Fair Sampling in Diffusion Models through Switching Mechanism

0

Sign in to get full access
Overview
- This paper proposes a fair sampling mechanism for diffusion models to address biases in generated samples.
- The key idea is to introduce a switching mechanism that selectively samples from different parts of the latent space to ensure fairness.
- Experiments show the proposed approach can improve fairness metrics while maintaining sample quality.
Plain English Explanation
The paper looks at the problem of [object Object] in diffusion models, a type of machine learning model that can generate new data samples. Diffusion models can sometimes produce biased samples that don't represent the full diversity of the training data.
To address this, the researchers developed a [object Object] that dynamically selects different parts of the latent space (the hidden representation) to sample from. This helps ensure the generated samples are more [object Object] of the original data, improving [object Object].
Through experiments, the authors show this switching approach can [object Object] while maintaining the overall [object Object]. This could be an important advance for making diffusion models more [object Object] in their outputs.
Technical Explanation
The paper starts by [object Object] relevant to diffusion models, such as demographic parity and equal opportunity. It then introduces the [object Object] - a way to dynamically select different modes (or parts) of the latent space to sample from during the diffusion process.
This switching aims to [object Object] of the generated samples, leading to more [object Object]. The authors evaluate their approach on several [object Object], demonstrating improvements in fairness while preserving sample quality.
Critical Analysis
The paper thoroughly examines the proposed switching mechanism and provides [object Object] to support its effectiveness. However, the authors acknowledge [object Object] in terms of the specific fairness notions considered and the need for further research on the broader societal implications of fair sampling.
Additionally, the [object Object] introduces an extra computational cost, which may be a concern for large-scale or real-time applications. Further work could explore more [object Object] or adaptive switching strategies.
Overall, this paper makes an important contribution to [object Object], but there are still open questions and areas for future research to fully understand the impact and generalizability of this approach.
Conclusion
This paper presents a novel switching mechanism for diffusion models that aims to [object Object] of generated samples by dynamically selecting from diverse parts of the latent space. The results demonstrate the effectiveness of this approach in enhancing [object Object] while maintaining [object Object].
As machine learning models become more widely deployed, ensuring [object Object] in their outputs is crucial. This work represents an important step towards [object Object] diffusion-based data generation, with potential applications in areas like [object Object] and [object Object].
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fair Sampling in Diffusion Models through Switching Mechanism
Yujin Choi, Jinseong Park, Hoki Kim, Jaewook Lee, Saeroom Park
Diffusion models have shown their effectiveness in generation tasks by well-approximating the underlying probability distribution. However, diffusion models are known to suffer from an amplified inherent bias from the training data in terms of fairness. While the sampling process of diffusion models can be controlled by conditional guidance, previous works have attempted to find empirical guidance to achieve quantitative fairness. To address this limitation, we propose a fairness-aware sampling method called textit{attribute switching} mechanism for diffusion models. Without additional training, the proposed sampling can obfuscate sensitive attributes in generated data without relying on classifiers. We mathematically prove and experimentally demonstrate the effectiveness of the proposed method on two key aspects: (i) the generation of fair data and (ii) the preservation of the utility of the generated data.
Read more8/19/2024

0
Fair Data Generation via Score-based Diffusion Model
Yujie Lin, Dong Li, Chen Zhao, Minglai Shao
Fairness-aware domain generalization (FairDG) has emerged as a critical challenge for deploying trustworthy AI systems, particularly in scenarios involving distribution shifts. Traditional methods for addressing fairness have failed in domain generalization due to their lack of consideration for distribution shifts. Although disentanglement has been used to tackle FairDG, it is limited by its strong assumptions. To overcome these limitations, we propose Fairness-aware Classifier-Guided Score-based Diffusion Models (FADE) as a novel approach to effectively address the FairDG issue. Specifically, we first pre-train a score-based diffusion model (SDM) and two classifiers to equip the model with strong generalization capabilities across different domains. Then, we guide the SDM using these pre-trained classifiers to effectively eliminate sensitive information from the generated data. Finally, the generated fair data is used to train downstream classifiers, ensuring robust performance under new data distributions. Extensive experiments on three real-world datasets demonstrate that FADE not only enhances fairness but also improves accuracy in the presence of distribution shifts. Additionally, FADE outperforms existing methods in achieving the best accuracy-fairness trade-offs.
Read more8/29/2024

