Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
2405.16908
0
0
Abstract
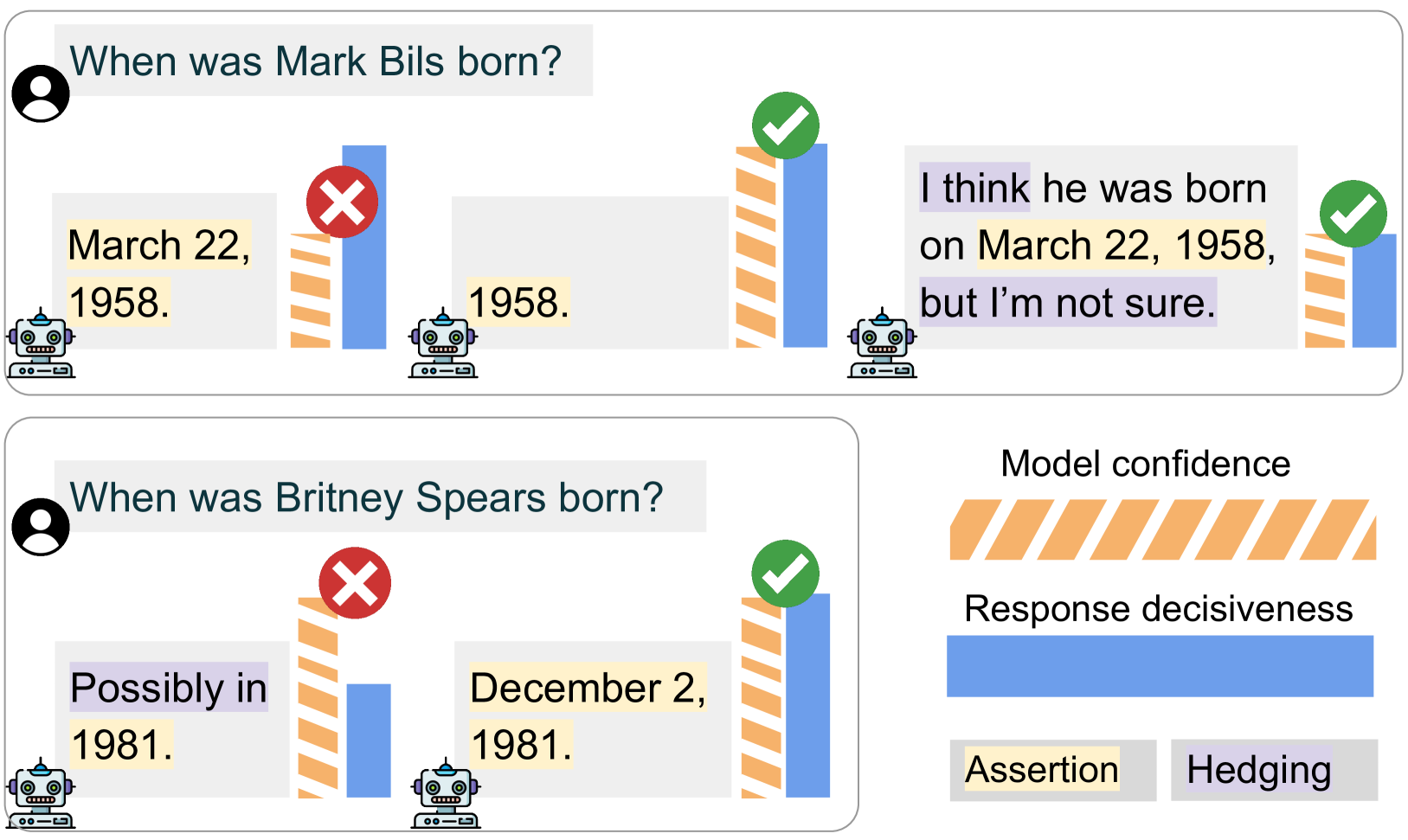
We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., I'm not sure, but I think...). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
Create account to get full access
Overview
- This paper examines whether large language models (LLMs) can accurately convey their inherent uncertainty in their responses.
