End-to-End Video Question Answering with Frame Scoring Mechanisms and Adaptive Sampling

0
Sign in to get full access
Overview
- This paper proposes an end-to-end video question answering (VQA) system that uses frame scoring mechanisms and adaptive sampling to improve performance.
- The system aims to efficiently process video frames and extract relevant information to answer questions about the video content.
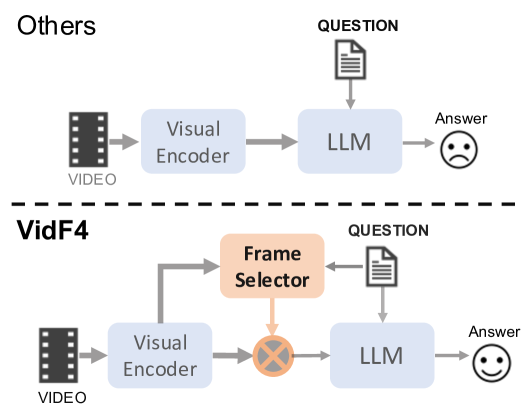
- Key contributions include a frame scoring mechanism to identify the most informative frames, and an adaptive sampling approach to dynamically select the frames used for inference.
Plain English Explanation
The researchers developed a system that can answer questions about the content of a video. This is an important task for many real-world applications, like helping people find information in video libraries or assisting with video analysis.
Their approach has two main innovations:
-
Frame Scoring Mechanism: The system evaluates each video frame and assigns it a "score" that indicates how useful that frame is for answering the question. This allows the system to focus on the most relevant parts of the video, rather than treating all frames equally.
-
Adaptive Sampling: Based on the frame scores, the system dynamically selects which frames to use when answering the question. It can choose to use more frames for complex questions that require more information, and fewer frames for simpler questions. This adaptive approach helps the system run efficiently while still providing accurate answers.
By incorporating these two techniques, the researchers were able to build an end-to-end VQA system that performs well while using computational resources more efficiently than previous approaches.
Technical Explanation
The key components of the proposed VQA system are:
-
Frame Scoring Mechanism: The system includes a frame scoring module that evaluates the relevance of each video frame to the question being asked. This is done by passing the frame and question through a neural network that outputs a relevance score for that frame.
-
Adaptive Sampling: Based on the frame scores, the system dynamically selects a subset of the video frames to use for answer prediction. For simple questions, it may only need to look at a few key frames. For more complex questions, it can adaptively sample a larger number of frames to gather more relevant information.
-
Answer Prediction: The selected frames and question are then passed through another neural network that outputs the final answer to the question.
The researchers evaluated their system on standard VQA benchmarks and showed that it achieves competitive performance while being more computationally efficient than previous end-to-end approaches. The adaptive sampling technique, in particular, allows the system to focus its computational resources on the most informative parts of the video.
Critical Analysis
One potential limitation of this work is that the frame scoring mechanism is trained separately from the final answer prediction model. An interesting direction for future research could be to investigate end-to-end training approaches that jointly optimize the frame scoring and answer prediction components.
Additionally, the experiments in the paper were conducted on relatively short videos from existing VQA datasets. It would be valuable to further evaluate the system's performance on longer, more complex videos that may require more sophisticated reasoning and temporal integration.
Overall, the proposed techniques of frame scoring and adaptive sampling represent a promising step towards more efficient and effective video question answering systems.
Conclusion
This paper presents an innovative end-to-end video question answering system that uses frame scoring mechanisms and adaptive sampling to improve performance and efficiency. By focusing on the most relevant video frames and dynamically adjusting the computational resources used, the system can provide accurate answers while using fewer computational resources than previous approaches.
The key ideas introduced in this work, such as the frame scoring module and the adaptive sampling strategy, could have broader applications in other video understanding tasks beyond just question answering. As the volume of video data continues to grow, developing efficient techniques for processing and extracting meaningful information from videos will become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
End-to-End Video Question Answering with Frame Scoring Mechanisms and Adaptive Sampling
Jianxin Liang, Xiaojun Meng, Yueqian Wang, Chang Liu, Qun Liu, Dongyan Zhao
Video Question Answering (VideoQA) has emerged as a challenging frontier in the field of multimedia processing, requiring intricate interactions between visual and textual modalities. Simply uniformly sampling frames or indiscriminately aggregating frame-level visual features often falls short in capturing the nuanced and relevant contexts of videos to well perform VideoQA. To mitigate these issues, we propose VidF4, a novel VideoQA framework equipped with tailored frame selection strategy for effective and efficient VideoQA. We propose three frame-scoring mechanisms that consider both question relevance and inter-frame similarity to evaluate the importance of each frame for a given question on the video. Furthermore, we design a differentiable adaptive frame sampling mechanism to facilitate end-to-end training for the frame selector and answer generator. The experimental results across three widely adopted benchmarks demonstrate that our model consistently outperforms existing VideoQA methods, establishing a new SOTA across NExT-QA (+0.3%), STAR (+0.9%), and TVQA (+1.0%). Furthermore, through both quantitative and qualitative analyses, we validate the effectiveness of each design choice.
Read more7/24/2024

