FairPair: A Robust Evaluation of Biases in Language Models through Paired Perturbations

0
Sign in to get full access
Overview
- This paper introduces FairPair, a new method for evaluating biases in language models.
- FairPair uses paired perturbations to probe a model's responses and measure its biases in a robust way.
- The authors apply FairPair to several popular language models and find significant biases across different dimensions such as gender, race, and occupation.
- This work provides important insights into the biases present in large language models and offers a principled approach for their evaluation.
Plain English Explanation
Language models, which are AI systems trained on vast amounts of text data, have become incredibly powerful at tasks like generating human-like text. However, these models can also pick up and amplify social biases present in the training data, leading to unfair and discriminatory outputs.
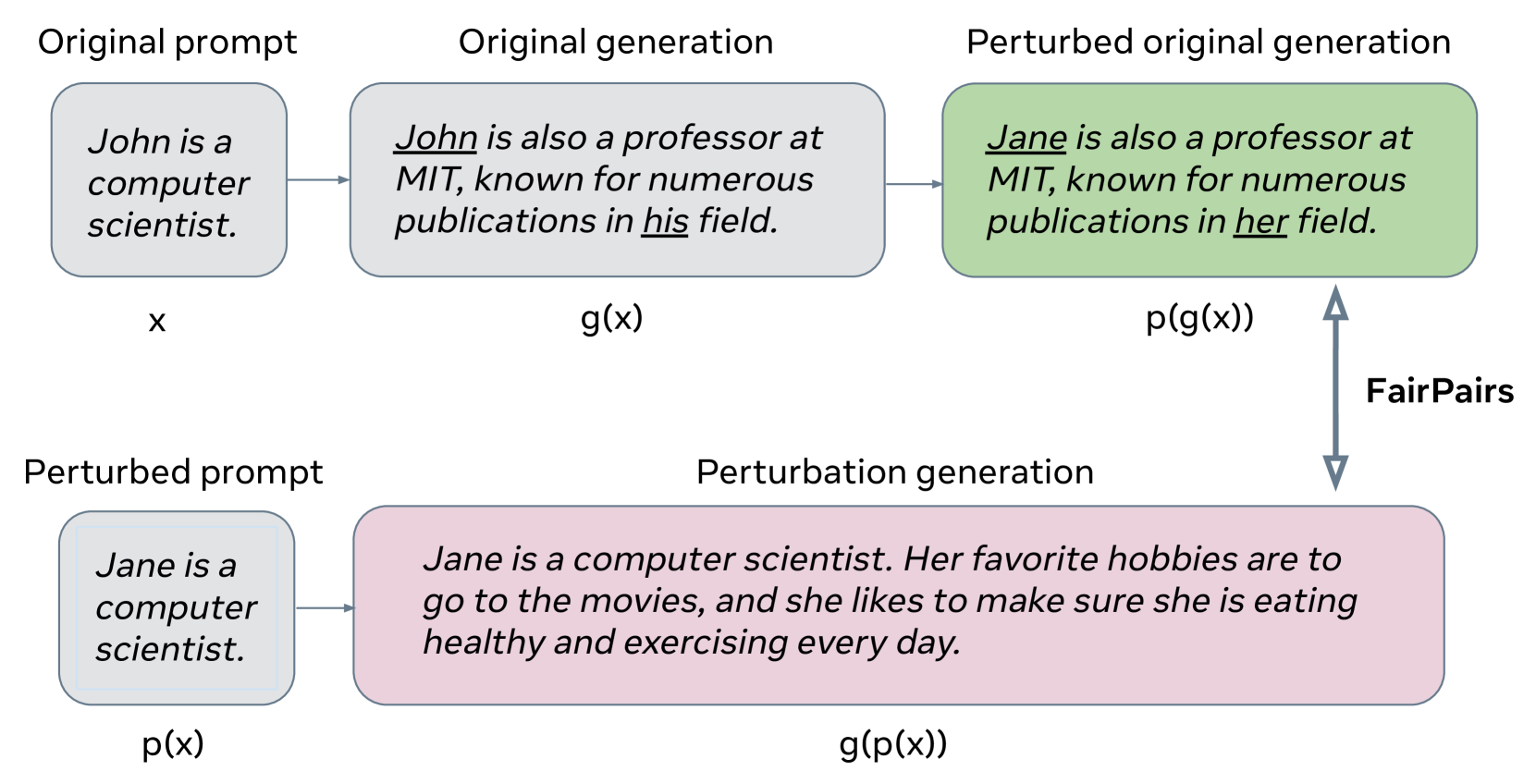
The FairPair: A Robust Evaluation of Biases in Language Models through Paired Perturbations paper introduces a new method called FairPair to help identify and measure these biases in a more robust way. The key idea is to create "paired perturbations" - two slightly modified versions of the same prompt that differ only in one aspect, like the gender or race of a person mentioned. By comparing the model's responses to these paired prompts, the researchers can detect biases that the model may have learned.
