A Clustering Method with Graph Maximum Decoding Information

0

Sign in to get full access
Overview
- This paper proposes a new clustering method that uses graph maximum decoding information to extract structural information from data.
- The method aims to improve on traditional clustering techniques by leveraging the inherent structure and patterns within the data.
- The authors demonstrate the effectiveness of their approach through experiments on several datasets and compare it to other state-of-the-art clustering algorithms.
Plain English Explanation
The paper introduces a new way to group and organize data points into clusters. Traditional clustering methods often rely on simplistic measures like distance between data points. However, real-world data often has complex, underlying structures that these methods fail to capture.
The key insight of this paper is that by analyzing the maximum decoding information within the data, we can uncover more meaningful groupings. The method works by partitioning the data into a graph and then using the maximum amount of information that can be extracted from that graph structure to determine the cluster assignments.
This approach is advantageous because it allows the algorithm to discover clusters that align with the natural structural patterns in the data, rather than just relying on proximity. The authors show that this leads to improved clustering performance compared to traditional methods, especially on complex, real-world datasets.
Technical Explanation
The core idea of the proposed method is to leverage the structural information inherent in the data to guide the clustering process. The authors first construct a graph representation of the data, where each node corresponds to a data point and the edges encode the similarities between them.
They then define a measure called "decoding information" that quantifies the amount of information that can be extracted from the graph structure. The key step is to find the graph partitioning that maximizes this decoding information, as this is assumed to correspond to the optimal clustering of the data.
The authors develop an efficient algorithm to solve this graph partitioning problem, using techniques from spectral graph theory and network decomposition. Through extensive experiments on both synthetic and real-world datasets, they demonstrate that their method outperforms several state-of-the-art clustering algorithms in terms of clustering quality and runtime.
Critical Analysis
The proposed method is a promising approach to clustering that effectively leverages the structural information in data. By focusing on maximizing the decoding information, the algorithm is able to uncover clusters that align with the natural patterns and relationships in the data, rather than just relying on proximity.
However, the paper does not provide much insight into the limitations or potential drawbacks of the approach. For example, it is unclear how the method would scale to extremely large datasets or how robust it is to noise or outliers in the data. Additionally, the paper could have benefited from a more in-depth discussion of the theoretical foundations and properties of the decoding information measure.
Further research could also explore ways to integrate this structural information-based clustering with other techniques, such as reinforcement learning or disentangled representation learning, to potentially unlock even more powerful clustering capabilities.
Conclusion
This paper presents a novel clustering method that leverages the structural information within data to uncover more meaningful and robust groupings of data points. By focusing on maximizing the decoding information extracted from the data's graph representation, the algorithm is able to outperform traditional clustering techniques, especially on complex, real-world datasets.
While the paper leaves some open questions, the core idea of using structural information to guide the clustering process is a promising direction for future research. As data continues to grow in volume and complexity, techniques that can effectively capture the underlying patterns and relationships will become increasingly valuable for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Clustering Method with Graph Maximum Decoding Information
Xinrun Xu, Manying Lv, Zhanbiao Lian, Yurong Wu, Jin Yan, Shan Jiang, Zhiming Ding
The clustering method based on graph models has garnered increased attention for its widespread applicability across various knowledge domains. Its adaptability to integrate seamlessly with other relevant applications endows the graph model-based clustering analysis with the ability to robustly extract natural associations or graph structures within datasets, facilitating the modelling of relationships between data points. Despite its efficacy, the current clustering method utilizing the graph-based model overlooks the uncertainty associated with random walk access between nodes and the embedded structural information in the data. To address this gap, we present a novel Clustering method for Maximizing Decoding Information within graph-based models, named CMDI. CMDI innovatively incorporates two-dimensional structural information theory into the clustering process, consisting of two phases: graph structure extraction and graph vertex partitioning. Within CMDI, graph partitioning is reformulated as an abstract clustering problem, leveraging maximum decoding information to minimize uncertainty associated with random visits to vertices. Empirical evaluations on three real-world datasets demonstrate that CMDI outperforms classical baseline methods, exhibiting a superior decoding information ratio (DI-R). Furthermore, CMDI showcases heightened efficiency, particularly when considering prior knowledge (PK). These findings underscore the effectiveness of CMDI in enhancing decoding information quality and computational efficiency, positioning it as a valuable tool in graph-based clustering analyses.
