Fast Asymmetric Factorization for Large Scale Multiple Kernel Clustering
2405.16447
0
0
Abstract
Kernel methods are extensively employed for nonlinear data clustering, yet their effectiveness heavily relies on selecting suitable kernels and associated parameters, posing challenges in advance determination. In response, Multiple Kernel Clustering (MKC) has emerged as a solution, allowing the fusion of information from multiple base kernels for clustering. However, both early fusion and late fusion methods for large-scale MKC encounter challenges in memory and time constraints, necessitating simultaneous optimization of both aspects. To address this issue, we propose Efficient Multiple Kernel Concept Factorization (EMKCF), which constructs a new sparse kernel matrix inspired by local regression to achieve memory efficiency. EMKCF learns consensus and individual representations by extending orthogonal concept factorization to handle multiple kernels for time efficiency. Experimental results demonstrate the efficiency and effectiveness of EMKCF on benchmark datasets compared to state-of-the-art methods. The proposed method offers a straightforward, scalable, and effective solution for large-scale MKC tasks.
Create account to get full access
Overview
- Presents a fast asymmetric factorization method for large-scale multiple kernel clustering
- Addresses the computational and memory challenges of existing multiple kernel clustering techniques
- Focuses on improving the efficiency of the matrix factorization step, which is a key component of multiple kernel clustering
Plain English Explanation
In the world of data analysis, clustering is a powerful technique that helps us organize and understand complex datasets. Multiple kernel clustering is a specific type of clustering that combines information from different data sources, or "kernels," to improve the accuracy of the clustering process. However, applying multiple kernel clustering to large-scale datasets can be computationally intensive and memory-intensive, making it challenging to use in real-world applications.
This paper presents a new method called "Fast Asymmetric Factorization" that aims to make multiple kernel clustering more efficient and scalable. The key idea is to use a special type of matrix factorization, called "asymmetric factorization," to represent the data in a more compact and efficient way. This allows the clustering algorithm to operate on a smaller and more manageable representation of the data, without losing important information.
The paper demonstrates that this new factorization method can significantly improve the speed and memory usage of multiple kernel clustering, making it practical for use on large-scale datasets. This is important because many real-world problems, such as image recognition or customer segmentation, involve large amounts of data from multiple sources, and efficient clustering techniques are essential for unlocking insights from this data.
Technical Explanation
The paper introduces a novel matrix factorization technique called "Fast Asymmetric Factorization" (FAF) to address the computational and memory challenges of large-scale multiple kernel clustering. The key idea behind FAF is to represent the data in a more compact and efficient way using an asymmetric factorization, where the left and right matrices have different dimensions.
Specifically, the authors propose a two-step approach:
-
Asymmetric Factorization: The first step is to perform an asymmetric factorization of the multiple kernel matrix, which encodes the similarity between data points across different data sources. This factorization results in a left matrix with a smaller number of columns, reducing the memory and computational requirements of the subsequent clustering step.
-
Clustering: The second step is to perform the multiple kernel clustering algorithm on the factorized representation of the data. The authors show that this approach can significantly improve the efficiency of the clustering process, especially for large-scale datasets.
