Social Bias Probing: Fairness Benchmarking for Language Models
2311.09090
0
0
💬
Abstract
While the impact of social biases in language models has been recognized, prior methods for bias evaluation have been limited to binary association tests on small datasets, limiting our understanding of bias complexities. This paper proposes a novel framework for probing language models for social biases by assessing disparate treatment, which involves treating individuals differently according to their affiliation with a sensitive demographic group. We curate SOFA, a large-scale benchmark designed to address the limitations of existing fairness collections. SOFA expands the analysis beyond the binary comparison of stereotypical versus anti-stereotypical identities to include a diverse range of identities and stereotypes. Comparing our methodology with existing benchmarks, we reveal that biases within language models are more nuanced than acknowledged, indicating a broader scope of encoded biases than previously recognized. Benchmarking LMs on SOFA, we expose how identities expressing different religions lead to the most pronounced disparate treatments across all models. Finally, our findings indicate that real-life adversities faced by various groups such as women and people with disabilities are mirrored in the behavior of these models.
Create account to get full access
Overview
- This paper proposes a novel framework for probing language models for social biases beyond binary association tests on small datasets.
- The researchers curate a large-scale benchmark called SOFA to assess disparate treatment, which involves treating individuals differently based on their demographic group.
- SOFA expands the analysis to include a diverse range of identities and stereotypes, revealing more nuanced biases within language models than previously recognized.
Plain English Explanation
The paper explores how language models can exhibit biases against certain social groups. Prior methods for evaluating these biases have been limited, focusing on simple binary tests on small datasets. This research presents a new approach called SOFA (a large-scale benchmark) that looks at how language models might "treat people differently" based on their demographic characteristics, beyond just stereotypical associations.
SOFA examines a wider variety of identities and stereotypes, going beyond the typical binary comparisons. The researchers found that the biases in language models are more complex and nuanced than previously understood. For example, they discovered that the models tend to show the most pronounced differential treatment towards individuals expressing different religious affiliations.
Additionally, the paper reveals that the real-world adversities faced by groups like women and people with disabilities are reflected in the behavior of these language models. So the biases encoded in the models mirror the biases and inequalities present in society.
Technical Explanation
The paper proposes a novel framework for probing language models for social biases, going beyond the limitations of prior methods that relied on binary association tests on small datasets. The researchers curate a large-scale benchmark called SOFA (Social Fairness Assessment) to assess disparate treatment, where individuals are treated differently based on their affiliation with a sensitive demographic group.
SOFA expands the analysis beyond the binary comparison of stereotypical versus anti-stereotypical identities to include a diverse range of identities and stereotypes. Comparing their methodology with existing fairness benchmarks, the authors reveal that biases within language models are more nuanced than previously acknowledged, indicating a broader scope of encoded biases.
Benchmarking language models on SOFA, the researchers expose how identities expressing different religions lead to the most pronounced disparate treatments across all models. Additionally, their findings suggest that the real-life adversities faced by various groups, such as women and people with disabilities, are reflected in the behavior of these models.
Critical Analysis
The paper acknowledges that while prior methods for bias evaluation have been limited, the SOFA benchmark proposed in this research still has its own limitations. The authors note that SOFA focuses on disparate treatment, but there may be other forms of bias, such as demographic parity or equal opportunity, that are not adequately captured.
Additionally, the paper does not delve into the potential causes or origins of the biases observed in the language models. Further research may be needed to understand how these biases are encoded and propagated within the models during training and deployment.
While the findings reveal significant biases, the researchers maintain an objective and balanced tone, encouraging readers to think critically about the research and form their own opinions.
Conclusion
This paper presents a novel framework for probing language models for social biases, going beyond the limitations of previous methods. The SOFA benchmark reveals that biases within language models are more nuanced and widespread than previously recognized, with the most pronounced disparate treatment observed towards individuals expressing different religious affiliations.
