Fast and Adaptive Questionnaires for Voting Advice Applications

0

Sign in to get full access
Overview
- This paper presents a method for creating fast and adaptive questionnaires for Voting Advice Applications (VAAs) - tools that help voters compare their policy positions to those of political candidates.
- The key ideas are using active learning to efficiently collect user data, and employing dimensionality reduction and imputation techniques to provide personalized recommendations with fewer questions.
- The goal is to create VAAs that can accurately measure user preferences and provide voting advice while minimizing the burden on users.
Plain English Explanation
The paper tackles the challenge of creating effective Voting Advice Applications (VAAs) - tools that help voters compare their policy positions to those of political candidates. VAAs typically work by presenting users with a series of statements on political issues and having them indicate their level of agreement. Based on the user's responses, the VAA can then suggest which candidates the user is most aligned with.
The main problem is that traditional VAAs often require users to answer a large number of questions, which can be time-consuming and frustrating. The researchers in this paper propose a new approach to make VAAs faster and more adaptive to each individual user.
The key idea is to use "active learning" - a machine learning technique that allows the system to intelligently select the most informative questions to ask each user, rather than presenting a fixed set of questions. By focusing on the most relevant questions, the system can gather the necessary information to provide voting advice with far fewer questions.
Additionally, the researchers use dimensionality reduction and data imputation methods to fill in missing responses and infer a user's full policy preferences from their limited set of answers. This allows the VAA to generate personalized recommendations without requiring users to answer every single question.
The end result is a VAA that can efficiently measure user preferences and provide voting advice, while minimizing the burden on users. This could make VAAs more accessible and useful for a wider range of voters.
Technical Explanation
The paper describes a method for creating fast and adaptive Voting Advice Applications (VAAs) using a combination of active learning, dimensionality reduction, and imputation techniques.
The active learning approach involves an iterative process of presenting users with a small number of questions, analyzing their responses, and then intelligently selecting the next most informative questions to ask. This allows the system to efficiently gather the data necessary to infer the user's full policy preferences.
The researchers employ dimensionality reduction techniques, such as principal component analysis, to identify the key underlying dimensions that explain the most variance in user responses. This allows the system to make accurate inferences about a user's positions on a wide range of policy issues from their responses to a limited set of questions.
To further reduce the burden on users, the researchers use imputation methods to fill in missing responses. By leveraging the patterns observed in the responses of other users, the system can estimate a user's likely positions on unasked questions.
Through this combination of active learning, dimensionality reduction, and imputation, the researchers demonstrate that they can create VAAs that can accurately measure user preferences and provide personalized voting advice while asking users to answer significantly fewer questions compared to traditional VAA approaches.
Critical Analysis
The paper presents a promising approach for improving the efficiency and user experience of Voting Advice Applications. The use of active learning, dimensionality reduction, and imputation techniques is well-justified and could lead to substantial benefits for VAA users.
One potential limitation, however, is the reliance on the specific dimensionality reduction and imputation methods employed. While the researchers demonstrate the effectiveness of their approach, it would be valuable to explore the performance of alternative techniques and understand how sensitive the results are to the choice of algorithms.
Additionally, the paper does not address potential biases or fairness considerations that could arise from the active learning process. There may be concerns that the system could preferentially select questions that favor certain demographic groups or political leanings. Further research would be needed to ensure the fairness and inclusivity of the VAA recommendations.
Another area for further exploration is the potential impact of this approach on user engagement and trust. While reducing the number of questions may improve the user experience, it could also raise concerns about the comprehensiveness of the VAA's assessment. Careful user testing and feedback would be essential to striking the right balance.
Overall, the research presented in this paper represents an important step forward in enhancing the efficiency and accessibility of Voting Advice Applications. With further refinement and consideration of potential limitations, this approach could significantly improve the ability of voters to make informed choices.
Conclusion
This paper introduces a novel method for creating fast and adaptive Voting Advice Applications (VAAs) that can accurately measure user preferences and provide personalized voting advice while minimizing the burden on users.
By leveraging active learning, dimensionality reduction, and imputation techniques, the researchers demonstrate that VAAs can efficiently gather the necessary data to generate recommendations, even when users only answer a limited set of questions.
This approach has the potential to make VAAs more accessible and user-friendly, potentially encouraging greater civic engagement and informed decision-making among voters. However, further research is needed to address potential biases and ensure the fairness and transparency of the VAA recommendations.
Overall, this work represents an important advancement in the field of VAA design and could have significant implications for enhancing the ability of citizens to participate in the democratic process.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fast and Adaptive Questionnaires for Voting Advice Applications
Fynn Bachmann, Cristina Sarasua, Abraham Bernstein
The effectiveness of Voting Advice Applications (VAA) is often compromised by the length of their questionnaires. To address user fatigue and incomplete responses, some applications (such as the Swiss Smartvote) offer a condensed version of their questionnaire. However, these condensed versions can not ensure the accuracy of recommended parties or candidates, which we show to remain below 40%. To tackle these limitations, this work introduces an adaptive questionnaire approach that selects subsequent questions based on users' previous answers, aiming to enhance recommendation accuracy while reducing the number of questions posed to the voters. Our method uses an encoder and decoder module to predict missing values at any completion stage, leveraging a two-dimensional latent space reflective of political science's traditional methods for visualizing political orientations. Additionally, a selector module is proposed to determine the most informative subsequent question based on the voter's current position in the latent space and the remaining unanswered questions. We validated our approach using the Smartvote dataset from the Swiss Federal elections in 2019, testing various spatial models and selection methods to optimize the system's predictive accuracy. Our findings indicate that employing the IDEAL model both as encoder and decoder, combined with a PosteriorRMSE method for question selection, significantly improves the accuracy of recommendations, achieving 74% accuracy after asking the same number of questions as in the condensed version.
Read more4/3/2024