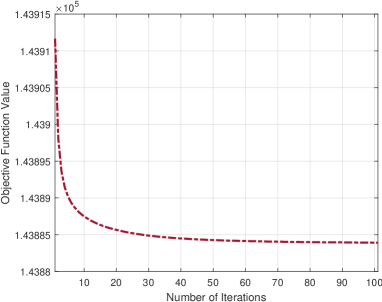
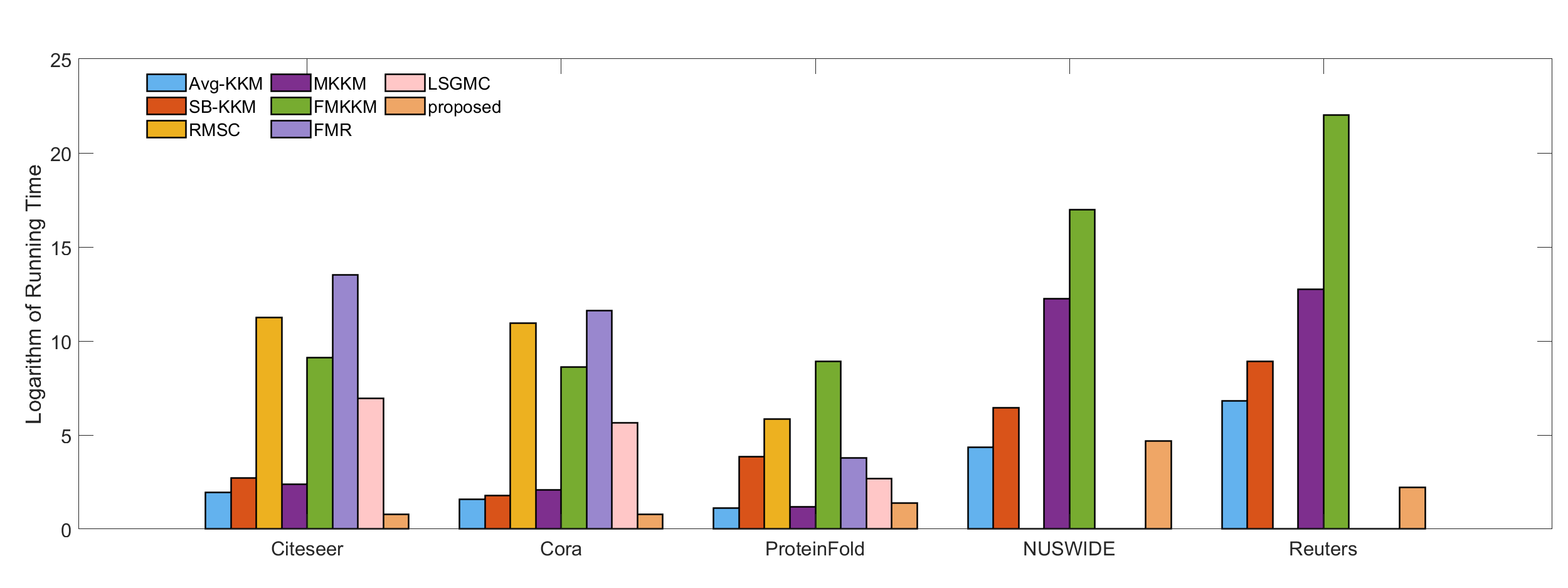
The paper includes a detailed analysis of the time and memory complexity of the proposed FAF method, and it compares its performance to existing multiple kernel clustering techniques on several benchmark datasets. The results demonstrate that FAF can achieve significant speedups (up to 20x) and memory savings (up to 90%) while maintaining comparable clustering accuracy.
Critical Analysis
The paper presents a promising approach for addressing the computational and memory challenges of large-scale multiple kernel clustering. The key strength of the proposed FAF method is its ability to effectively compress the data representation using an asymmetric factorization, which enables efficient clustering without sacrificing accuracy.
One potential limitation of the approach is that the success of the factorization step may depend on the specific structure and properties of the data. The authors do not provide a comprehensive analysis of the conditions under which the asymmetric factorization will be most effective, and it would be valuable to understand the types of datasets or applications where FAF is likely to perform best.
Additionally, the paper does not explore the potential trade-offs between the level of compression (i.e., the number of columns in the left matrix) and the clustering accuracy. It would be interesting to see how these factors interact and whether there are ways to dynamically adjust the factorization to balance efficiency and performance.
Finally, while the paper demonstrates the effectiveness of FAF on several benchmark datasets, it would be valuable to see how the method performs on real-world, large-scale applications with diverse data sources and complex clustering structures. Evaluating the scalability and robustness of FAF in these more challenging scenarios could provide further insights into its practical utility.
Conclusion
The "Fast Asymmetric Factorization for Large Scale Multiple Kernel Clustering" paper presents a novel matrix factorization technique that addresses the computational and memory challenges of applying multiple kernel clustering to large-scale datasets. By representing the data in a more compact and efficient way using an asymmetric factorization, the proposed FAF method can significantly improve the speed and memory usage of the clustering process without sacrificing accuracy.
This work has important implications for a wide range of applications that rely on large, complex datasets from multiple sources, such as image recognition, customer segmentation, and scientific data analysis. By making multiple kernel clustering more scalable and accessible, the FAF method has the potential to unlock new insights and enable more effective data-driven decision-making in a variety of domains.