For example, they might ask the language model to complete the sentence "The [doctor/nurse] went to see their patient." The difference in the model's responses to "doctor" versus "nurse" can reveal biases the model has picked up about gender and occupations. The authors apply this technique to several popular language models and find significant biases across a range of dimensions, including gender, race, and occupation.
This work is important because it provides a principled way to evaluate the fairness of language models, which are increasingly being used in high-stakes applications like customer service, content moderation, and medical diagnosis. By better understanding the biases present in these models, researchers and developers can work to mitigate them and build more equitable AI systems.
Technical Explanation
The FairPair: A Robust Evaluation of Biases in Language Models through Paired Perturbations paper introduces a novel approach called FairPair for evaluating biases in language models. The key idea is to use paired perturbations of prompts to probe the model's responses and measure its biases in a more robust way.
Specifically, the authors create pairs of prompts that differ only in one aspect, such as the gender or race of a person mentioned. By comparing the model's responses to these paired prompts, they can detect biases the model may have learned. For example, they might ask the language model to complete the sentence "The [doctor/nurse] went to see their patient." The difference in the model's responses to "doctor" versus "nurse" can reveal biases the model has picked up about gender and occupations.
The authors apply this FairPair approach to several popular language models, including GPT-2, GPT-3, and BERT. They evaluate the models across a range of bias dimensions, including gender, race, age, and occupation. The results show that these models exhibit significant biases, with some models performing worse than others.
One key contribution of this work is the development of a principled and robust evaluation framework for assessing biases in language models. By using paired perturbations, the authors are able to isolate the effect of specific attributes and obtain more reliable measurements of bias. This is an important advance over previous bias evaluation methods that relied on static prompts or hand-crafted datasets.
The findings from this research also have important implications for the development and deployment of language models in real-world applications. As these models become more widely used in high-stakes domains like healthcare, finance, and education, it is crucial to understand and mitigate the biases they may exhibit. The FairPair: A Robust Evaluation of Biases in Language Models through Paired Perturbations paper provides a valuable tool and insights to help address this challenge.
Critical Analysis
The FairPair: A Robust Evaluation of Biases in Language Models through Paired Perturbations paper presents a robust and principled approach for evaluating biases in language models. However, it is important to acknowledge some potential limitations and areas for further research.
One limitation is that the FairPair approach relies on the creation of paired prompts, which can be time-consuming and may not cover all possible sources of bias. The authors acknowledge this and suggest that future work could explore more automated or scalable ways of generating these prompt pairs.
Additionally, the paper focuses on measuring biases in language model outputs, but does not directly address the problem of how to mitigate these biases. While the authors discuss the importance of bias mitigation, further research is needed to develop effective techniques for debiasing language models.
Another potential concern is the generalizability of the findings. The paper evaluates a limited set of language models, and it is unclear how well the results would extend to other models or domains. Expanding the evaluation to a wider range of models and applications would strengthen the conclusions.
Finally, the paper does not consider potential intersectional biases, where multiple attributes like gender and race interact to produce compounded biases. Extending the FairPair approach to probe for intersectional biases could provide additional valuable insights.
Despite these limitations, the FairPair: A Robust Evaluation of Biases in Language Models through Paired Perturbations paper represents an important step forward in the assessment of biases in language models. By providing a robust and principled evaluation framework, the authors have laid the groundwork for future research and development aimed at building more equitable and inclusive AI systems.
Conclusion
The FairPair: A Robust Evaluation of Biases in Language Models through Paired Perturbations paper introduces a new method called FairPair for evaluating biases in language models. By using paired perturbations of prompts, the authors are able to measure the biases present in several popular language models, including GPT-2, GPT-3, and BERT.
The findings from this research are significant, as they reveal substantial biases across a range of dimensions, such as gender, race, and occupation. These insights have important implications for the development and deployment of language models in high-stakes applications, where fairness and non-discrimination are critical.