Read more4/19/2024

0
Graph-Structured Speculative Decoding
Zhuocheng Gong, Jiahao Liu, Ziyue Wang, Pengfei Wu, Jingang Wang, Xunliang Cai, Dongyan Zhao, Rui Yan
Speculative decoding has emerged as a promising technique to accelerate the inference of Large Language Models (LLMs) by employing a small language model to draft a hypothesis sequence, which is then validated by the LLM. The effectiveness of this approach heavily relies on the balance between performance and efficiency of the draft model. In our research, we focus on enhancing the proportion of draft tokens that are accepted to the final output by generating multiple hypotheses instead of just one. This allows the LLM more options to choose from and select the longest sequence that meets its standards. Our analysis reveals that hypotheses produced by the draft model share many common token sequences, suggesting a potential for optimizing computation. Leveraging this observation, we introduce an innovative approach utilizing a directed acyclic graph (DAG) to manage the drafted hypotheses. This structure enables us to efficiently predict and merge recurring token sequences, vastly reducing the computational demands of the draft model. We term this approach Graph-structured Speculative Decoding (GSD). We apply GSD across a range of LLMs, including a 70-billion parameter LLaMA-2 model, and observe a remarkable speedup of 1.73$times$ to 1.96$times$, significantly surpassing standard speculative decoding.
Read more7/24/2024
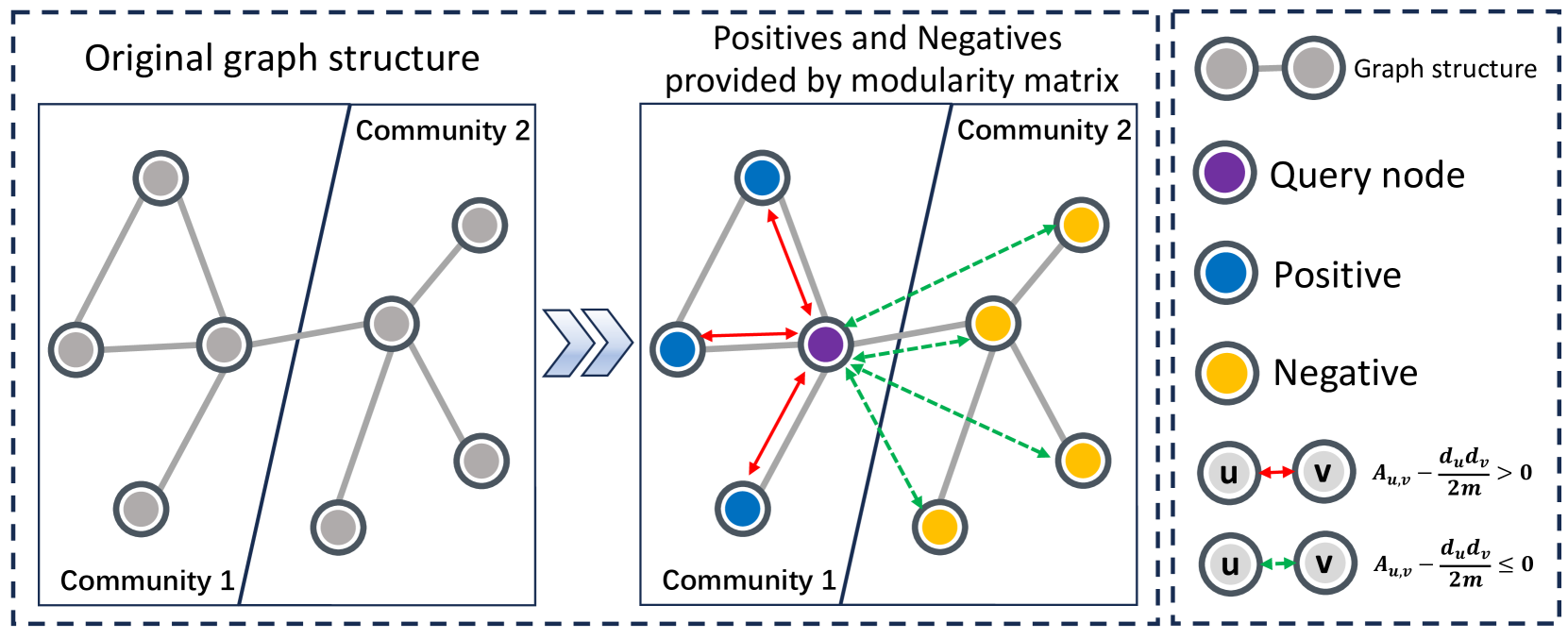
0
Revisiting Modularity Maximization for Graph Clustering: A Contrastive Learning Perspective
Yunfei Liu, Jintang Li, Yuehe Chen, Ruofan Wu, Ericbk Wang, Jing Zhou, Sheng Tian, Shuheng Shen, Xing Fu, Changhua Meng, Weiqiang Wang, Liang Chen
Graph clustering, a fundamental and challenging task in graph mining, aims to classify nodes in a graph into several disjoint clusters. In recent years, graph contrastive learning (GCL) has emerged as a dominant line of research in graph clustering and advances the new state-of-the-art. However, GCL-based methods heavily rely on graph augmentations and contrastive schemes, which may potentially introduce challenges such as semantic drift and scalability issues. Another promising line of research involves the adoption of modularity maximization, a popular and effective measure for community detection, as the guiding principle for clustering tasks. Despite the recent progress, the underlying