0
Unlocking Intrinsic Fairness in Stable Diffusion
Eunji Kim, Siwon Kim, Rahim Entezari, Sungroh Yoon
Recent text-to-image models like Stable Diffusion produce photo-realistic images but often show demographic biases. Previous debiasing methods focused on training-based approaches, failing to explore the root causes of bias and overlooking Stable Diffusion's potential for unbiased image generation. In this paper, we demonstrate that Stable Diffusion inherently possesses fairness, which can be unlocked to achieve debiased outputs. Through carefully designed experiments, we identify the excessive bonding between text prompts and the diffusion process as a key source of bias. To address this, we propose a novel approach that perturbs text conditions to unleash Stable Diffusion's intrinsic fairness. Our method effectively mitigates bias without additional tuning, while preserving image-text alignment and image quality.
Read more8/26/2024
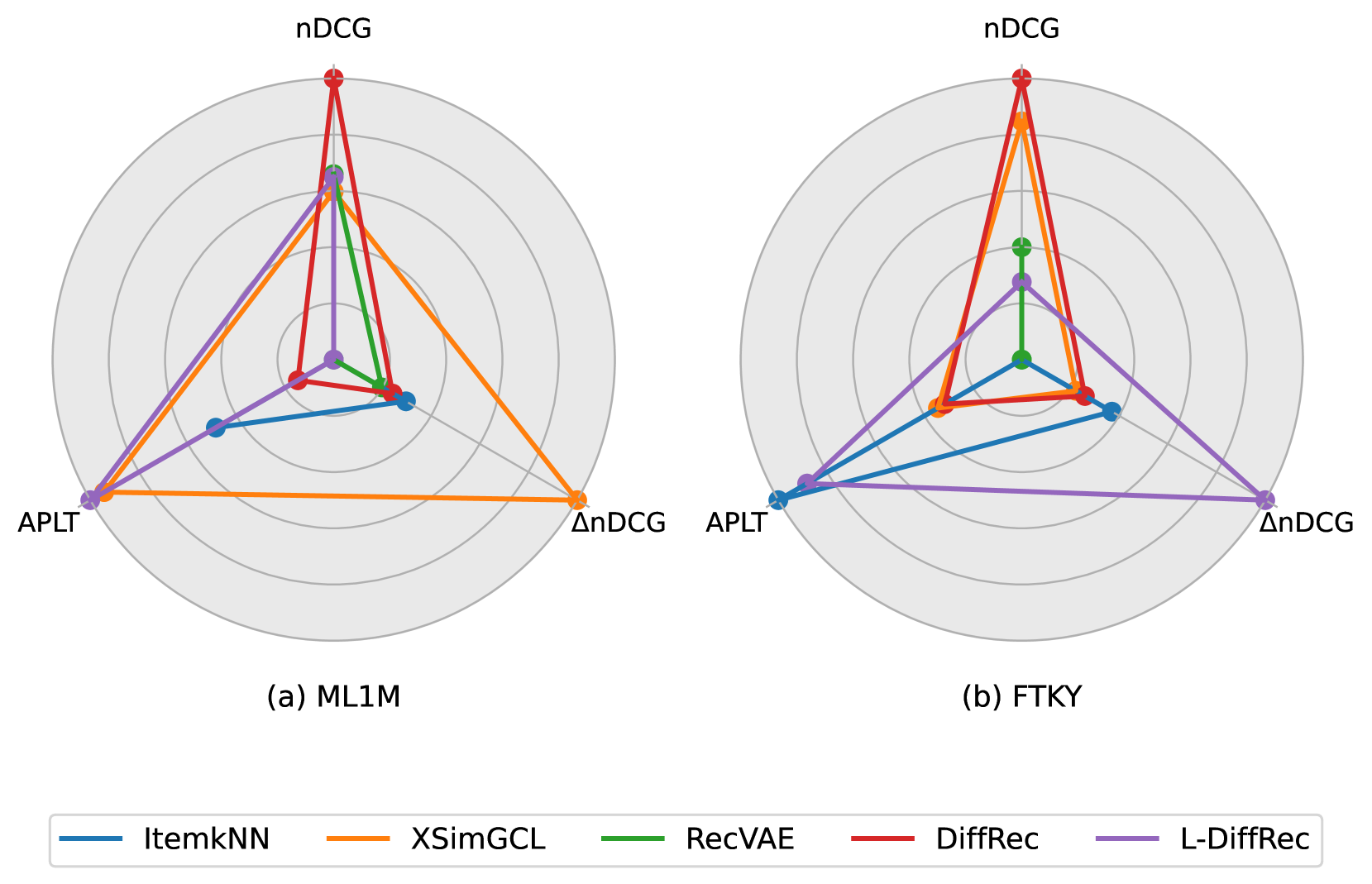
0
How Fair is Your Diffusion Recommender Model?
Daniele Malitesta, Giacomo Medda, Erasmo Purificato, Ludovico Boratto, Fragkiskos D. Malliaros, Mirko Marras, Ernesto William De Luca
Diffusion-based recommender systems have recently proven to outperform traditional generative recommendation approaches, such as variational autoencoders and generative adversarial networks. Nevertheless, the machine learning literature has raised several concerns regarding the possibility that diffusion models, while learning the distribution of data samples, may inadvertently carry information bias and lead to unfair outcomes. In light of this aspect, and considering the relevance that fairness has held in recommendations over the last few decades, we conduct one of the first fairness investigations in the literature on DiffRec, a pioneer approach in diffusion-based recommendation. First, we propose an experimental setting involving DiffRec (and its variant L-DiffRec) along with nine state-of-the-art recommendation models, two popular recommendation datasets from the fairness-aware literature, and six metrics accounting for accuracy and consumer/provider fairness. Then, we perform a twofold analysis, one assessing models' performance under accuracy and recommendation fairness separately, and the other identifying if and to what extent such metrics can strike a performance trade-off. Experimental results from both studies confirm the initial unfairness warnings but pave the way for how to address them in future research directions.
Read more9/9/2024