Fast Switching Serial and Parallel Paradigms of SNN Inference on Multi-core Heterogeneous Neuromorphic Platform SpiNNaker2

0

Sign in to get full access
Overview
- This paper presents a fast switching approach for running spiking neural network (SNN) inference on the SpiNNaker2 multi-core heterogeneous neuromorphic platform.
- The researchers demonstrate the ability to dynamically switch between serial and parallel processing paradigms to optimize performance for different SNN workloads.
- The work aims to enable efficient deployment of hybrid SNN models on neuromorphic hardware for edge computing applications.
Plain English Explanation
Spiking neural networks (SNNs) are a type of machine learning model that more closely mimic the way the human brain processes information, using short electrical pulses or "spikes" to transmit data. These SNN models can be highly efficient for certain types of computing tasks, especially at the edge or in low-power devices.
The paper describes a new system that can run SNN inference (the process of using a trained SNN model to make predictions) on a specialized neuromorphic hardware platform called SpiNNaker2. The key innovation is the ability to quickly switch between two different ways of processing the SNN workload - a serial (one-at-a-time) approach and a parallel (multiple-at-once) approach.
This flexible switching ability allows the system to adapt and optimize its performance depending on the specific SNN model and the computing resources available. For some models, the serial approach may be more efficient, while for others the parallel approach works better. By dynamically choosing the best method, the system can run SNN inference much more effectively on the SpiNNaker2 hardware.
This advance helps enable the efficient deployment of hybrid SNN models on neuromorphic edge devices, opening up new possibilities for using these energy-efficient AI models in real-world applications.
Technical Explanation
The researchers developed a "neuromorphic compiler" that can partition SNN workloads between the serial and parallel processing paradigms supported by the heterogeneous SpiNNaker2 platform. The serial approach runs neurons sequentially, while the parallel approach distributes neuron computations across multiple cores.
A key component is an algorithm that dynamically selects the optimal processing paradigm based on factors like the SNN model structure, available hardware resources, and performance requirements. This allows the system to switch between serial and parallel modes at runtime to achieve the best overall inference throughput and efficiency.
The paper presents detailed evaluations of this fast switching approach on various SNN benchmarks, demonstrating up to 2.8x speedup compared to a pure serial or parallel execution. The results show the importance of being able to flexibly adapt the processing paradigm to match the characteristics of different SNN models.
This work builds on prior research on parallel SNN inference, FPGA-based SNN acceleration, and neuromorphic hardware for low-power AI, helping to advance the state-of-the-art in deploying SNNs on specialized neuromorphic platforms.
Critical Analysis
The paper provides a compelling demonstration of the potential benefits of a flexible, hybrid processing approach for SNN inference on neuromorphic hardware. The ability to dynamically switch between serial and parallel modes is a clever solution to the challenge of optimizing performance across diverse SNN workloads.
That said, the evaluation is limited to a set of benchmark models and the SpiNNaker2 platform specifically. It would be interesting to see how well this approach generalizes to other neuromorphic architectures and a wider range of real-world SNN applications.
Additionally, the paper does not provide much insight into the decision-making heuristics used by the compiler to select the optimal processing mode. More detail on this mechanism and its robustness would help readers better understand the system's capabilities and limitations.
Overall, this research represents an important step towards the efficient deployment of hybrid SNNs on neuromorphic edge devices. Further work is needed to fully realize the potential of this fast switching approach and enable widespread adoption of energy-efficient SNN models in real-world applications.
Conclusion
This paper introduces a novel technique for running spiking neural network (SNN) inference on the multi-core SpiNNaker2 neuromorphic platform. By dynamically switching between serial and parallel processing paradigms, the system can optimize performance for different SNN workloads.
The demonstrated speed-ups over fixed serial or parallel approaches highlight the benefits of this flexible, hybrid architecture. This work represents an important advancement in enabling the efficient deployment of SNNs on neuromorphic hardware, paving the way for more energy-efficient AI at the edge.
As neuromorphic computing continues to mature, innovations like the one described in this paper will be crucial for unlocking the full potential of spiking neural networks in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fast Switching Serial and Parallel Paradigms of SNN Inference on Multi-core Heterogeneous Neuromorphic Platform SpiNNaker2
Jiaxin Huang, Bernhard Vogginger, Florian Kelber, Hector Gonzalez, Klaus Knobloch, Christian Georg Mayr
With serial and parallel processors introduced into Spiking Neural Networks (SNNs) execution, more and more researchers are dedicated to improving the performance of the computing paradigms by taking full advantage of the strengths of the available processor. In this paper, we compare and integrate serial and parallel paradigms into one SNN compiling system. For a faster switching between them in the layer granularity, we train the classifier to prejudge a better paradigm before compiling instead of making the decision afterward, saving a great amount of compiling time and RAM space on the host PC. The classifier Adaptive Boost, with the highest accuracy (91.69%) among 12 classifiers, is integrated into the switching system, which utilizes less memory and processors on the multi-core neuromorphic hardware backend SpiNNaker2 than two individual paradigms. To the best of our knowledge, it is the first fast-switching compiling system for SNN simulation.
Read more7/15/2024

