Stable Diffusion Dataset Generation for Downstream Classification Tasks
2405.02698
0
0
Abstract
Recent advances in generative artificial intelligence have enabled the creation of high-quality synthetic data that closely mimics real-world data. This paper explores the adaptation of the Stable Diffusion 2.0 model for generating synthetic datasets, using Transfer Learning, Fine-Tuning and generation parameter optimisation techniques to improve the utility of the dataset for downstream classification tasks. We present a class-conditional version of the model that exploits a Class-Encoder and optimisation of key generation parameters. Our methodology led to synthetic datasets that, in a third of cases, produced models that outperformed those trained on real datasets.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the generation of a synthetic dataset using Stable Diffusion, a powerful text-to-image diffusion model, for downstream classification tasks.
- The researchers aim to investigate the potential of leveraging synthetic data to enhance the performance of classification models in various domains.
- The study examines the similarities and differences between synthetic and real-world data, and how the transfer of knowledge from synthetic to real-world data can be effectively utilized.
Plain English Explanation
The researchers in this paper are exploring a way to create artificial, or synthetic, images using a machine learning model called Stable Diffusion. Stable Diffusion is a powerful model that can generate images from text descriptions. The researchers want to see if they can use these synthetic images to help train other machine learning models, specifically for the task of image classification.
Image classification is the process of identifying what is in an image, such as recognizing objects, people, or scenes. The researchers want to investigate whether using synthetic data generated by Stable Diffusion can improve the performance of classification models, compared to using only real-world, human-created images for training.
The key idea is that by having a large, diverse set of synthetic images, the classification models might be able to learn more effectively and generalize better to real-world data. This could be especially useful in domains where it's difficult or expensive to collect a lot of real-world training data.
The researchers will explore the similarities and differences between the synthetic and real-world data, and how the knowledge gained from the synthetic data can be transferred to improve the real-world classification models. This relates to the concept of transfer learning, where knowledge gained on one task can be applied to a different but related task.
Technical Explanation
The researchers in this paper investigate the use of synthetic data generated by the Stable Diffusion text-to-image diffusion model for downstream classification tasks. They aim to understand the mind gap between synthetic and real-world data, and how the transfer of knowledge from synthetic to real-world data can be effectively utilized.
The paper explores the stability and scalability of the Stable Diffusion model in generating high-quality synthetic images for various classification tasks. The researchers analyze the similarities and differences between the synthetic and real-world data, and investigate strategies for leveraging the synthetic data to enhance the performance of classification models.
The study involves a thorough experimental evaluation, where the researchers train classification models using both synthetic and real-world data, and compare their performance on various benchmark datasets. The findings provide insights into the effectiveness of using synthetic data generated by Stable Diffusion to improve the accuracy and robustness of downstream classification models.
Critical Analysis
The paper presents a well-designed study that explores the potential of using synthetic data generated by Stable Diffusion to enhance the performance of classification models. The researchers have carefully considered the similarities and differences between the synthetic and real-world data, and have proposed strategies for effectively utilizing the synthetic data.
One potential limitation of the study is the reliance on the Stable Diffusion model, which may have inherent biases or limitations in the types of images it can generate. The researchers acknowledge this concern and suggest further investigation into the diversity and realism of the synthetic data.
Additionally, the paper does not delve deeply into the potential societal implications of using synthetic data for training classification models, such as the risk of perpetuating biases or the ethical considerations around the use of AI-generated content. These aspects could be explored in future research.
Overall, the paper presents a valuable contribution to the field of machine learning, demonstrating the potential of leveraging synthetic data to enhance the performance of classification models. The findings have significant implications for various applications, from computer vision to medical imaging, and encourage further exploration of the interplay between synthetic and real-world data in the context of deep learning.
Conclusion
This paper explores the use of synthetic data generated by the Stable Diffusion text-to-image diffusion model to enhance the performance of downstream classification tasks. The researchers investigate the similarities and differences between synthetic and real-world data, and propose strategies for effectively transferring knowledge from the synthetic data to improve the accuracy and robustness of classification models.
The study provides valuable insights into the potential of leveraging synthetic data to address challenges in data-scarce domains, where the collection of real-world training data is difficult or expensive. The findings have broad implications for various applications of machine learning, highlighting the importance of understanding the relationship between synthetic and real-world data, and the effective utilization of generative models like Stable Diffusion.
