Balanced Mixed-Type Tabular Data Synthesis with Diffusion Models
2404.08254
0
0

Abstract
Diffusion models have emerged as a robust framework for various generative tasks, such as image and audio synthesis, and have also demonstrated a remarkable ability to generate mixed-type tabular data comprising both continuous and discrete variables. However, current approaches to training diffusion models on mixed-type tabular data tend to inherit the imbalanced distributions of features present in the training dataset, which can result in biased sampling. In this research, we introduce a fair diffusion model designed to generate balanced data on sensitive attributes. We present empirical evidence demonstrating that our method effectively mitigates the class imbalance in training data while maintaining the quality of the generated samples. Furthermore, we provide evidence that our approach outperforms existing methods for synthesizing tabular data in terms of performance and fairness.
Create account to get full access
Overview
- This paper presents a novel approach for synthesizing balanced mixed-type tabular data using diffusion models.
- Diffusion models are a type of generative AI model that can be used to generate new data that is similar to the training data.
- The key innovation of this work is the ability to handle mixed-type data, which includes both continuous and categorical variables, and ensure the generated data is balanced across all variables.
Plain English Explanation
Imagine you have a dataset with information about people, including their age, income, and whether they have a college degree or not. This is an example of mixed-type data, as age is a continuous variable, income is also continuous, and having a college degree is a categorical variable.
The researchers in this paper developed a new way to generate synthetic data that mimics the original dataset, but without revealing any real people's information. This is useful for testing machine learning models or sharing data without compromising privacy.
The key insight is that the researchers used a type of AI model called a diffusion model, which learns the underlying patterns in the data and can then generate new, realistic-looking samples. Importantly, they ensured that the generated data maintains the same balance between the different types of variables (continuous and categorical) as the original dataset.
This is a significant advance over previous methods, which often struggled to handle mixed-type data or maintain the right balance between variables in the synthetic data.
Technical Explanation
The core of this work is the development of a diffusion model-based approach for synthesizing balanced mixed-type tabular data. Diffusion models are a powerful class of generative AI models that have shown impressive results in generating high-quality synthetic data.
The key technical contributions are:
- A novel diffusion model architecture that can handle both continuous and categorical variables in the input data.
- A training procedure that explicitly enforces balance between the different variable types in the generated samples.
- Extensive experiments demonstrating the effectiveness of the proposed approach on a range of real-world datasets, showing improvements over previous state-of-the-art methods.
The authors leverage recent advances in diffusion-based generation to develop a flexible and scalable framework for tabular data synthesis. By carefully designing the diffusion process and the model architecture, they are able to capture the complex dependencies between the mixed-type variables and generate realistic synthetic data that maintains the original data's statistical properties.
Critical Analysis
The authors have done a thorough job of evaluating their proposed method and highlighting its strengths compared to prior work. However, there are a few potential limitations and areas for further research:
- The authors focus on tabular data with a relatively small number of variables (up to 50). It would be interesting to see how the method scales to datasets with a larger number of mixed-type features.
- While the authors demonstrate the utility of the generated data for downstream machine learning tasks, they do not explore the potential privacy implications of using diffusion models for data synthesis. Further research is needed to understand the privacy guarantees and potential risks of this approach.
- The current method assumes that the input data is already balanced. It would be valuable to explore extensions that can handle imbalanced datasets and still generate balanced synthetic data.
Overall, this is a well-executed piece of research that advances the state of the art in mixed-type tabular data synthesis. The authors have made an important contribution to the field of generative AI and its applications in data privacy and machine learning.
Conclusion
This paper presents a novel diffusion model-based approach for generating balanced mixed-type tabular data. The key innovation is the ability to handle both continuous and categorical variables, while ensuring that the statistical properties of the original data are preserved in the synthetic samples.
The authors demonstrate the effectiveness of their method on a range of real-world datasets, showing improvements over previous state-of-the-art techniques. This work has important implications for data privacy, as the generated synthetic data can be used as a substitute for the original dataset without compromising sensitive information.
