The Fairness-Quality Trade-off in Clustering

0

Sign in to get full access
Overview
- The paper discusses the trade-off between fairness and quality in clustering algorithms.
- It explores how to balance the goals of achieving fair cluster assignments and maximizing the overall quality of the clustering.
- The researchers propose a novel framework to quantify this trade-off and analyze it theoretically and empirically.
Plain English Explanation
Clustering is a common machine learning technique used to group similar data points together. However, when performing clustering, there is often a trade-off between fairness and the overall quality of the clustering utility.
Fairness in clustering means ensuring that the clusters are representative of the underlying population and do not disproportionately favor or exclude certain groups. Quality, on the other hand, refers to how well the clustering captures the natural structure and relationships within the data.
The researchers in this paper propose a framework to understand and quantify this fairness-quality trade-off. They analyze this trade-off both theoretically and through experiments, providing insights into how to balance these competing objectives when designing clustering algorithms.
Technical Explanation
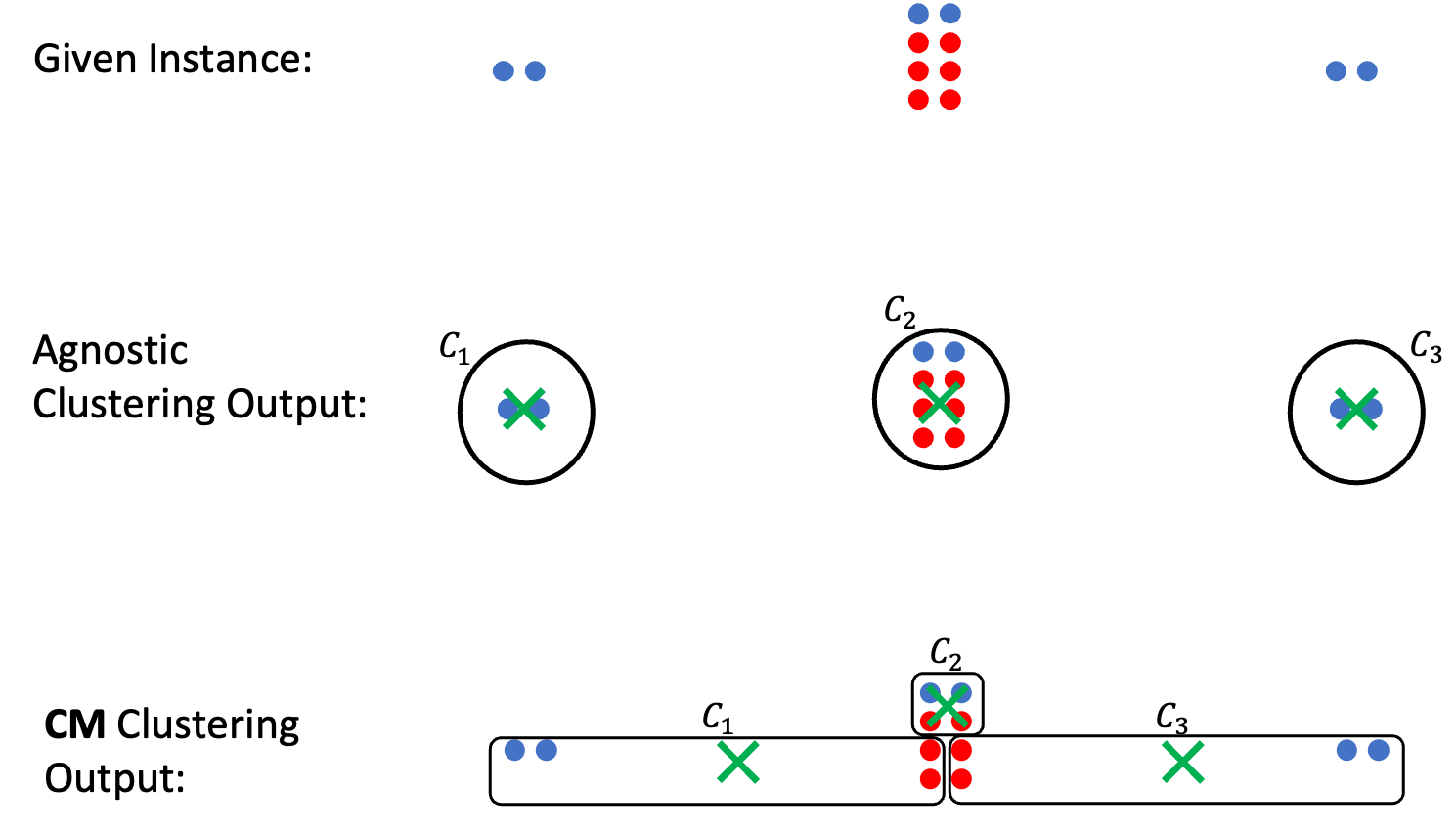
The paper introduces a novel framework for analyzing the fairness-quality trade-off in clustering. The researchers define a fairness measure that captures the proportional representation of different groups within the clusters, and a quality measure that reflects the overall utility of the clustering.
They then formulate an optimization problem to find the clustering that maximizes the quality while satisfying fairness constraints. This allows them to characterize the Pareto-optimal trade-off between fairness and quality, and analyze how different algorithmic choices impact this trade-off.