- The researchers explore techniques to enable LLMs to express their uncertainty in a "faithful" way, where the model's expressed uncertainty matches its actual confidence or lack thereof.
- Accurately quantifying and communicating model uncertainty is crucial for real-world applications where mistakes can have serious consequences.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly powerful, but they don't always know when they're uncertain. This paper explores ways to make LLMs better at acknowledging and expressing their own uncertainty.
Imagine you ask an LLM a question and it responds with complete confidence, even if it's not totally sure of the answer. That could be problematic in high-stakes situations like medical diagnosis or financial advice. The researchers want to find methods to make LLMs "uncertainty-aware" - able to quantify and communicate how certain they are about their responses.
By making LLMs more transparent about their level of confidence, we can better understand the limitations of the model and make more informed decisions. [This aligns with the growing emphasis on confidence and uncertainty quantification in AI systems.](https://aimodels.fyi/papers/arxiv/importance-uncertainty-decision-making-large-language-models)
Technical Explanation
The paper proposes several techniques to enable LLMs to faithfully express their intrinsic uncertainty. This includes training the model to output a calibrated uncertainty score along with its textual responses, and using ensemble methods to better capture the model's inherent uncertainty.
The researchers evaluate these approaches on a range of tasks, including language understanding, open-ended dialogue, and question answering. They find that incorporating uncertainty awareness can improve the model's reliability and transparency, without significantly compromising its overall performance.
Importantly, the paper also highlights several limitations and caveats of the proposed methods. For example, the researchers note that accurately quantifying and expressing uncertainty remains a challenging problem, especially for complex, open-ended tasks.
Critical Analysis
The paper makes a strong case for the importance of uncertainty awareness in LLMs, and the proposed techniques represent a meaningful step forward. However, the researchers acknowledge that faithfully expressing model uncertainty is an inherently difficult challenge that requires further research.
One potential limitation is that the evaluation focuses primarily on textual responses, whereas many real-world applications of LLMs involve multimodal inputs and outputs. Extending the uncertainty-aware techniques to these more complex scenarios could present additional challenges.
Additionally, the paper does not delve deeply into the societal implications of LLMs that can better communicate their uncertainty. While this could improve decision-making in high-stakes domains, it also raises questions about how users will interpret and act upon expressed uncertainty.
Conclusion
This paper makes a compelling argument for the importance of enabling large language models to faithfully express their intrinsic uncertainty. By developing techniques to quantify and communicate model confidence, the researchers aim to improve the reliability and transparency of these powerful AI systems.
While the proposed approaches represent an important step forward, the authors acknowledge that accurately capturing and conveying uncertainty remains a complex and ongoing challenge. Continued research in this area could have significant implications for the responsible development and deployment of large language models in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Large Language Models Must Be Taught to Know What They Don't Know
Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, Andrew Gordon Wilson
0
0
When using large language models (LLMs) in high-stakes applications, we need to know when we can trust their predictions. Some works argue that prompting high-performance LLMs is sufficient to produce calibrated uncertainties, while others introduce sampling methods that can be prohibitively expensive. In this work, we first argue that prompting on its own is insufficient to achieve good calibration and then show that fine-tuning on a small dataset of correct and incorrect answers can create an uncertainty estimate with good generalization and small computational overhead. We show that a thousand graded examples are sufficient to outperform baseline methods and that training through the features of a model is necessary for good performance and tractable for large open-source models when using LoRA. We also investigate the mechanisms that enable reliable LLM uncertainty estimation, finding that many models can be used as general-purpose uncertainty estimators, applicable not just to their own uncertainties but also the uncertainty of other models. Lastly, we show that uncertainty estimates inform human use of LLMs in human-AI collaborative settings through a user study.