Looking ahead, further research is needed to explore the scalability of this approach and its potential privacy implications. Nevertheless, this paper represents a significant step forward in the field of tabular data synthesis and generative AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space
Hengrui Zhang, Jiani Zhang, Balasubramaniam Srinivasan, Zhengyuan Shen, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, George Karypis
0
0
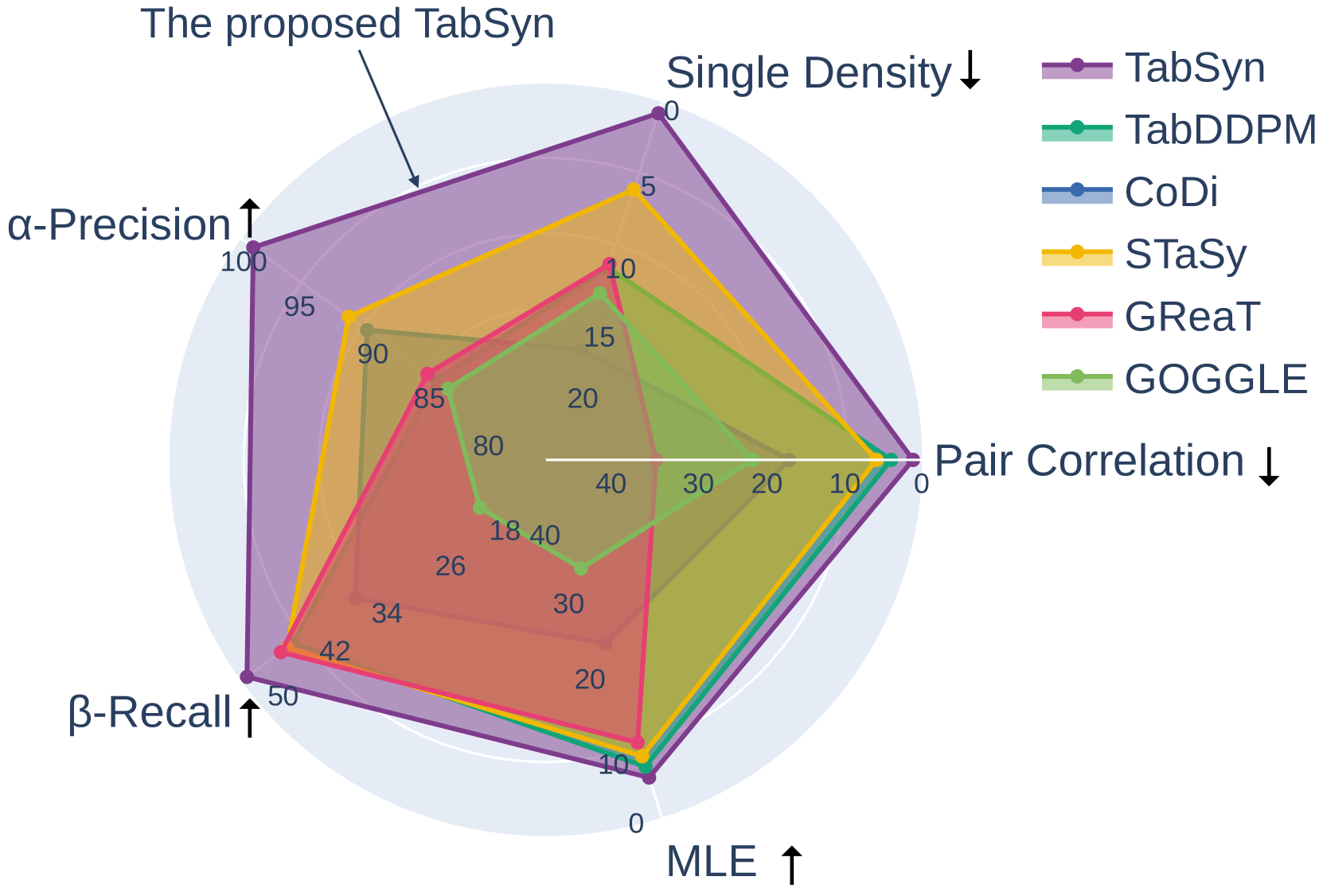
Recent advances in tabular data generation have greatly enhanced synthetic data quality. However, extending diffusion models to tabular data is challenging due to the intricately varied distributions and a blend of data types of tabular data. This paper introduces Tabsyn, a methodology that synthesizes tabular data by leveraging a diffusion model within a variational autoencoder (VAE) crafted latent space. The key advantages of the proposed Tabsyn include (1) Generality: the ability to handle a broad spectrum of data types by converting them into a single unified space and explicitly capture inter-column relations; (2) Quality: optimizing the distribution of latent embeddings to enhance the subsequent training of diffusion models, which helps generate high-quality synthetic data, (3) Speed: much fewer number of reverse steps and faster synthesis speed than existing diffusion-based methods. Extensive experiments on six datasets with five metrics demonstrate that Tabsyn outperforms existing methods. Specifically, it reduces the error rates by 86% and 67% for column-wise distribution and pair-wise column correlation estimations compared with the most competitive baselines.