0
An Asynchronous Multi-core Accelerator for SNN inference
Zhuo Chen, De Ma, Xiaofei Jin, Qinghui Xing, Ouwen Jin, Xin Du, Shuibing He, Gang Pan
Spiking Neural Networks (SNNs) are extensively utilized in brain-inspired computing and neuroscience research. To enhance the speed and energy efficiency of SNNs, several many-core accelerators have been developed. However, maintaining the accuracy of SNNs often necessitates frequent explicit synchronization among all cores, which presents a challenge to overall efficiency. In this paper, we propose an asynchronous architecture for Spiking Neural Networks (SNNs) that eliminates the need for inter-core synchronization, thus enhancing speed and energy efficiency. This approach leverages the pre-determined dependencies of neuromorphic cores established during compilation. Each core is equipped with a scheduler that monitors the status of its dependencies, allowing it to safely advance to the next timestep without waiting for other cores. This eliminates the necessity for global synchronization and minimizes core waiting time despite inherent workload imbalances. Comprehensive evaluations using five different SNN workloads show that our architecture achieves a 1.86x speedup and a 1.55x increase in energy efficiency compared to state-of-the-art synchronization architectures.
Read more7/31/2024

0
Towards Efficient Deployment of Hybrid SNNs on Neuromorphic and Edge AI Hardware
James Seekings, Peyton Chandarana, Mahsa Ardakani, MohammadReza Mohammadi, Ramtin Zand
This paper explores the synergistic potential of neuromorphic and edge computing to create a versatile machine learning (ML) system tailored for processing data captured by dynamic vision sensors. We construct and train hybrid models, blending spiking neural networks (SNNs) and artificial neural networks (ANNs) using PyTorch and Lava frameworks. Our hybrid architecture integrates an SNN for temporal feature extraction and an ANN for classification. We delve into the challenges of deploying such hybrid structures on hardware. Specifically, we deploy individual components on Intel's Neuromorphic Processor Loihi (for SNN) and Jetson Nano (for ANN). We also propose an accumulator circuit to transfer data from the spiking to the non-spiking domain. Furthermore, we conduct comprehensive performance analyses of hybrid SNN-ANN models on a heterogeneous system of neuromorphic and edge AI hardware, evaluating accuracy, latency, power, and energy consumption. Our findings demonstrate that the hybrid spiking networks surpass the baseline ANN model across all metrics and outperform the baseline SNN model in accuracy and latency.
Read more7/12/2024
0
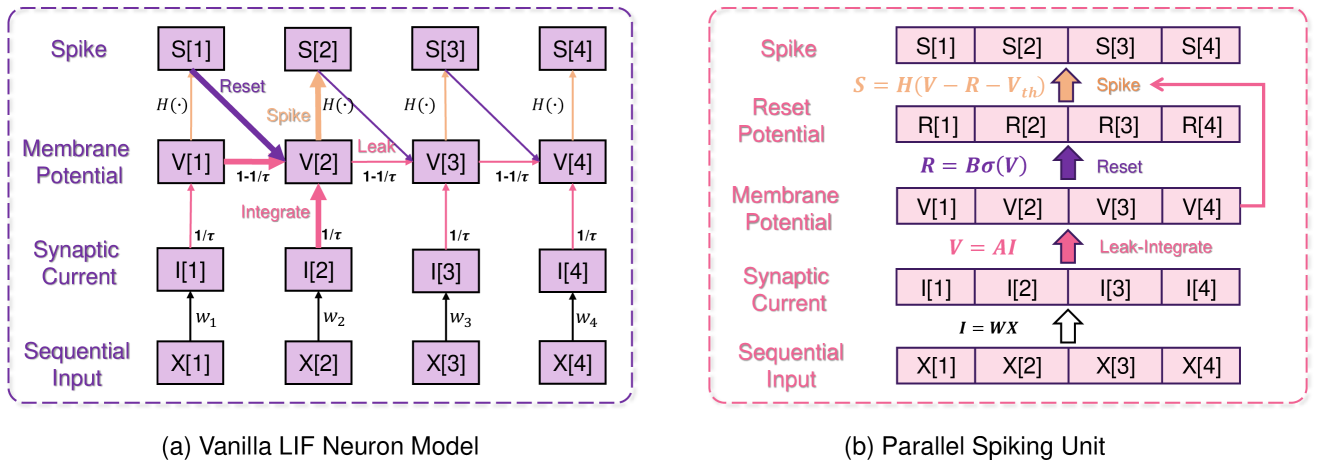
Parallel Spiking Unit for Efficient Training of Spiking Neural Networks
Yang Li, Yinqian Sun, Xiang He, Yiting Dong, Dongcheng Zhao, Yi Zeng
Efficient parallel computing has become a pivotal element in advancing artificial intelligence. Yet, the deployment of Spiking Neural Networks (SNNs) in this domain is hampered by their inherent sequential computational dependency. This constraint arises from the need for each time step's processing to rely on the preceding step's outcomes, significantly impeding the adaptability of SNN models to massively parallel computing environments. Addressing this challenge, our paper introduces the innovative Parallel Spiking Unit (PSU) and its two derivatives, the Input-aware PSU (IPSU) and Reset-aware PSU (RPSU). These variants skillfully decouple the leaky integration and firing mechanisms in spiking neurons while probabilistically managing the reset process. By preserving the fundamental computational attributes of the spiking neuron model, our approach enables the concurrent computation of all membrane potential instances within the SNN, facilitating parallel spike output generation and substantially enhancing computational efficiency. Comprehensive testing across various datasets, including static and sequential images, Dynamic Vision Sensor (DVS) data, and speech datasets, demonstrates that the PSU and its variants not only significantly boost performance and simulation speed but also augment the energy efficiency of SNNs through enhanced sparsity in neural activity. These advancements underscore the potential of our method in revolutionizing SNN deployment for high-performance parallel computing applications.
Read more6/11/2024