A Fast Maximum Clique Algorithm Based on Network Decomposition for Large Sparse Networks
2404.11862
0
0
🔍
Abstract
Finding maximum cliques in large networks is a challenging combinatorial problem with many real-world applications. We present a fast algorithm to achieve the exact solution for the maximum clique problem in large sparse networks based on efficient graph decomposition. A bunch of effective techniques is being used to greatly prune the graph and a novel concept called Complete-Upper-Bound-Induced Subgraph (CUBIS) is proposed to ensure that the structures with the potential to form the maximum clique are retained in the process of graph decomposition. Our algorithm first pre-prunes peripheral nodes, subsequently, one or two small-scale CUBISs are constructed guided by the core number and current maximum clique size. Bron-Kerbosch search is performed on each CUBIS to find the maximum clique. Experiments on 50 empirical networks with a scale of up to 20 million show the CUBIS scales are largely independent of the original network scale. This enables an approximately linear runtime, making our algorithm amenable for large networks. Our work provides a new framework for effectively solving maximum clique problems on massive sparse graphs, which not only makes the graph scale no longer the bottleneck but also shows some light on solving other clique-related problems.
Create account to get full access
Overview
- Solving the maximum clique problem, which is finding the largest fully connected subgraph in a network, is a challenging but important task with many real-world applications.
- The paper presents a fast algorithm to find the exact solution to the maximum clique problem in large, sparse networks.
- The algorithm uses efficient graph decomposition techniques to greatly prune the search space and a novel concept called the Complete-Upper-Bound-Induced Subgraph (CUBIS) to ensure relevant structures are retained.
- Experiments on large networks with up to 20 million nodes show the algorithm scales largely independently of the original network size, enabling a near-linear runtime.
Plain English Explanation
The paper tackles the problem of finding the largest fully connected subgraph within a large network. This is known as the maximum clique problem, and it has many practical applications, such as in social network analysis, drug discovery, and image segmentation.
The researchers have developed a new algorithm that can efficiently solve this problem, even for very large and sparse networks. The key ideas are:
- Pruning the search space: The algorithm first removes peripheral nodes that are unlikely to be part of the maximum clique, greatly reducing the number of possibilities that need to be checked.
- Constructing CUBIS subgraphs: The algorithm then identifies one or two small, dense subgraphs (called CUBIS) that are likely to contain the maximum clique. This allows the search to be focused on these promising areas rather than the entire network.
- Bron-Kerbosch search: The algorithm then performs a targeted search within each CUBIS subgraph to find the maximum clique, using an efficient algorithm called Bron-Kerbosch.
The key advantage of this approach is that it allows the algorithm to scale to very large networks without the network size becoming a bottleneck. The experiments show the algorithm can handle networks with up to 20 million nodes, with a runtime that increases roughly linearly with the network size.
This work provides a new framework for efficiently solving the maximum clique problem on massive, sparse graphs, which has important implications for a variety of real-world applications that rely on finding dense substructures in large networks.
Technical Explanation
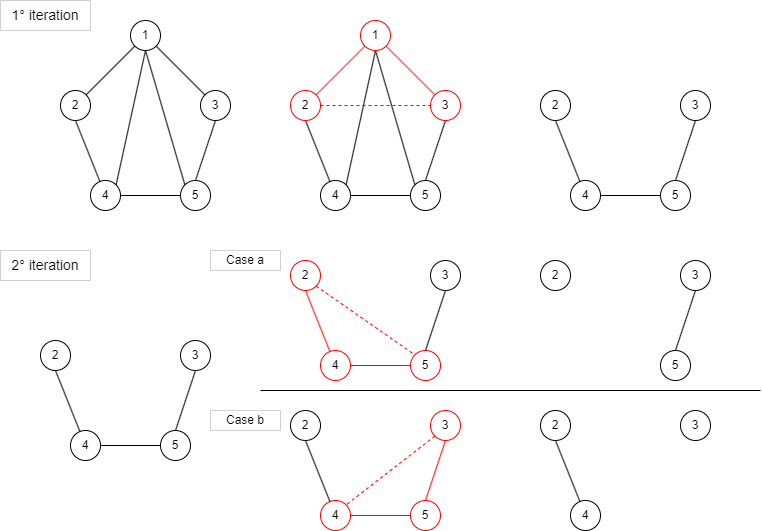
The proposed algorithm first pre-prunes the network by removing peripheral nodes that are unlikely to be part of the maximum clique. This is guided by the nodes' core numbers, which quantify how well-connected they are to their neighbors.
