Fast and Effective Weight Update for Pruned Large Language Models

0
Sign in to get full access
Overview
- The paper presents a fast and optimal weight update algorithm for pruning large language models.
- The proposed method uses Alternating Direction Method of Multipliers (ADMM) to efficiently update the weights of a pruned model.
- This allows for faster training and optimization of pruned models compared to standard gradient descent approaches.
Plain English Explanation
Large language models are powerful AI systems that can perform a wide variety of natural language tasks. However, these models can be very large, requiring significant computational resources to train and run.
Pruning is a technique used to reduce the size of language models by removing unnecessary connections or weights. This can make the models more efficient and easier to deploy, but it also introduces challenges in terms of optimizing the remaining weights.
The researchers in this paper propose a new algorithm called ADMM (Alternating Direction Method of Multipliers) to quickly and optimally update the weights of a pruned language model. ADMM is a mathematical optimization technique that can efficiently solve the complex optimization problem that arises when updating the weights of a pruned model.
By using ADMM, the researchers were able to train pruned models faster and more effectively than traditional gradient descent methods. This could make it easier to deploy large language models in resource-constrained environments, such as on mobile devices or in the cloud.
Technical Explanation
The key idea behind the proposed method is to use ADMM to efficiently update the weights of a pruned language model. ADMM is an optimization algorithm that can solve complex problems by breaking them down into smaller, more manageable subproblems.
In the context of pruning, the researchers formulate the weight update problem as an ADMM optimization problem. This involves introducing auxiliary variables and constraints to separate the sparse weight update from the dense weight update. The ADMM algorithm then iteratively solves these subproblems, converging to the optimal weight update.
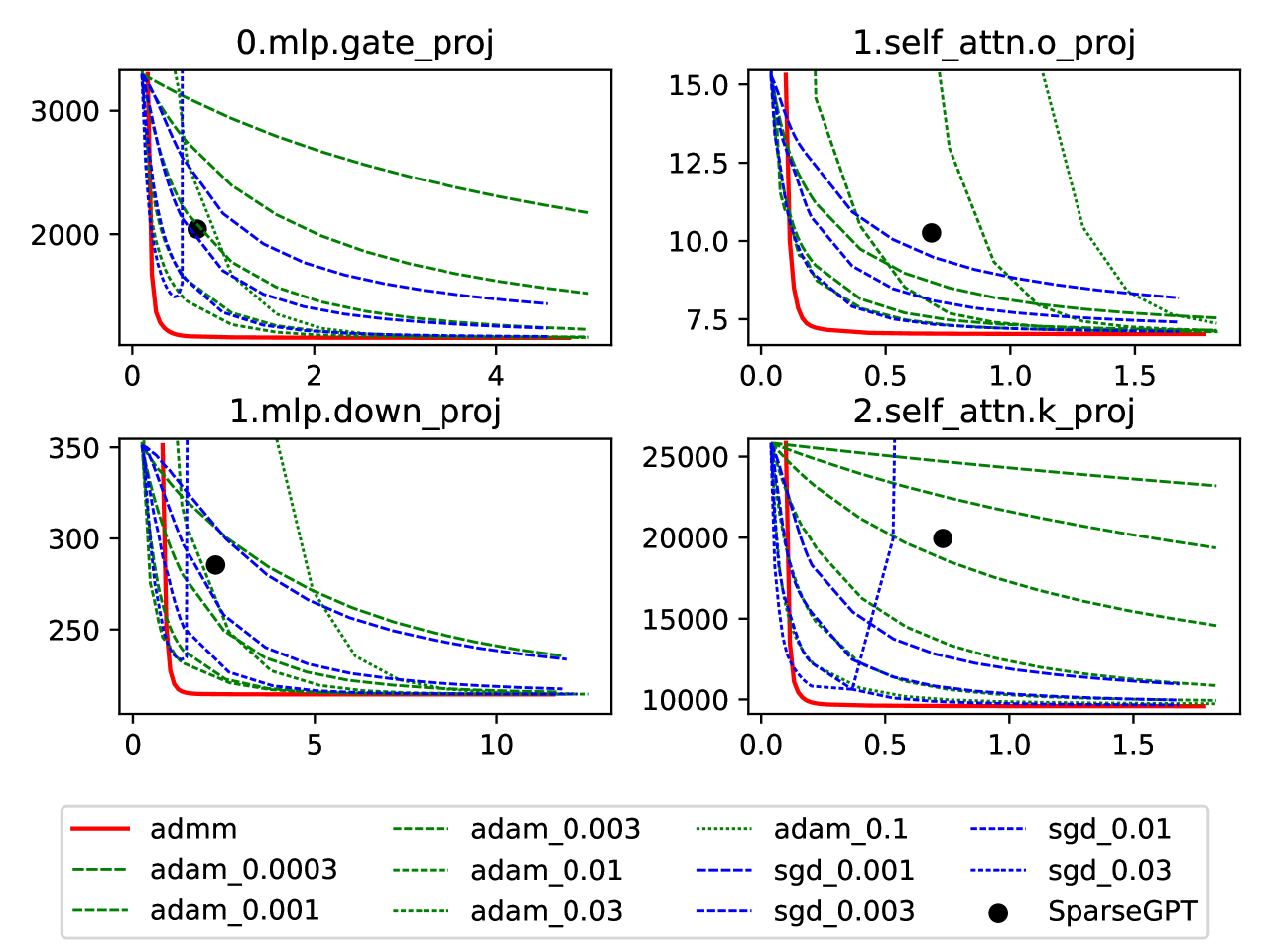
The researchers show that this ADMM-based weight update is both fast and optimal, outperforming standard gradient descent approaches in terms of convergence speed and final model performance. They evaluate their method on several large language models, including BERT and GPT-2, demonstrating its effectiveness across different model architectures and pruning levels.
Critical Analysis
