Fair Data Generation via Score-based Diffusion Model

0

Sign in to get full access
Overview
- This paper proposes a fairness-aware data generation method using a score-based diffusion model.
- The goal is to generate synthetic data that maintains statistical parity between different demographic groups, while preserving the original data distribution.
- The authors introduce a novel "domain shift" technique to encourage the model to generate fair data, and demonstrate its effectiveness on several benchmark datasets.
Plain English Explanation
The paper discusses a way to generate new data that is fair and balanced, while still capturing the key characteristics of the original dataset. The researchers use a type of machine learning model called a "score-based diffusion model" to create this synthetic data.
The key innovation is a technique they call "domain shift," which helps ensure the generated data is statistically similar across different demographic groups, like gender or race. This is important because many machine learning models can pick up on and amplify biases present in real-world data. By generating fair synthetic data, the researchers aim to create a level playing field for training more equitable AI systems.
This builds on prior work on using diffusion models for data generation and fairness-aware learning.
Overall, the goal is to develop methods that can produce diverse, representative data while mitigating problematic biases - a crucial step towards building fairer and more inclusive AI technologies. This relates to other recent research on using diffusion for deepfake detection, dataset generation for downstream tasks, tabular data synthesis, and distribution-aware data expansion.
Technical Explanation
The authors propose a fairness-aware data generation method based on a score-based diffusion model. Diffusion models are a type of generative AI that learn to gradually transform noise into realistic-looking samples by modeling the "reverse" diffusion process.
To encourage fairness, the researchers introduce a "domain shift" technique that applies a fairness penalty during training. This incentivizes the model to generate samples that maintain statistical parity between different demographic groups, while still matching the overall data distribution.
Experiments on several benchmark datasets show this approach can produce fair synthetic data that closely matches the original data characteristics. The authors analyze the trade-offs between fairness, sample quality, and diversity, and discuss potential limitations and future research directions.
Critical Analysis
The paper presents a novel and promising approach for generating fair synthetic data using diffusion models. The domain shift technique is a clever way to incorporate fairness considerations directly into the generative process.
That said, the authors acknowledge several caveats and limitations. For example, the fairness metric used may not fully capture all nuances of bias, and the approach relies on having access to demographic labels in the training data. There are also open questions around scalability to high-dimensional or tabular data.
Additionally, while the experiments demonstrate the viability of the approach, more work is needed to fully characterize its real-world performance and robustness. Potential edge cases or unintended consequences should be carefully explored.
Overall, this research represents an important step towards developing fairness-aware generative models. However, continued scrutiny and further advancements will be crucial as these techniques are applied to sensitive domains. Readers are encouraged to think critically about the societal implications and potential pitfalls of such data generation methods.
Conclusion
This paper introduces a novel fairness-aware data generation approach based on score-based diffusion models. By incorporating a "domain shift" technique, the model is able to produce synthetic data that maintains statistical parity between demographic groups, while still preserving the overall characteristics of the original dataset.
The results demonstrate the potential of this method to support the development of fairer AI systems, by providing diverse and representative training data that mitigates problematic biases. As the use of generative models becomes more widespread, techniques like this will be increasingly important for ensuring the responsible and equitable deployment of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fair Data Generation via Score-based Diffusion Model
Yujie Lin, Dong Li, Chen Zhao, Minglai Shao
Fairness-aware domain generalization (FairDG) has emerged as a critical challenge for deploying trustworthy AI systems, particularly in scenarios involving distribution shifts. Traditional methods for addressing fairness have failed in domain generalization due to their lack of consideration for distribution shifts. Although disentanglement has been used to tackle FairDG, it is limited by its strong assumptions. To overcome these limitations, we propose Fairness-aware Classifier-Guided Score-based Diffusion Models (FADE) as a novel approach to effectively address the FairDG issue. Specifically, we first pre-train a score-based diffusion model (SDM) and two classifiers to equip the model with strong generalization capabilities across different domains. Then, we guide the SDM using these pre-trained classifiers to effectively eliminate sensitive information from the generated data. Finally, the generated fair data is used to train downstream classifiers, ensuring robust performance under new data distributions. Extensive experiments on three real-world datasets demonstrate that FADE not only enhances fairness but also improves accuracy in the presence of distribution shifts. Additionally, FADE outperforms existing methods in achieving the best accuracy-fairness trade-offs.