Next, the algorithm constructs one or two Complete-Upper-Bound-Induced Subgraphs (CUBIS) - dense subgraphs that are likely to contain the maximum clique. The CUBIS are identified by starting from the nodes with the highest core numbers and iteratively adding their well-connected neighbors.
The Bron-Kerbosch algorithm is then applied to each CUBIS to find the maximum clique within that subgraph. Bron-Kerbosch is an efficient backtracking algorithm specifically designed for the maximum clique problem.
The key innovation is the CUBIS concept, which ensures the structures with the potential to form the maximum clique are retained during the graph decomposition process. This allows the algorithm to scale largely independently of the original network size, as the CUBIS tend to be much smaller than the full network.
Experiments on 50 real-world networks ranging from thousands to tens of millions of nodes show the algorithm achieves a near-linear runtime, making it suitable for solving the maximum clique problem on very large, sparse networks.
Critical Analysis
The paper provides a thorough evaluation of the proposed algorithm, including comparisons to state-of-the-art methods and an analysis of the algorithm's runtime complexity. However, there are a few potential limitations and areas for further research:
-
Handling dense networks: The algorithm is designed for sparse networks, and its performance on denser networks is not discussed. Adapting the CUBIS construction process to work well with dense graphs could further broaden the algorithm's applicability.
-
Parallelization: While the algorithm already achieves near-linear runtime, further speedups could potentially be achieved by parallelizing the CUBIS construction and Bron-Kerbosch search steps, taking advantage of modern multi-core hardware.
-
Approximation algorithms: The proposed algorithm finds the exact maximum clique. Developing an approximation algorithm that can provide guaranteed bounds on the solution quality could be a fruitful area for future research, potentially leading to even faster runtimes.
Overall, the paper presents a novel and highly effective approach to solving the maximum clique problem on large, sparse networks, with promising implications for a variety of real-world applications. The critical analysis suggests several avenues for further improvement and exploration.
Conclusion
This paper introduces a fast algorithm for finding the maximum clique in large, sparse networks. By efficiently pruning the search space and constructing targeted CUBIS subgraphs, the algorithm is able to scale largely independently of the original network size, enabling it to handle networks with up to 20 million nodes.
The key innovations are the pre-pruning of peripheral nodes, the CUBIS concept for retaining relevant substructures, and the use of the Bron-Kerbosch algorithm for the final clique search. Experimental results demonstrate the algorithm's ability to solve the maximum clique problem in near-linear time, making it a valuable tool for a wide range of applications that rely on finding dense subgraphs in large networks.
While the algorithm is primarily designed for sparse networks, the critical analysis suggests potential directions for further research, such as adapting the approach to handle denser graphs, exploring parallelization strategies, and developing approximation algorithms. Overall, this work provides a significant advancement in the field of maximum clique detection, with the potential to unlock new applications and insights from large-scale network data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient Enumeration of Large Maximal k-Plexes
Qihao Cheng, Da Yan, Tianhao Wu, Lyuheng Yuan, Ji Cheng, Zhongyi Huang, Yang Zhou
0
0
Finding cohesive subgraphs in a large graph has many important applications, such as community detection and biological network analysis. Clique is often a too strict cohesive structure since communities or biological modules rarely form as cliques for various reasons such as data noise. Therefore, $k$-plex is introduced as a popular clique relaxation, which is a graph where every vertex is adjacent to all but at most $k$ vertices. In this paper, we propose a fast branch-and-bound algorithm as well as its task-based parallel version to enumerate all maximal $k$-plexes with at least $q$ vertices. Our algorithm adopts an effective search space partitioning approach that provides a lower time complexity, a new pivot vertex selection method that reduces candidate vertex size, an effective upper-bounding technique to prune useless branches, and three novel pruning techniques by vertex pairs. Our parallel algorithm uses a timeout mechanism to eliminate straggler tasks, and maximizes cache locality while ensuring load balancing. Extensive experiments show that compared with the state-of-the-art algorithms, our sequential and parallel algorithms enumerate large maximal $k$-plexes with up to $5 times$ and $18.9 times$ speedup, respectively. Ablation results also demonstrate that our pruning techniques bring up to $7 times$ speedup compared with our basic algorithm.