One potential limitation of the proposed method is that it relies on the ADMM algorithm, which can be sensitive to the choice of hyperparameters. The researchers do not provide detailed guidance on how to tune these hyperparameters for optimal performance, which could make it challenging for practitioners to apply the method in practice.
Additionally, the paper does not explore the generalization of the ADMM-based weight update to other types of neural network architectures beyond language models. It would be interesting to see if the method could be extended to other domains, such as computer vision or speech recognition.
Despite these minor limitations, the proposed ADMM-based weight update algorithm is a promising approach for efficient optimization of pruned large language models. The ability to quickly and optimally update the weights of a pruned model could have significant implications for the deployment of these powerful AI systems in resource-constrained environments.
Conclusion
This paper presents a novel algorithm for efficiently updating the weights of pruned large language models. By using the ADMM optimization technique, the researchers were able to develop a fast and optimal weight update method that outperforms standard gradient descent approaches.
The ability to rapidly and effectively optimize pruned language models could make it easier to deploy these powerful AI systems in a wide range of real-world applications, from mobile devices to cloud-based services. As the demand for large language models continues to grow, the techniques described in this paper may prove invaluable for enabling their efficient and widespread use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fast and Effective Weight Update for Pruned Large Language Models
Vladim'ir Bov{z}a
Pruning large language models (LLMs) is a challenging task due to their enormous size. The primary difficulty is fine-tuning the model after pruning, which is needed to recover the lost performance caused by dropping weights. Recent approaches have either ignored fine-tuning entirely, focusing on efficient pruning criteria, or attempted layer-wise weight updates, preserving the behavior of each layer. However, even layer-wise weight updates can be costly for LLMs, and previous works have resorted to various approximations. In our paper, we propose a fast and effective weight update algorithm for pruned layers based on the Alternating Direction Method of Multipliers (ADMM). We further extend it with a simple gradual pruning mask selection and achieve state-of-the-art pruning performance across a wide range of LLMs. Code is available at https://github.com/fmfi-compbio/admm-pruning.