Through theoretical analysis and empirical evaluation on real-world datasets, the researchers demonstrate that there are inherent limitations in achieving both high fairness and high quality simultaneously. They provide insights into how to navigate this trade-off and design clustering algorithms that strike the right balance between these competing objectives.
Critical Analysis
The paper provides a rigorous and comprehensive framework for understanding the fairness-quality trade-off in clustering. The researchers have carefully defined the relevant measures and formulated an optimization problem to analyze this trade-off.
One potential limitation of the work is that the fairness measure used, based on proportional representation, may not capture all aspects of fairness. Other notions of fairness, such as equalized odds, could be worth exploring in future research.
Additionally, the paper focuses on a specific clustering objective function and may not directly generalize to other clustering paradigms or applications. Further research is needed to understand how the fairness-quality trade-off manifests in different clustering settings and under alternative modeling assumptions.
Conclusion
This paper makes an important contribution to the growing body of research on fair machine learning. By providing a principled framework for analyzing the inherent trade-off between fairness and quality in clustering, the researchers have laid the groundwork for the development of more ethical and responsible clustering algorithms.
The insights from this work can inform the design of clustering systems that better serve the needs of diverse populations, while still maintaining high-quality and meaningful groupings of the data. As machine learning continues to be applied in increasingly consequential domains, understanding and navigating these types of trade-offs will be crucial for ensuring the fairness and trustworthiness of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Fairness-Quality Trade-off in Clustering
Rashida Hakim, Ana-Andreea Stoica, Christos H. Papadimitriou, Mihalis Yannakakis
Fairness in clustering has been considered extensively in the past; however, the trade-off between the two objectives -- e.g., can we sacrifice just a little in the quality of the clustering to significantly increase fairness, or vice-versa? -- has rarely been addressed. We introduce novel algorithms for tracing the complete trade-off curve, or Pareto front, between quality and fairness in clustering problems; that is, computing all clusterings that are not dominated in both objectives by other clusterings. Unlike previous work that deals with specific objectives for quality and fairness, we deal with all objectives for fairness and quality in two general classes encompassing most of the special cases addressed in previous work. Our algorithm must take exponential time in the worst case as the Pareto front itself can be exponential. Even when the Pareto front is polynomial, our algorithm may take exponential time, and we prove that this is inevitable unless P = NP. However, we also present a new polynomial-time algorithm for computing the entire Pareto front when the cluster centers are fixed, and for perhaps the most natural fairness objective: minimizing the sum, over all clusters, of the imbalance between the two groups in each cluster.
Read more8/20/2024
0
Fair Clustering: Critique, Caveats, and Future Directions
John Dickerson, Seyed A. Esmaeili, Jamie Morgenstern, Claire Jie Zhang
Clustering is a fundamental problem in machine learning and operations research. Therefore, given the fact that fairness considerations have become of paramount importance in algorithm design, fairness in clustering has received significant attention from the research community. The literature on fair clustering has resulted in a collection of interesting fairness notions and elaborate algorithms. In this paper, we take a critical view of fair clustering, identifying a collection of ignored issues such as the lack of a clear utility characterization and the difficulty in accounting for the downstream effects of a fair clustering algorithm in machine learning settings. In some cases, we demonstrate examples where the application of a fair clustering algorithm can have significant negative impacts on social welfare. We end by identifying a collection of steps that would lead towards more impactful research in fair clustering.
Read more6/26/2024
🗣️
0
Utility-Fairness Trade-Offs and How to Find Them
Sepehr Dehdashtian, Bashir Sadeghi, Vishnu Naresh Boddeti
When building classification systems with demographic fairness considerations, there are two objectives to satisfy: 1) maximizing utility for the specific task and 2) ensuring fairness w.r.t. a known demographic attribute. These objectives often compete, so optimizing both can lead to a trade-off between utility and fairness. While existing works acknowledge the trade-offs and study their limits, two questions remain unanswered: 1) What are the optimal trade-offs between utility and fairness? and 2) How can we numerically quantify these trade-offs from data for a desired prediction task and demographic attribute of interest? This paper addresses these questions. We introduce two utility-fairness trade-offs: the Data-Space and Label-Space Trade-off. The trade-offs reveal three regions within the utility-fairness plane, delineating what is fully and partially possible and impossible. We propose U-FaTE, a method to numerically quantify the trade-offs for a given prediction task and group fairness definition from data samples. Based on the trade-offs, we introduce a new scheme for evaluating representations. An extensive evaluation of fair representation learning methods and representations from over 1000 pre-trained models revealed that most current approaches are far from the estimated and achievable fairness-utility trade-offs across multiple datasets and prediction tasks.
Read more4/16/2024
🌀
0
Proportional Fairness in Clustering: A Social Choice Perspective
Leon Kellerhals, Jannik Peters
We study the proportional clustering problem of Chen et al. [ICML'19] and relate it to the area of multiwinner voting in computational social choice. We show that any clustering satisfying a weak proportionality notion of Brill and Peters [EC'23] simultaneously obtains the best known approximations to the proportional fairness notion of Chen et al. [ICML'19], but also to individual fairness [Jung et al., FORC'20] and the core [Li et al. ICML'21]. In fact, we show that any approximation to proportional fairness is also an approximation to individual fairness and vice versa. Finally, we also study stronger notions of proportional representation, in which deviations do not only happen to single, but multiple candidate centers, and show that stronger proportionality notions of Brill and Peters [EC'23] imply approximations to these stronger guarantees.
Read more5/27/2024