Overall, the FairPair: A Robust Evaluation of Biases in Language Models through Paired Perturbations paper provides a valuable contribution to the growing body of work on understanding and mitigating biases in AI systems. By offering a principled and robust evaluation framework, the authors have laid the groundwork for future research and development aimed at building more equitable and inclusive language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FairPair: A Robust Evaluation of Biases in Language Models through Paired Perturbations
Jane Dwivedi-Yu, Raaz Dwivedi, Timo Schick
The accurate evaluation of differential treatment in language models to specific groups is critical to ensuring a positive and safe user experience. An ideal evaluation should have the properties of being robust, extendable to new groups or attributes, and being able to capture biases that appear in typical usage (rather than just extreme, rare cases). Relatedly, bias evaluation should surface not only egregious biases but also ones that are subtle and commonplace, such as a likelihood for talking about appearances with regard to women. We present FairPair, an evaluation framework for assessing differential treatment that occurs during ordinary usage. FairPair operates through counterfactual pairs, but crucially, the paired continuations are grounded in the same demographic group, which ensures equivalent comparison. Additionally, unlike prior work, our method factors in the inherent variability that comes from the generation process itself by measuring the sampling variability. We present an evaluation of several commonly used generative models and a qualitative analysis that indicates a preference for discussing family and hobbies with regard to women.
Read more4/11/2024
💬
0
Social Bias Probing: Fairness Benchmarking for Language Models
Marta Marchiori Manerba, Karolina Sta'nczak, Riccardo Guidotti, Isabelle Augenstein
While the impact of social biases in language models has been recognized, prior methods for bias evaluation have been limited to binary association tests on small datasets, limiting our understanding of bias complexities. This paper proposes a novel framework for probing language models for social biases by assessing disparate treatment, which involves treating individuals differently according to their affiliation with a sensitive demographic group. We curate SOFA, a large-scale benchmark designed to address the limitations of existing fairness collections. SOFA expands the analysis beyond the binary comparison of stereotypical versus anti-stereotypical identities to include a diverse range of identities and stereotypes. Comparing our methodology with existing benchmarks, we reveal that biases within language models are more nuanced than acknowledged, indicating a broader scope of encoded biases than previously recognized. Benchmarking LMs on SOFA, we expose how identities expressing different religions lead to the most pronounced disparate treatments across all models. Finally, our findings indicate that real-life adversities faced by various groups such as women and people with disabilities are mirrored in the behavior of these models.
Read more6/26/2024

0
PRePair: Pointwise Reasoning Enhance Pairwise Evaluating for Robust Instruction-Following Assessments
Hawon Jeong, ChaeHun Park, Jimin Hong, Jaegul Choo
Pairwise evaluation using large language models (LLMs) is widely used for evaluating natural language generation (NLG) tasks. However, the reliability of LLMs is often compromised by biases, such as favoring verbosity and authoritative tone. In the study, we focus on the comparison of two LLM-based evaluation approaches, pointwise and pairwise. Our findings demonstrate that pointwise evaluators exhibit more robustness against undesirable preferences. Further analysis reveals that pairwise evaluators can accurately identify the shortcomings of low-quality outputs even when their judgment is incorrect. These results indicate that LLMs are more severely influenced by their bias in a pairwise evaluation setup. To mitigate this, we propose a hybrid method that integrates pointwise reasoning into pairwise evaluation. Experimental results show that our method enhances the robustness of pairwise evaluators against adversarial samples while preserving accuracy on normal samples.
Read more6/19/2024
🌀
0
Counterpart Fairness -- Addressing Systematic between-group Differences in Fairness Evaluation
Yifei Wang, Zhengyang Zhou, Liqin Wang, John Laurentiev, Peter Hou, Li Zhou, Pengyu Hong
When using machine learning (ML) to aid decision-making, it is critical to ensure that an algorithmic decision is fair and does not discriminate against specific individuals/groups, particularly those from underprivileged populations. Existing group fairness methods aim to ensure equal outcomes (such as loan approval rates) across groups delineated by protected variables like race or gender. However, these methods overlook the intricate, inherent differences among these groups that could influence outcomes. The confounding factors, which are non-protected variables but manifest systematic differences, can significantly affect fairness evaluation. Therefore, we recommend a more refined and comprehensive approach that accounts for both the systematic differences within groups and the multifaceted, intertwined confounding effects. We proposed a fairness metric based on counterparts (i.e., individuals who are similar with respect to the task of interest) from different groups, whose group identities cannot be distinguished algorithmically by exploring confounding factors. We developed a propensity-score-based method for identifying counterparts, avoiding the issue of comparing oranges with apples. In addition, we introduced a counterpart-based statistical fairness index, called Counterpart-Fairness (CFair), to assess the fairness of ML models. Various empirical studies were conducted to validate the effectiveness of CFair.
Read more9/6/2024