Read more7/23/2024
1
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, J. Zico Kolter
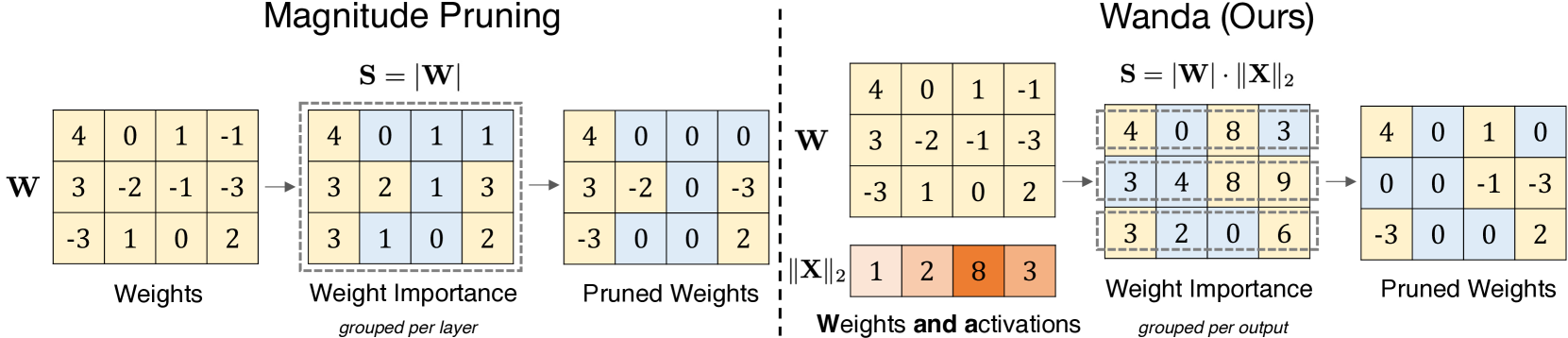
As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance. Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive. In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prunes weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method Wanda on LLaMA and LLaMA-2 across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and performs competitively against recent method involving intensive weight update. Code is available at https://github.com/locuslab/wanda.
Read more5/7/2024

0
Optimization-based Structural Pruning for Large Language Models without Back-Propagation
Yuan Gao, Zujing Liu, Weizhong Zhang, Bo Du, Gui-Song Xia
Compared to the moderate size of neural network models, structural weight pruning on the Large-Language Models (LLMs) imposes a novel challenge on the efficiency of the pruning algorithms, due to the heavy computation/memory demands of the LLMs. Recent efficient LLM pruning methods typically operate at the post-training phase without the expensive weight finetuning, however, their pruning criteria often rely on heuristically designed metrics, potentially leading to suboptimal performance. We instead propose a novel optimization-based structural pruning that learns the pruning masks in a probabilistic space directly by optimizing the loss of the pruned model. To preserve the efficiency, our method 1) works at post-training phase} and 2) eliminates the back-propagation through the LLM per se during the optimization (i.e., only requires the forward pass of the LLM). We achieve this by learning an underlying Bernoulli distribution to sample binary pruning masks, where we decouple the Bernoulli parameters from the LLM loss, thus facilitating an efficient optimization via a policy gradient estimator without back-propagation. As a result, our method is able to 1) operate at structural granularities of channels, heads, and layers, 2) support global and heterogeneous pruning (i.e., our method automatically determines different redundancy for different layers), and 3) optionally use a metric-based method as initialization (of our Bernoulli distributions). Extensive experiments on LLaMA, LLaMA-2, and Vicuna using the C4 and WikiText2 datasets demonstrate that our method operates for 2.7 hours with around 35GB memory for the 13B models on a single A100 GPU, and our pruned models outperform the state-of-the-arts w.r.t. perplexity. Codes will be released.
