Imbalanced Data Clustering using Equilibrium K-Means

0
Sign in to get full access
Overview
- This paper introduces a novel approach to fuzzy K-means clustering that overcomes the uniform effect, a common issue with traditional K-means clustering on imbalanced datasets.
- The proposed method, called Equilibrium K-means, learns cluster centroids that are better aligned with the underlying data distribution, leading to improved clustering performance on imbalanced problems.
- The authors also present a deep clustering framework that leverages the Equilibrium K-means algorithm, demonstrating its effectiveness on large-scale datasets beyond the ImageNet benchmark.
Plain English Explanation
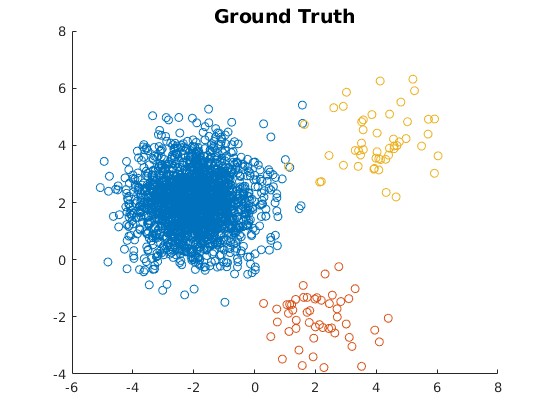
Fuzzy K-means clustering is a popular technique for grouping data into distinct clusters. However, it can struggle with datasets that have an imbalanced distribution, where some clusters are much larger or more dense than others. This can lead to the "uniform effect," where the clustering algorithm fails to accurately capture the true structure of the data.
The researchers behind this paper have developed a new approach called Equilibrium K-means that helps overcome this limitation. The key idea is to learn cluster centroids that are better aligned with the underlying data distribution, rather than simply minimizing the distance between data points and their assigned centroids.
This is achieved through a novel optimization formulation that encourages the clusters to reach an "equilibrium" state, where the sizes and densities of the clusters are more balanced. As a result, the Equilibrium K-means algorithm can produce more accurate and meaningful clusters, even on imbalanced datasets.
The authors also demonstrate how this technique can be integrated into a deep learning-based clustering framework, Scaling up Deep Clustering Methods Beyond ImageNet. This allows the Equilibrium K-means approach to be applied to large-scale datasets, beyond the common ImageNet benchmark, with impressive results.
Technical Explanation
The paper introduces a new clustering algorithm called Equilibrium K-means (EKM), which builds upon the traditional Fuzzy K-means approach. EKM aims to learn cluster centroids that are better aligned with the underlying data distribution, addressing the common issue of the "uniform effect" in imbalanced datasets.
The key innovation of EKM is its optimization formulation, which incorporates a term that encourages the clusters to reach an "equilibrium" state. This means that the algorithm not only minimizes the distance between data points and their assigned centroids, but also considers the relative sizes and densities of the clusters. By doing so, EKM is able to produce more accurate and meaningful clusters, even when the dataset has an imbalanced distribution.
The authors also present a deep clustering framework that integrates the EKM algorithm, Scaling up Deep Clustering Methods Beyond ImageNet. This allows the EKM approach to be applied to large-scale datasets, showcasing its effectiveness beyond the common ImageNet benchmark.
Additionally, the paper explores the connection between EKM and other related concepts, such as Rectified Gaussian Kernel Multi-View K-means and Fast Asymmetric Factorization for Large-Scale Multiple Kernel, providing a broader theoretical understanding of the proposed method.
Critical Analysis
The paper presents a novel and well-designed clustering algorithm that addresses an important issue in the field of unsupervised learning. The Equilibrium K-means approach offers a significant improvement over traditional K-means clustering, especially on imbalanced datasets.
However, the authors acknowledge that the EKM algorithm may not be suitable for all types of data distributions and could potentially struggle with highly complex or overlapping clusters. Additionally, the method's performance may be sensitive to the choice of hyperparameters, which could require careful tuning in certain applications.
Further research could explore ways to make the EKM algorithm more robust and adaptive to different data characteristics, potentially by incorporating additional regularization terms or exploring alternative optimization strategies. Empirical studies on a wider range of real-world datasets would also help to better understand the strengths and limitations of the proposed approach.
Conclusion
This paper presents a novel clustering algorithm called Equilibrium K-means (EKM) that addresses the "uniform effect" issue in traditional K-means clustering, particularly on imbalanced datasets. By learning cluster centroids that are better aligned with the underlying data distribution, EKM is able to produce more accurate and meaningful clusters.
The authors also demonstrate how EKM can be seamlessly integrated into a deep learning-based clustering framework, expanding its applicability to large-scale datasets beyond the common ImageNet benchmark. This work represents an important step forward in the field of unsupervised learning, with potential impacts on a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Imbalanced Data Clustering using Equilibrium K-Means
Yudong He
Centroid-based clustering algorithms, such as hard K-means (HKM) and fuzzy K-means (FKM), have suffered from learning bias towards large clusters. Their centroids tend to be crowded in large clusters, compromising performance when the true underlying data groups vary in size (i.e., imbalanced data). To address this, we propose a new clustering objective function based on the Boltzmann operator, which introduces a novel centroid repulsion mechanism, where data points surrounding the centroids repel other centroids. Larger clusters repel more, effectively mitigating the issue of large cluster learning bias. The proposed new algorithm, called equilibrium K-means (EKM), is simple, alternating between two steps; resource-saving, with the same time and space complexity as FKM; and scalable to large datasets via batch learning. We substantially evaluate the performance of EKM on synthetic and real-world datasets. The results show that EKM performs competitively on balanced data and significantly outperforms benchmark algorithms on imbalanced data. Deep clustering experiments demonstrate that EKM is a better alternative to HKM and FKM on imbalanced data as more discriminative representation can be obtained. Additionally, we reformulate HKM, FKM, and EKM in a general form of gradient descent and demonstrate how this general form facilitates a uniform study of K-means algorithms.
Read more6/7/2024

