frontier where given certain resources (e.g., data), reducing the fairness violations often comes at the cost of lowering the model accuracy. In this work, we aim to train models that mitigate group fairness disparity without causing harm to model accuracy. Intuitively, acquiring more data is a natural and promising approach to achieve this goal by reaching a better Pareto frontier of the fairness-accuracy tradeoff. The current data acquisition methods, such as fair active learning approaches, typically require annotating sensitive attributes. However, these sensitive attribute annotations should be protected due to privacy and safety concerns. In this paper, we propose a tractable active data sampling algorithm that does not rely on training group annotations, instead only requiring group annotations on a small validation set. Specifically, the algorithm first scores each new example by its influence on fairness and accuracy evaluated on the validation dataset, and then selects a certain number of examples for training. We theoretically analyze how acquiring more data can improve fairness without causing harm, and validate the possibility of our sampling approach in the context of risk disparity. We also provide the upper bound of generalization error and risk disparity as well as the corresponding connections. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.
6/4/2024
🏅
Differentially Private Fair Binary Classifications
Hrad Ghoukasian, Shahab Asoodeh
0
0
In this work, we investigate binary classification under the constraints of both differential privacy and fairness. We first propose an algorithm based on the decoupling technique for learning a classifier with only fairness guarantee. This algorithm takes in classifiers trained on different demographic groups and generates a single classifier satisfying statistical parity. We then refine this algorithm to incorporate differential privacy. The performance of the final algorithm is rigorously examined in terms of privacy, fairness, and utility guarantees. Empirical evaluations conducted on the Adult and Credit Card datasets illustrate that our algorithm outperforms the state-of-the-art in terms of fairness guarantees, while maintaining the same level of privacy and utility.
5/21/2024
🎲
Intrinsic Fairness-Accuracy Tradeoffs under Equalized Odds
Meiyu Zhong, Ravi Tandon
0
0
With the growing adoption of machine learning (ML) systems in areas like law enforcement, criminal justice, finance, hiring, and admissions, it is increasingly critical to guarantee the fairness of decisions assisted by ML. In this paper, we study the tradeoff between fairness and accuracy under the statistical notion of equalized odds. We present a new upper bound on the accuracy (that holds for any classifier), as a function of the fairness budget. In addition, our bounds also exhibit dependence on the underlying statistics of the data, labels and the sensitive group attributes. We validate our theoretical upper bounds through empirical analysis on three real-world datasets: COMPAS, Adult, and Law School. Specifically, we compare our upper bound to the tradeoffs that are achieved by various existing fair classifiers in the literature. Our results show that achieving high accuracy subject to a low-bias could be fundamentally limited based on the statistical disparity across the groups.
5/17/2024