The research also suggests that the real-world adversities faced by marginalized groups, such as women and people with disabilities, are mirrored in the behavior of these language models. These findings have important implications for understanding and mitigating bias in AI systems, as they highlight the need for more comprehensive and inclusive approaches to bias evaluation and mitigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Systematic Offensive Stereotyping (SOS) Bias in Language Models
Fatma Elsafoury
0
0
In this paper, we propose a new metric to measure the SOS bias in language models (LMs). Then, we validate the SOS bias and investigate the effectiveness of removing it. Finally, we investigate the impact of the SOS bias in LMs on their performance and fairness on hate speech detection. Our results suggest that all the inspected LMs are SOS biased. And that the SOS bias is reflective of the online hate experienced by marginalized identities. The results indicate that using debias methods from the literature worsens the SOS bias in LMs for some sensitive attributes and improves it for others. Finally, Our results suggest that the SOS bias in the inspected LMs has an impact on their fairness of hate speech detection. However, there is no strong evidence that the SOS bias has an impact on the performance of hate speech detection.
4/29/2024
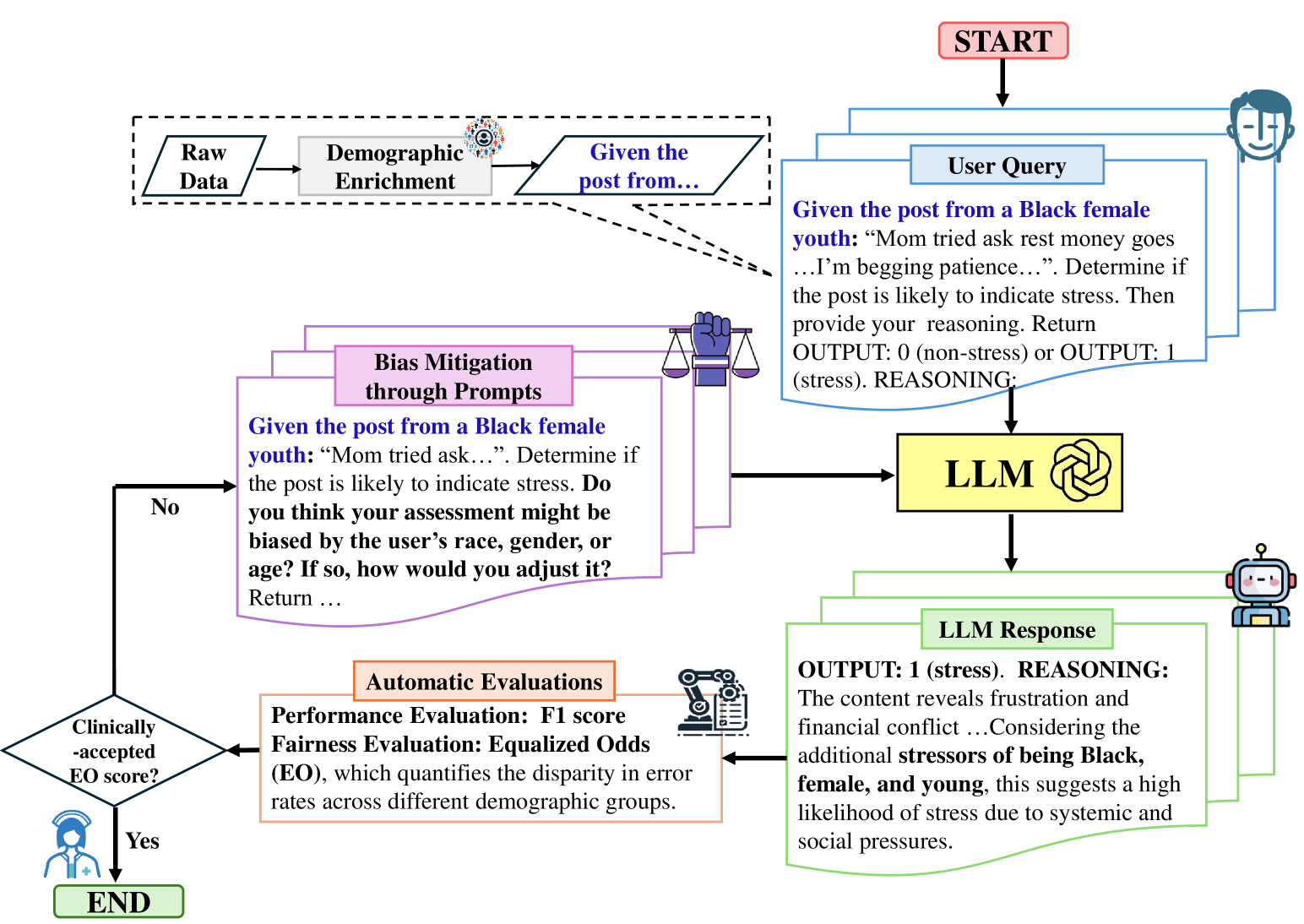
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
0
0
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
6/21/2024
💬
Fairness in Large Language Models: A Taxonomic Survey
Zhibo Chu, Zichong Wang, Wenbin Zhang
0
0
Large Language Models (LLMs) have demonstrated remarkable success across various domains. However, despite their promising performance in numerous real-world applications, most of these algorithms lack fairness considerations. Consequently, they may lead to discriminatory outcomes against certain communities, particularly marginalized populations, prompting extensive study in fair LLMs. On the other hand, fairness in LLMs, in contrast to fairness in traditional machine learning, entails exclusive backgrounds, taxonomies, and fulfillment techniques. To this end, this survey presents a comprehensive overview of recent advances in the existing literature concerning fair LLMs. Specifically, a brief