6/13/2024

To Believe or Not to Believe Your LLM
Yasin Abbasi Yadkori, Ilja Kuzborskij, Andr'as Gyorgy, Csaba Szepesv'ari
0
0
We explore uncertainty quantification in large language models (LLMs), with the goal to identify when uncertainty in responses given a query is large. We simultaneously consider both epistemic and aleatoric uncertainties, where the former comes from the lack of knowledge about the ground truth (such as about facts or the language), and the latter comes from irreducible randomness (such as multiple possible answers). In particular, we derive an information-theoretic metric that allows to reliably detect when only epistemic uncertainty is large, in which case the output of the model is unreliable. This condition can be computed based solely on the output of the model obtained simply by some special iterative prompting based on the previous responses. Such quantification, for instance, allows to detect hallucinations (cases when epistemic uncertainty is high) in both single- and multi-answer responses. This is in contrast to many standard uncertainty quantification strategies (such as thresholding the log-likelihood of a response) where hallucinations in the multi-answer case cannot be detected. We conduct a series of experiments which demonstrate the advantage of our formulation. Further, our investigations shed some light on how the probabilities assigned to a given output by an LLM can be amplified by iterative prompting, which might be of independent interest.
6/5/2024
💬
I'm Not Sure, But...: Examining the Impact of Large Language Models' Uncertainty Expression on User Reliance and Trust
Sunnie S. Y. Kim, Q. Vera Liao, Mihaela Vorvoreanu, Stephanie Ballard, Jennifer Wortman Vaughan
0
0
Widely deployed large language models (LLMs) can produce convincing yet incorrect outputs, potentially misleading users who may rely on them as if they were correct. To reduce such overreliance, there have been calls for LLMs to communicate their uncertainty to end users. However, there has been little empirical work examining how users perceive and act upon LLMs' expressions of uncertainty. We explore this question through a large-scale, pre-registered, human-subject experiment (N=404) in which participants answer medical questions with or without access to responses from a fictional LLM-infused search engine. Using both behavioral and self-reported measures, we examine how different natural language expressions of uncertainty impact participants' reliance, trust, and overall task performance. We find that first-person expressions (e.g., I'm not sure, but...) decrease participants' confidence in the system and tendency to agree with the system's answers, while increasing participants' accuracy. An exploratory analysis suggests that this increase can be attributed to reduced (but not fully eliminated) overreliance on incorrect answers. While we observe similar effects for uncertainty expressed from a general perspective (e.g., It's not clear, but...), these effects are weaker and not statistically significant. Our findings suggest that using natural language expressions of uncertainty may be an effective approach for reducing overreliance on LLMs, but that the precise language used matters. This highlights the importance of user testing before deploying LLMs at scale.
5/16/2024
💬
FaithLM: Towards Faithful Explanations for Large Language Models
Yu-Neng Chuang, Guanchu Wang, Chia-Yuan Chang, Ruixiang Tang, Shaochen Zhong, Fan Yang, Mengnan Du, Xuanting Cai, Xia Hu
0
0
Large Language Models (LLMs) have become proficient in addressing complex tasks by leveraging their extensive internal knowledge and reasoning capabilities. However, the black-box nature of these models complicates the task of explaining their decision-making processes. While recent advancements demonstrate the potential of leveraging LLMs to self-explain their predictions through natural language (NL) explanations, their explanations may not accurately reflect the LLMs' decision-making process due to a lack of fidelity optimization on the derived explanations. Measuring the fidelity of NL explanations is a challenging issue, as it is difficult to manipulate the input context to mask the semantics of these explanations. To this end, we introduce FaithLM to explain the decision of LLMs with NL explanations. Specifically, FaithLM designs a method for evaluating the fidelity of NL explanations by incorporating the contrary explanations to the query process. Moreover, FaithLM conducts an iterative process to improve the fidelity of derived explanations. Experiment results on three datasets from multiple domains demonstrate that FaithLM can significantly improve the fidelity of derived explanations, which also provides a better alignment with the ground-truth explanations.
6/27/2024