Read more6/18/2024
0
MoreauPruner: Robust Pruning of Large Language Models against Weight Perturbations
Zixiao Wang, Jingwei Zhang, Wenqian Zhao, Farzan Farnia, Bei Yu
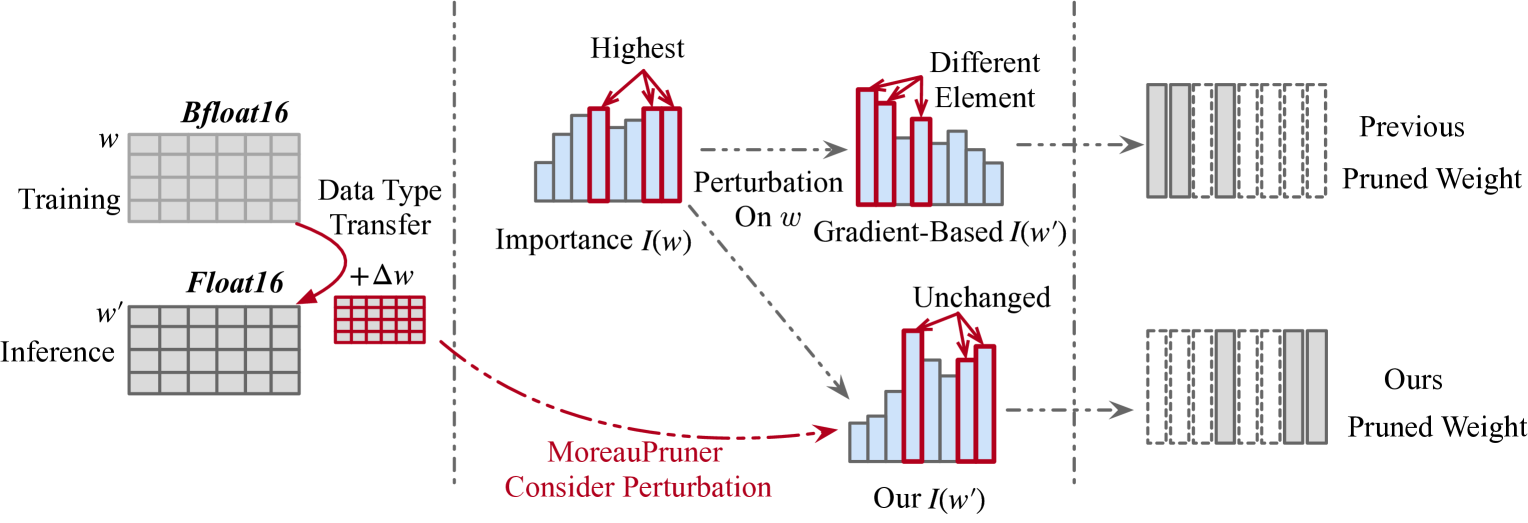
Few-shot gradient methods have been extensively utilized in existing model pruning methods, where the model weights are regarded as static values and the effects of potential weight perturbations are not considered. However, the widely used large language models (LLMs) have several billion model parameters, which could increase the fragility of few-shot gradient pruning. In this work, we experimentally show that one-shot gradient pruning algorithms could lead to unstable results under perturbations to model weights. And the minor error of switching between data formats bfloat16 and float16 could result in drastically different outcomes. To address such instabilities, we leverage optimization analysis and propose an LLM structural pruning method, called MoreauPruner, with provable robustness against weight perturbations. In MoreauPruner, the model weight importance is estimated based on the neural network's Moreau envelope, which can be flexibly combined with $ell_1$-norm regularization techniques to induce the sparsity required in the pruning task. We extensively evaluate the MoreauPruner algorithm on several well-known LLMs, including LLaMA-7B, LLaMA-13B, LLaMA3-8B, and Vicuna-7B. Our numerical results suggest the robustness of MoreauPruner against weight perturbations, and indicate the MoreauPruner's successful accuracy-based scores in comparison to several existing pruning methods. We have released the code in url{https://github.com/ShiningSord/MoreauPruner}.
Read more6/12/2024