Read more8/29/2024

0
Generating Synthetic Fair Syntax-agnostic Data by Learning and Distilling Fair Representation
Md Fahim Sikder, Resmi Ramachandranpillai, Daniel de Leng, Fredrik Heintz
Data Fairness is a crucial topic due to the recent wide usage of AI powered applications. Most of the real-world data is filled with human or machine biases and when those data are being used to train AI models, there is a chance that the model will reflect the bias in the training data. Existing bias-mitigating generative methods based on GANs, Diffusion models need in-processing fairness objectives and fail to consider computational overhead while choosing computationally-heavy architectures, which may lead to high computational demands, instability and poor optimization performance. To mitigate this issue, in this work, we present a fair data generation technique based on knowledge distillation, where we use a small architecture to distill the fair representation in the latent space. The idea of fair latent space distillation enables more flexible and stable training of Fair Generative Models (FGMs). We first learn a syntax-agnostic (for any data type) fair representation of the data, followed by distillation in the latent space into a smaller model. After distillation, we use the distilled fair latent space to generate high-fidelity fair synthetic data. While distilling, we employ quality loss (for fair distillation) and utility loss (for data utility) to ensure that the fairness and data utility characteristics remain in the distilled latent space. Our approaches show a 5%, 5% and 10% rise in performance in fairness, synthetic sample quality and data utility, respectively, than the state-of-the-art fair generative model.
Read more8/21/2024
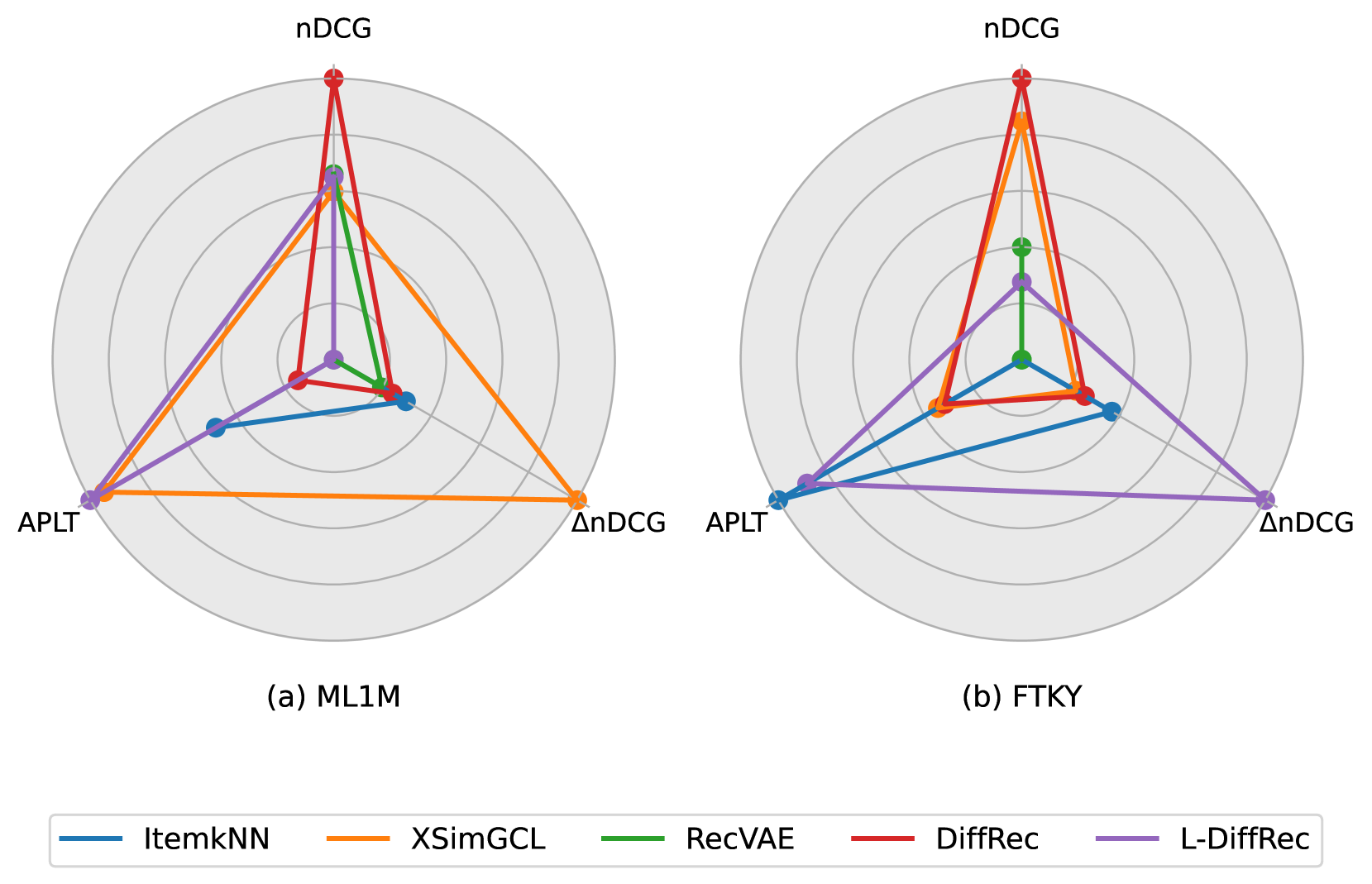
0
How Fair is Your Diffusion Recommender Model?
Daniele Malitesta, Giacomo Medda, Erasmo Purificato, Ludovico Boratto, Fragkiskos D. Malliaros, Mirko Marras, Ernesto William De Luca