mechanism of modularity maximization is still not well understood. In this work, we dig into the hidden success of modularity maximization for graph clustering. Our analysis reveals the strong connections between modularity maximization and graph contrastive learning, where positive and negative examples are naturally defined by modularity. In light of our results, we propose a community-aware graph clustering framework, coined MAGI, which leverages modularity maximization as a contrastive pretext task to effectively uncover the underlying information of communities in graphs, while avoiding the problem of semantic drift. Extensive experiments on multiple graph datasets verify the effectiveness of MAGI in terms of scalability and clustering performance compared to state-of-the-art graph clustering methods. Notably, MAGI easily scales a sufficiently large graph with 100M nodes while outperforming strong baselines.
Read more6/21/2024

0
Modularity aided consistent attributed graph clustering via coarsening
Samarth Bhatia (Indian Institute of Technology, Delhi), Yukti Makhija (Indian Institute of Technology, Delhi), Manoj Kumar (Indian Institute of Technology, Delhi), Sandeep Kumar (Indian Institute of Technology, Delhi)
Graph clustering is an important unsupervised learning technique for partitioning graphs with attributes and detecting communities. However, current methods struggle to accurately capture true community structures and intra-cluster relations, be computationally efficient, and identify smaller communities. We address these challenges by integrating coarsening and modularity maximization, effectively leveraging both adjacency and node features to enhance clustering accuracy. We propose a loss function incorporating log-determinant, smoothness, and modularity components using a block majorization-minimization technique, resulting in superior clustering outcomes. The method is theoretically consistent under the Degree-Corrected Stochastic Block Model (DC-SBM), ensuring asymptotic error-free performance and complete label recovery. Our provably convergent and time-efficient algorithm seamlessly integrates with graph neural networks (GNNs) and variational graph autoencoders (VGAEs) to learn enhanced node features and deliver exceptional clustering performance. Extensive experiments on benchmark datasets demonstrate its superiority over existing state-of-the-art methods for both attributed and non-attributed graphs.
Read more7/11/2024