6/11/2024
An Analysis of Quantum Annealing Algorithms for Solving the Maximum Clique Problem
Alessandro Gherardi, Alberto Leporati
0
0
Quantum annealers can be used to solve many (possibly NP-hard) combinatorial optimization problems, by formulating them as quadratic unconstrained binary optimization (QUBO) problems or, equivalently, using the Ising formulation. In this paper we analyse the ability of quantum D-Wave annealers to find the maximum clique on a graph, expressed as a QUBO problem. Due to the embedding limit of 164 nodes imposed by the anneler, we conducted a study on graph decomposition to enable instance embedding. We thus propose a decomposition algorithm for the complementary maximum independent set problem, and a graph generation algorithm to control the number of nodes, the number of cliques, the density, the connectivity indices and the ratio of the solution size to the number of other nodes. We then statistically analysed how these variables affect the quality of the solutions found by the quantum annealer. The results of our investigation include recommendations on ratio and density limits not to be exceeded, as well as a series of precautions and a priori analyses to be carried out in order to maximise the probability of obtaining a solution close to the optimum.
6/13/2024

BBK: a simpler, faster algorithm for enumerating maximal bicliques in large sparse bipartite graphs
Alexis Baudin, Cl'emence Magnien, Lionel Tabourier
0
0
Bipartite graphs are a prevalent modeling tool for real-world networks, capturing interactions between vertices of two different types. Within this framework, bicliques emerge as crucial structures when studying dense subgraphs: they are sets of vertices such that all vertices of the first type interact with all vertices of the second type. Therefore, they allow identifying groups of closely related vertices of the network, such as individuals with similar interests or webpages with similar contents. This article introduces a new algorithm designed for the exhaustive enumeration of maximal bicliques within a bipartite graph. This algorithm, called BBK for Bipartite Bron-Kerbosch, is a new extension to the bipartite case of the Bron-Kerbosch algorithm, which enumerates the maximal cliques in standard (non-bipartite) graphs. It is faster than the state-of-the-art algorithms and allows the enumeration on massive bipartite graphs that are not manageable with existing implementations. We analyze it theoretically to establish two complexity formulas: one as a function of the input and one as a function of the output characteristics of the algorithm. We also provide an open-access implementation of BBK in C++, which we use to experiment and validate its efficiency on massive real-world datasets and show that its execution time is shorter in practice than state-of-the art algorithms. These experiments also show that the order in which the vertices are processed, as well as the choice of one of the two types of vertices on which to initiate the enumeration have an impact on the computation time.
5/27/2024
📉
Faster maximal clique enumeration in large real-world link streams
Alexis Baudin, Cl'emence Magnien, Lionel Tabourier
0
0
Link streams offer a good model for representing interactions over time. They consist of links $(b,e,u,v)$, where $u$ and $v$ are vertices interacting during the whole time interval $[b,e]$. In this paper, we deal with the problem of enumerating maximal cliques in link streams. A clique is a pair $(C,[t_0,t_1])$, where $C$ is a set of vertices that all interact pairwise during the full interval $[t_0,t_1]$. It is maximal when neither its set of vertices nor its time interval can be increased. Some of the main works solving this problem are based on the famous Bron-Kerbosch algorithm for enumerating maximal cliques in graphs. We take this idea as a starting point to propose a new algorithm which matches the cliques of the instantaneous graphs formed by links existing at a given time $t$ to the maximal cliques of the link stream. We prove its validity and compute its complexity, which is better than the state-of-the art ones in many cases of interest. We also study the output-sensitive complexity, which is close to the output size, thereby showing that our algorithm is efficient. To confirm this, we perform experiments on link streams used in the state of the art, and on massive link streams, up to 100 million links. In all cases our algorithm is faster, mostly by a factor of at least 10 and up to a factor of $10^4$. Moreover, it scales to massive link streams for which the existing algorithms are not able to provide the solution.
5/27/2024