Overall, this paper represents an important contribution to the field of large-scale clustering and data analysis, and the insights and techniques presented could inspire further advancements in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Fast and Scalable Multi-Kernel Encoder Classifier
Cencheng Shen
0
0
This paper introduces a new kernel-based classifier by viewing kernel matrices as generalized graphs and leveraging recent progress in graph embedding techniques. The proposed method facilitates fast and scalable kernel matrix embedding, and seamlessly integrates multiple kernels to enhance the learning process. Our theoretical analysis offers a population-level characterization of this approach using random variables. Empirically, our method demonstrates superior running time compared to standard approaches such as support vector machines and two-layer neural network, while achieving comparable classification accuracy across various simulated and real datasets.
6/5/2024
Imbalanced Data Clustering using Equilibrium K-Means
Yudong He
0
0
Centroid-based clustering algorithms, such as hard K-means (HKM) and fuzzy K-means (FKM), have suffered from learning bias towards large clusters. Their centroids tend to be crowded in large clusters, compromising performance when the true underlying data groups vary in size (i.e., imbalanced data). To address this, we propose a new clustering objective function based on the Boltzmann operator, which introduces a novel centroid repulsion mechanism, where data points surrounding the centroids repel other centroids. Larger clusters repel more, effectively mitigating the issue of large cluster learning bias. The proposed new algorithm, called equilibrium K-means (EKM), is simple, alternating between two steps; resource-saving, with the same time and space complexity as FKM; and scalable to large datasets via batch learning. We substantially evaluate the performance of EKM on synthetic and real-world datasets. The results show that EKM performs competitively on balanced data and significantly outperforms benchmark algorithms on imbalanced data. Deep clustering experiments demonstrate that EKM is a better alternative to HKM and FKM on imbalanced data as more discriminative representation can be obtained. Additionally, we reformulate HKM, FKM, and EKM in a general form of gradient descent and demonstrate how this general form facilitates a uniform study of K-means algorithms.
6/7/2024
One-Step Late Fusion Multi-view Clustering with Compressed Subspace
Qiyuan Ou, Pei Zhang, Sihang Zhou, En Zhu
0
0
Late fusion multi-view clustering (LFMVC) has become a rapidly growing class of methods in the multi-view clustering (MVC) field, owing to its excellent computational speed and clustering performance. One bottleneck faced by existing late fusion methods is that they are usually aligned to the average kernel function, which makes the clustering performance highly dependent on the quality of datasets. Another problem is that they require subsequent k-means clustering after obtaining the consensus partition matrix to get the final discrete labels, and the resulting separation of the label learning and cluster structure optimization processes limits the integrity of these models. To address the above issues, we propose an integrated framework named One-Step Late Fusion Multi-view Clustering with Compressed Subspace (OS-LFMVC-CS). Specifically, we use the consensus subspace to align the partition matrix while optimizing the partition fusion, and utilize the fused partition matrix to guide the learning of discrete labels. A six-step iterative optimization approach with verified convergence is proposed. Sufficient experiments on multiple datasets validate the effectiveness and efficiency of our proposed method.
5/29/2024
Rectified Gaussian kernel multi-view k-means clustering
Kristina P. Sinaga
0
0
In this paper, we show two new variants of multi-view k-means (MVKM) algorithms to address multi-view data. The general idea is to outline the distance between $h$-th view data points $x_i^h$ and $h$-th view cluster centers $a_k^h$ in a different manner of centroid-based approach. Unlike other methods, our proposed methods learn the multi-view data by calculating the similarity using Euclidean norm in the space of Gaussian-kernel, namely as multi-view k-means with exponent distance (MVKM-ED). By simultaneously aligning the stabilizer parameter $p$ and kernel coefficients $beta^h$, the compression of Gaussian-kernel based weighted distance in Euclidean norm reduce the sensitivity of MVKM-ED. To this end, this paper designated as Gaussian-kernel multi-view k-means (GKMVKM) clustering algorithm. Numerical evaluation of five real-world multi-view data demonstrates the robustness and efficiency of our proposed MVKM-ED and GKMVKM approaches.
5/17/2024