Diffusion-based recommender systems have recently proven to outperform traditional generative recommendation approaches, such as variational autoencoders and generative adversarial networks. Nevertheless, the machine learning literature has raised several concerns regarding the possibility that diffusion models, while learning the distribution of data samples, may inadvertently carry information bias and lead to unfair outcomes. In light of this aspect, and considering the relevance that fairness has held in recommendations over the last few decades, we conduct one of the first fairness investigations in the literature on DiffRec, a pioneer approach in diffusion-based recommendation. First, we propose an experimental setting involving DiffRec (and its variant L-DiffRec) along with nine state-of-the-art recommendation models, two popular recommendation datasets from the fairness-aware literature, and six metrics accounting for accuracy and consumer/provider fairness. Then, we perform a twofold analysis, one assessing models' performance under accuracy and recommendation fairness separately, and the other identifying if and to what extent such metrics can strike a performance trade-off. Experimental results from both studies confirm the initial unfairness warnings but pave the way for how to address them in future research directions.
Read more9/9/2024

0
Fair Sampling in Diffusion Models through Switching Mechanism
Yujin Choi, Jinseong Park, Hoki Kim, Jaewook Lee, Saeroom Park
Diffusion models have shown their effectiveness in generation tasks by well-approximating the underlying probability distribution. However, diffusion models are known to suffer from an amplified inherent bias from the training data in terms of fairness. While the sampling process of diffusion models can be controlled by conditional guidance, previous works have attempted to find empirical guidance to achieve quantitative fairness. To address this limitation, we propose a fairness-aware sampling method called textit{attribute switching} mechanism for diffusion models. Without additional training, the proposed sampling can obfuscate sensitive attributes in generated data without relying on classifiers. We mathematically prove and experimentally demonstrate the effectiveness of the proposed method on two key aspects: (i) the generation of fair data and (ii) the preservation of the utility of the generated data.
Read more8/19/2024