0
Fuzzy K-Means Clustering without Cluster Centroids
Han Lu, Fangfang Li, Quanxue Gao, Cheng Deng, Chris Ding, Qianqian Wang
Fuzzy K-Means clustering is a critical technique in unsupervised data analysis. However, the performance of popular Fuzzy K-Means algorithms is sensitive to the selection of initial cluster centroids and is also affected by noise when updating mean cluster centroids. To address these challenges, this paper proposes a novel Fuzzy K-Means clustering algorithm that entirely eliminates the reliance on cluster centroids, obtaining membership matrices solely through distance matrix computation. This innovation enhances flexibility in distance measurement between sample points, thus improving the algorithm's performance and robustness. The paper also establishes theoretical connections between the proposed model and popular Fuzzy K-Means clustering techniques. Experimental results on several real datasets demonstrate the effectiveness of the algorithm.
Read more4/9/2024

0
Efficient k-means with Individual Fairness via Exponential Tilting
Shengkun Zhu, Jinshan Zeng, Yuan Sun, Sheng Wang, Xiaodong Li, Zhiyong Peng
In location-based resource allocation scenarios, the distances between each individual and the facility are desired to be approximately equal, thereby ensuring fairness. Individually fair clustering is often employed to achieve the principle of treating all points equally, which can be applied in these scenarios. This paper proposes a novel algorithm, tilted k-means (TKM), aiming to achieve individual fairness in clustering. We integrate the exponential tilting into the sum of squared errors (SSE) to formulate a novel objective function called tilted SSE. We demonstrate that the tilted SSE can generalize to SSE and employ the coordinate descent and first-order gradient method for optimization. We propose a novel fairness metric, the variance of the distances within each cluster, which can alleviate the Matthew Effect typically caused by existing fairness metrics. Our theoretical analysis demonstrates that the well-known k-means++ incurs a multiplicative error of O(k log k), and we establish the convergence of TKM under mild conditions. In terms of fairness, we prove that the variance generated by TKM decreases with a scaled hyperparameter. In terms of efficiency, we demonstrate the time complexity is linear with the dataset size. Our experiments demonstrate that TKM outperforms state-of-the-art methods in effectiveness, fairness, and efficiency.
Read more6/26/2024

0
A simulation study of cluster search algorithms in data set generated by Gaussian mixture models
Ryosuke Motegi, Yoichi Seki
Determining the number of clusters is a fundamental issue in data clustering. Several algorithms have been proposed, including centroid-based algorithms using the Euclidean distance and model-based algorithms using a mixture of probability distributions. Among these, greedy algorithms for searching the number of clusters by repeatedly splitting or merging clusters have advantages in terms of computation time for problems with large sample sizes. However, studies comparing these methods in systematic evaluation experiments still need to be included. This study examines centroid- and model-based cluster search algorithms in various cases that Gaussian mixture models (GMMs) can generate. The cases are generated by combining five factors: dimensionality, sample size, the number of clusters, cluster overlap, and covariance type. The results show that some cluster-splitting criteria based on Euclidean distance make unreasonable decisions when clusters overlap. The results also show that model-based algorithms are insensitive to covariance type and cluster overlap compared to the centroid-based method if the sample size is sufficient. Our cluster search implementation codes are available at https://github.com/lipryou/searchClustK
Read more7/30/2024