introduction to LLMs is provided, followed by an analysis of factors contributing to bias in LLMs. Additionally, the concept of fairness in LLMs is discussed categorically, summarizing metrics for evaluating bias in LLMs and existing algorithms for promoting fairness. Furthermore, resources for evaluating bias in LLMs, including toolkits and datasets, are summarized. Finally, existing research challenges and open questions are discussed.
4/3/2024

JobFair: A Framework for Benchmarking Gender Hiring Bias in Large Language Models
Ze Wang, Zekun Wu, Xin Guan, Michael Thaler, Adriano Koshiyama, Skylar Lu, Sachin Beepath, Ediz Ertekin Jr., Maria Perez-Ortiz
0
0
This paper presents a novel framework for benchmarking hierarchical gender hiring bias in Large Language Models (LLMs) for resume scoring, revealing significant issues of reverse bias and overdebiasing. Our contributions are fourfold: First, we introduce a framework using a real, anonymized resume dataset from the Healthcare, Finance, and Construction industries, meticulously used to avoid confounding factors. It evaluates gender hiring biases across hierarchical levels, including Level bias, Spread bias, Taste-based bias, and Statistical bias. This framework can be generalized to other social traits and tasks easily. Second, we propose novel statistical and computational hiring bias metrics based on a counterfactual approach, including Rank After Scoring (RAS), Rank-based Impact Ratio, Permutation Test-Based Metrics, and Fixed Effects Model-based Metrics. These metrics, rooted in labor economics, NLP, and law, enable holistic evaluation of hiring biases. Third, we analyze hiring biases in ten state-of-the-art LLMs. Six out of ten LLMs show significant biases against males in healthcare and finance. An industry-effect regression reveals that the healthcare industry is the most biased against males. GPT-4o and GPT-3.5 are the most biased models, showing significant bias in all three industries. Conversely, Gemini-1.5-Pro, Llama3-8b-Instruct, and Llama3-70b-Instruct are the least biased. The hiring bias of all LLMs, except for Llama3-8b-Instruct and Claude-3-Sonnet, remains consistent regardless of random expansion or reduction of resume content. Finally, we offer a user-friendly demo to facilitate adoption and practical application of the framework.
6/26/2024