0
Too Many Frames, not all Useful:Efficient Strategies for Long-Form Video QA
Jongwoo Park, Kanchana Ranasinghe, Kumara Kahatapitiya, Wonjeong Ryoo, Donghyun Kim, Michael S. Ryoo
Long-form videos that span across wide temporal intervals are highly information redundant and contain multiple distinct events or entities that are often loosely-related. Therefore, when performing long-form video question answering (LVQA),all information necessary to generate a correct response can often be contained within a small subset of frames. Recent literature explore the use of large language models (LLMs) in LVQA benchmarks, achieving exceptional performance, while relying on vision language models (VLMs) to convert all visual content within videos into natural language. Such VLMs often independently caption a large number of frames uniformly sampled from long videos, which is not efficient and can mostly be redundant. Questioning these decision choices, we explore optimal strategies for key-frame selection and sequence-aware captioning, that can significantly reduce these redundancies. We propose two novel approaches that improve each of aspects, namely Hierarchical Keyframe Selector and Sequential Visual LLM. Our resulting framework termed LVNet achieves state-of-the-art performance across three benchmark LVQA datasets. Our code will be released publicly.
Read more6/18/2024

0
Causal Understanding For Video Question Answering
Bhanu Prakash Reddy Guda, Tanmay Kulkarni, Adithya Sampath, Swarnashree Mysore Sathyendra
Video Question Answering is a challenging task, which requires the model to reason over multiple frames and understand the interaction between different objects to answer questions based on the context provided within the video, especially in datasets like NExT-QA (Xiao et al., 2021a) which emphasize on causal and temporal questions. Previous approaches leverage either sub-sampled information or causal intervention techniques along with complete video features to tackle the NExT-QA task. In this work we elicit the limitations of these approaches and propose solutions along four novel directions of improvements on theNExT-QA dataset. Our approaches attempts to compensate for the shortcomings in the previous works by systematically attacking each of these problems by smartly sampling frames, explicitly encoding actions and creating interventions that challenge the understanding of the model. Overall, for both single-frame (+6.3%) and complete-video (+1.1%) based approaches, we obtain the state-of-the-art results on NExT-QA dataset.
Read more7/31/2024

0
VideoQA-SC: Adaptive Semantic Communication for Video Question Answering
Jiangyuan Guo, Wei Chen, Yuxuan Sun, Jialong Xu, Bo Ai
Although semantic communication (SC) has shown its potential in efficiently transmitting multi-modal data such as text, speeches and images, SC for videos has focused primarily on pixel-level reconstruction. However, these SC systems may be suboptimal for downstream intelligent tasks. Moreover, SC systems without pixel-level video reconstruction present advantages by achieving higher bandwidth efficiency and real-time performance of various intelligent tasks. The difficulty in such system design lies in the extraction of task-related compact semantic representations and their accurate delivery over noisy channels. In this paper, we propose an end-to-end SC system for video question answering (VideoQA) tasks called VideoQA-SC. Our goal is to accomplish VideoQA tasks directly based on video semantics over noisy or fading wireless channels, bypassing the need for video reconstruction at the receiver. To this end, we develop a spatiotemporal semantic encoder for effective video semantic extraction, and a learning-based bandwidth-adaptive deep joint source-channel coding (DJSCC) scheme for efficient and robust video semantic transmission. Experiments demonstrate that VideoQA-SC outperforms traditional and advanced DJSCC-based SC systems that rely on video reconstruction at the receiver under a wide range of channel conditions and bandwidth constraints. In particular, when the signal-to-noise ratio is low, VideoQA-SC can improve the answer accuracy by 5.17% while saving almost 99.5% of the bandwidth at the same time, compared with the advanced DJSCC-based SC system. Our results show the great potential of task-oriented SC system design for video applications.
Read more6/28/2024