5/14/2024

Continuous Diffusion for Mixed-Type Tabular Data
Markus Mueller, Kathrin Gruber, Dennis Fok
0
0
Score-based generative models (or diffusion models for short) have proven successful for generating text and image data. However, the adaption of this model family to tabular data of mixed-type has fallen short so far. In this paper, we propose CDTD, a Continuous Diffusion model for mixed-type Tabular Data. Specifically, we combine score matching and score interpolation to ensure a common continuous noise distribution for both continuous and categorical features alike. We counteract the high heterogeneity inherent to data of mixed-type with distinct, adaptive noise schedules per feature or per data type. The learnable noise schedules ensure optimally allocated model capacity and balanced generative capability. We homogenize the data types further with model-specific loss calibration and initialization schemes tailored to mixed-type tabular data. Our experimental results show that CDTD consistently outperforms state-of-the-art benchmark models, captures feature correlations exceptionally well, and that heterogeneity in the noise schedule design boosts the sample quality.
5/28/2024

Fair Data Generation via Score-based Diffusion Model
Yujie Lin, Dong Li, Chen Zhao, Minglai Shao
0
0
The fairness of AI decision-making has garnered increasing attention, leading to the proposal of numerous fairness algorithms. In this paper, we aim not to address this issue by directly introducing fair learning algorithms, but rather by generating entirely new, fair synthetic data from biased datasets for use in any downstream tasks. Additionally, the distribution of test data may differ from that of the training set, potentially impacting the performance of the generated synthetic data in downstream tasks. To address these two challenges, we propose a diffusion model-based framework, FADM: Fairness-Aware Diffusion with Meta-training. FADM introduces two types of gradient induction during the sampling phase of the diffusion model: one to ensure that the generated samples belong to the desired target categories, and another to make the sensitive attributes of the generated samples difficult to classify into any specific sensitive attribute category. To overcome data distribution shifts in the test environment, we train the diffusion model and the two classifiers used for induction within a meta-learning framework. Compared to other baselines, FADM allows for flexible control over the categories of the generated samples and exhibits superior generalization capability. Experiments on real datasets demonstrate that FADM achieves better accuracy and optimal fairness in downstream tasks.