As the field of AI continues to advance, the use of synthetic data in training and evaluating classification models is an area that warrants further exploration and research. The insights gained from this paper can inform future work on bridging the gap between synthetic and real-world data, ultimately contributing to the development of more robust and reliable machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
Mind the Gap Between Synthetic and Real: Utilizing Transfer Learning to Probe the Boundaries of Stable Diffusion Generated Data
Leonhard Hennicke, Christian Medeiros Adriano, Holger Giese, Jan Mathias Koehler, Lukas Schott
0
0
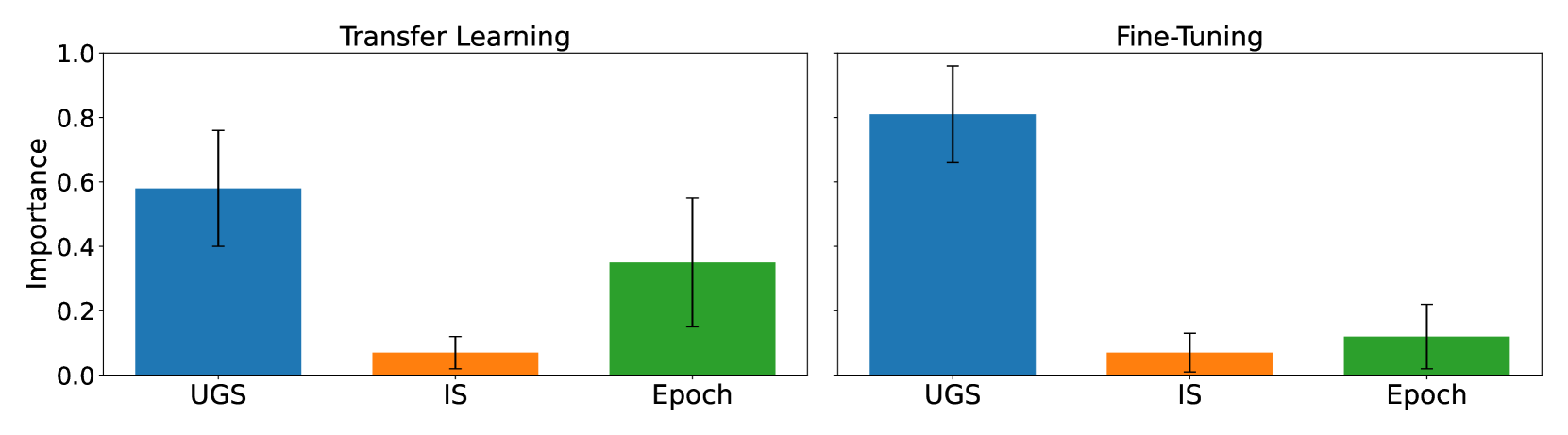
Generative foundation models like Stable Diffusion comprise a diverse spectrum of knowledge in computer vision with the potential for transfer learning, e.g., via generating data to train student models for downstream tasks. This could circumvent the necessity of collecting labeled real-world data, thereby presenting a form of data-free knowledge distillation. However, the resultant student models show a significant drop in accuracy compared to models trained on real data. We investigate possible causes for this drop and focus on the role of the different layers of the student model. By training these layers using either real or synthetic data, we reveal that the drop mainly stems from the model's final layers. Further, we briefly investigate other factors, such as differences in data-normalization between synthetic and real, the impact of data augmentations, texture vs. shape learning, and assuming oracle prompts. While we find that some of those factors can have an impact, they are not sufficient to close the gap towards real data. Building upon our insights that mainly later layers are responsible for the drop, we investigate the data-efficiency of fine-tuning a synthetically trained model with real data applied to only those last layers. Our results suggest an improved trade-off between the amount of real training data used and the model's accuracy. Our findings contribute to the understanding of the gap between synthetic and real data and indicate solutions to mitigate the scarcity of labeled real data.
5/7/2024
🔄
Diffusion Deepfake
Chaitali Bhattacharyya, Hanxiao Wang, Feng Zhang, Sungho Kim, Xiatian Zhu
0
0
Recent progress in generative AI, primarily through diffusion models, presents significant challenges for real-world deepfake detection. The increased realism in image details, diverse content, and widespread accessibility to the general public complicates the identification of these sophisticated deepfakes. Acknowledging the urgency to address the vulnerability of current deepfake detectors to this evolving threat, our paper introduces two extensive deepfake datasets generated by state-of-the-art diffusion models as other datasets are less diverse and low in quality. Our extensive experiments also showed that our dataset is more challenging compared to the other face deepfake datasets. Our strategic dataset creation not only challenge the deepfake detectors but also sets a new benchmark for more evaluation. Our comprehensive evaluation reveals the struggle of existing detection methods, often optimized for specific image domains and manipulations, to effectively adapt to the intricate nature of diffusion deepfakes, limiting their practical utility. To address this critical issue, we investigate the impact of enhancing training data diversity on representative detection methods. This involves expanding the diversity of both manipulation techniques and image domains. Our findings underscore that increasing training data diversity results in improved generalizability. Moreover, we propose a novel momentum difficulty boosting strategy to tackle the additional challenge posed by training data heterogeneity. This strategy dynamically assigns appropriate sample weights based on learning difficulty, enhancing the model's adaptability to both easy and challenging samples. Extensive experiments on both existing and newly proposed benchmarks demonstrate that our model optimization approach surpasses prior alternatives significantly.