0
Selectively Answering Visual Questions
Julian Martin Eisenschlos, Hern'an Maina, Guido Ivetta, Luciana Benotti
Recently, large multi-modal models (LMMs) have emerged with the capacity to perform vision tasks such as captioning and visual question answering (VQA) with unprecedented accuracy. Applications such as helping the blind or visually impaired have a critical need for precise answers. It is specially important for models to be well calibrated and be able to quantify their uncertainty in order to selectively decide when to answer and when to abstain or ask for clarifications. We perform the first in-depth analysis of calibration methods and metrics for VQA with in-context learning LMMs. Studying VQA on two answerability benchmarks, we show that the likelihood score of visually grounded models is better calibrated than in their text-only counterparts for in-context learning, where sampling based methods are generally superior, but no clear winner arises. We propose Avg BLEU, a calibration score combining the benefits of both sampling and likelihood methods across modalities.
Read more6/4/2024
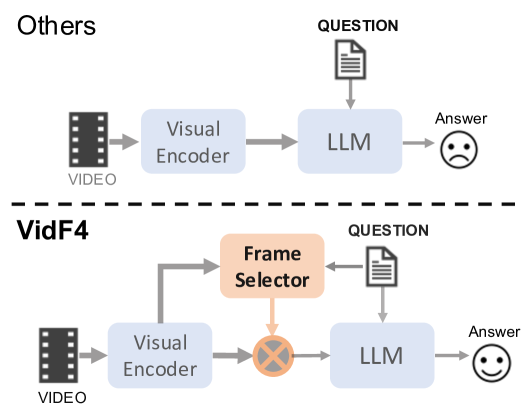
0
End-to-End Video Question Answering with Frame Scoring Mechanisms and Adaptive Sampling
Jianxin Liang, Xiaojun Meng, Yueqian Wang, Chang Liu, Qun Liu, Dongyan Zhao
Video Question Answering (VideoQA) has emerged as a challenging frontier in the field of multimedia processing, requiring intricate interactions between visual and textual modalities. Simply uniformly sampling frames or indiscriminately aggregating frame-level visual features often falls short in capturing the nuanced and relevant contexts of videos to well perform VideoQA. To mitigate these issues, we propose VidF4, a novel VideoQA framework equipped with tailored frame selection strategy for effective and efficient VideoQA. We propose three frame-scoring mechanisms that consider both question relevance and inter-frame similarity to evaluate the importance of each frame for a given question on the video. Furthermore, we design a differentiable adaptive frame sampling mechanism to facilitate end-to-end training for the frame selector and answer generator. The experimental results across three widely adopted benchmarks demonstrate that our model consistently outperforms existing VideoQA methods, establishing a new SOTA across NExT-QA (+0.3%), STAR (+0.9%), and TVQA (+1.0%). Furthermore, through both quantitative and qualitative analyses, we validate the effectiveness of each design choice.
Read more7/24/2024

0
Towards Flexible Evaluation for Generative Visual Question Answering
Huishan Ji, Qingyi Si, Zheng Lin, Weiping Wang
Throughout rapid development of multimodal large language models, a crucial ingredient is a fair and accurate evaluation of their multimodal comprehension abilities. Although Visual Question Answering (VQA) could serve as a developed test field, limitations of VQA evaluation, like the inflexible pattern of Exact Match, have hindered MLLMs from demonstrating their real capability and discourage rich responses. Therefore, this paper proposes the use of semantics-based evaluators for assessing unconstrained open-ended responses on VQA datasets. As characteristics of VQA have made such evaluation significantly different than the traditional Semantic Textual Similarity (STS) task, to systematically analyze the behaviour and compare the performance of various evaluators including LLM-based ones, we proposes three key properties, i.e., Alignment, Consistency and Generalization, and a corresponding dataset Assessing VQA Evaluators (AVE) to facilitate analysis. In addition, this paper proposes a Semantically Flexible VQA Evaluator (SFVE) with meticulous design based on the unique features of VQA evaluation. Experimental results verify the feasibility of model-based VQA evaluation and effectiveness of the proposed evaluator that surpasses existing semantic evaluators by a large margin. The proposed training scheme generalizes to both the BERT-like encoders and decoder-only LLM.
Read more8/2/2024