6/17/2024
Differentially Private Tabular Data Synthesis using Large Language Models
Toan V. Tran, Li Xiong
0
0
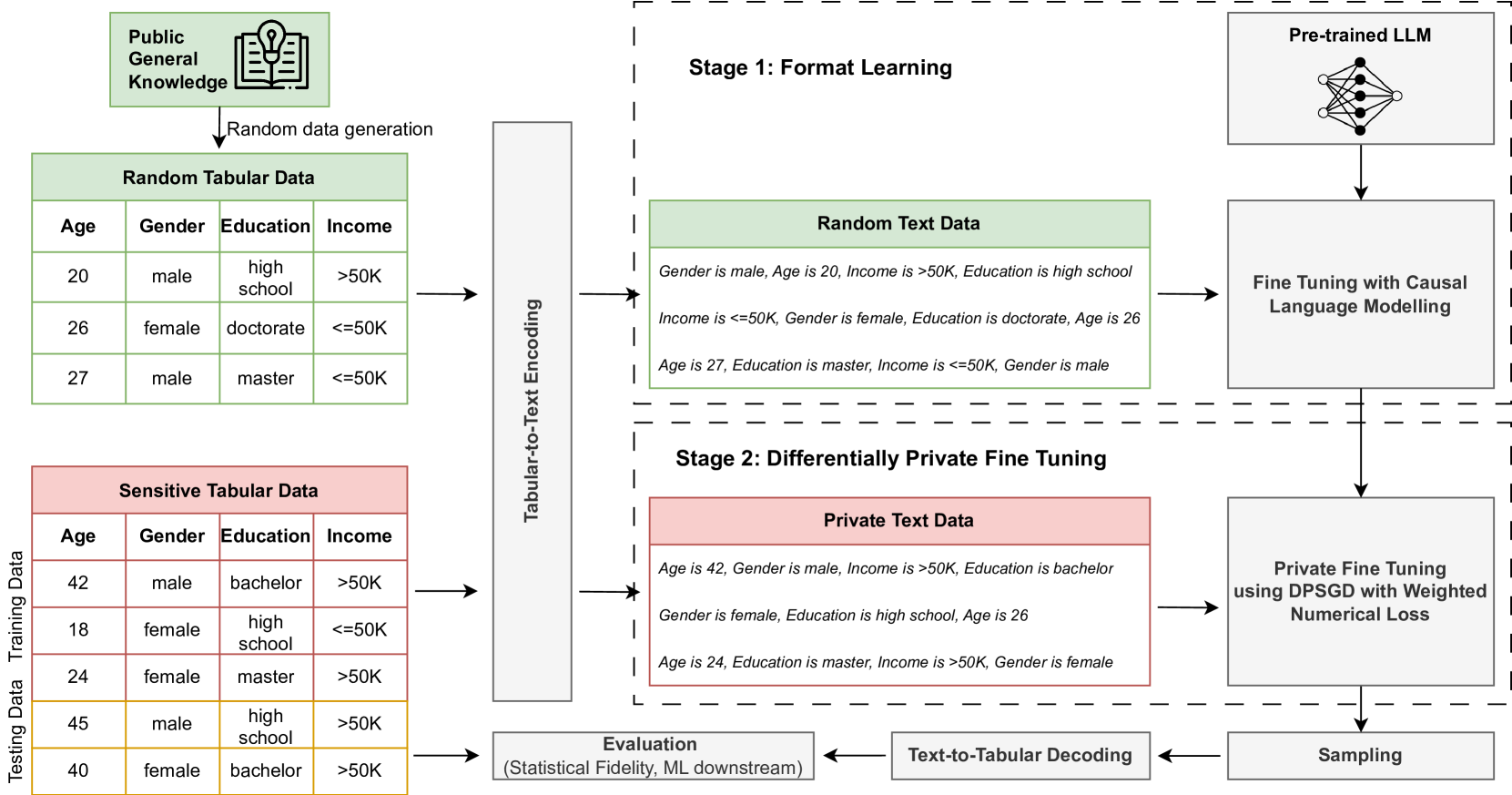
Synthetic tabular data generation with differential privacy is a crucial problem to enable data sharing with formal privacy. Despite a rich history of methodological research and development, developing differentially private tabular data generators that can provide realistic synthetic datasets remains challenging. This paper introduces DP-LLMTGen -- a novel framework for differentially private tabular data synthesis that leverages pretrained large language models (LLMs). DP-LLMTGen models sensitive datasets using a two-stage fine-tuning procedure with a novel loss function specifically designed for tabular data. Subsequently, it generates synthetic data through sampling the fine-tuned LLMs. Our empirical evaluation demonstrates that DP-LLMTGen outperforms a variety of existing mechanisms across multiple datasets and privacy settings. Additionally, we conduct an ablation study and several experimental analyses to deepen our understanding of LLMs in addressing this important problem. Finally, we highlight the controllable generation ability of DP-LLMTGen through a fairness-constrained generation setting.
6/4/2024