4/3/2024
Remote Diffusion
Kunal Sunil Kasodekar
0
0
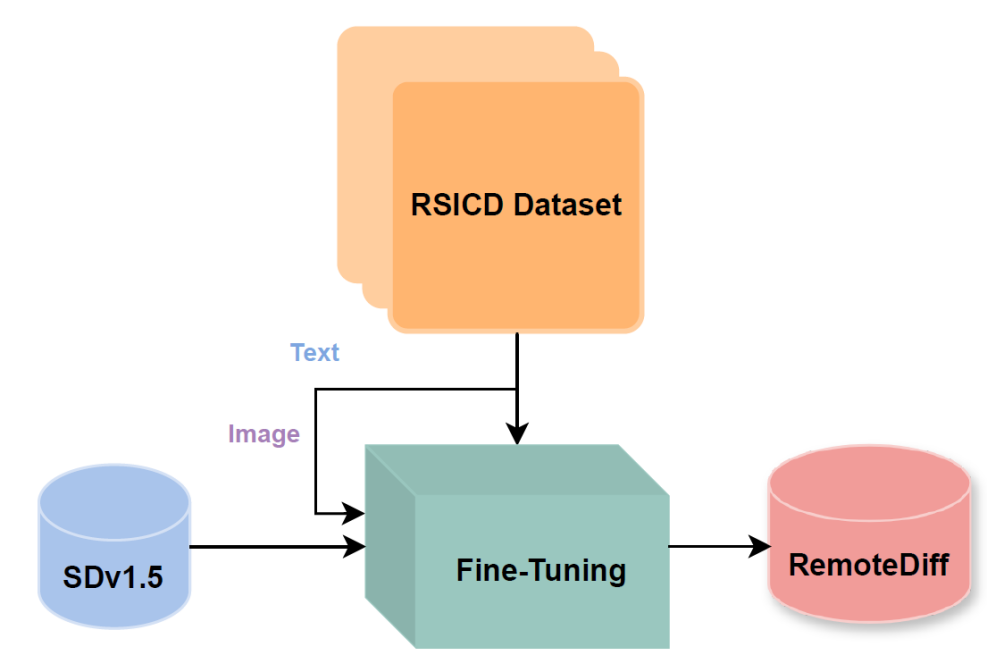
I explored adapting Stable Diffusion v1.5 for generating domain-specific satellite and aerial images in remote sensing. Recognizing the limitations of existing models like Midjourney and Stable Diffusion, trained primarily on natural RGB images and lacking context for remote sensing, I used the RSICD dataset to train a Stable Diffusion model with a loss of 0.2. I incorporated descriptive captions from the dataset for text-conditioning. Additionally, I created a synthetic dataset for a Land Use Land Classification (LULC) task, employing prompting techniques with RAG and ChatGPT and fine-tuning a specialized remote sensing LLM. However, I faced challenges with prompt quality and model performance. I trained a classification model (ResNet18) on the synthetic dataset achieving 49.48% test accuracy in TorchGeo to create a baseline. Quantitative evaluation through FID scores and qualitative feedback from domain experts assessed the realism and quality of the generated images and dataset. Despite extensive fine-tuning and dataset iterations, results indicated subpar image quality and realism, as indicated by high FID scores and domain-expert evaluation. These findings call attention to the potential of diffusion models in remote sensing while highlighting significant challenges related to insufficient pretraining data and computational resources.
5/9/2024
📊
On the Stability of Iterative Retraining of Generative Models on their own Data
Quentin Bertrand, Avishek Joey Bose, Alexandre Duplessis, Marco Jiralerspong, Gauthier Gidel
0
0
Deep generative models have made tremendous progress in modeling complex data, often exhibiting generation quality that surpasses a typical human's ability to discern the authenticity of samples. Undeniably, a key driver of this success is enabled by the massive amounts of web-scale data consumed by these models. Due to these models' striking performance and ease of availability, the web will inevitably be increasingly populated with synthetic content. Such a fact directly implies that future iterations of generative models will be trained on both clean and artificially generated data from past models. In this paper, we develop a framework to rigorously study the impact of training generative models on mixed datasets -- from classical training on real data to self-consuming generative models trained on purely synthetic data. We first prove the stability of iterative training under the condition that the initial generative models approximate the data distribution well enough and the proportion of clean training data (w.r.t. synthetic data) is large enough. We empirically validate our theory on both synthetic and natural images by iteratively training normalizing flows and state-of-the-art diffusion models on CIFAR10 and FFHQ.
4/3/2024