Fast Timing-Conditioned Latent Audio Diffusion
2402.04825
0
0
🌐
Abstract
Generating long-form 44.1kHz stereo audio from text prompts can be computationally demanding. Further, most previous works do not tackle that music and sound effects naturally vary in their duration. Our research focuses on the efficient generation of long-form, variable-length stereo music and sounds at 44.1kHz using text prompts with a generative model. Stable Audio is based on latent diffusion, with its latent defined by a fully-convolutional variational autoencoder. It is conditioned on text prompts as well as timing embeddings, allowing for fine control over both the content and length of the generated music and sounds. Stable Audio is capable of rendering stereo signals of up to 95 sec at 44.1kHz in 8 sec on an A100 GPU. Despite its compute efficiency and fast inference, it is one of the best in two public text-to-music and -audio benchmarks and, differently from state-of-the-art models, can generate music with structure and stereo sounds.
Create account to get full access
Overview
- Researchers focus on efficiently generating long-form, variable-length stereo music and sounds at 44.1kHz using text prompts with a generative model.
- The proposed model, Stable Audio, is based on latent diffusion and a fully-convolutional variational autoencoder.
- Stable Audio can render stereo signals of up to 95 seconds at 44.1kHz in 8 seconds on an A100 GPU, while outperforming state-of-the-art models on public text-to-music and -audio benchmarks.
Plain English Explanation
Creating high-quality, long-form audio, like music and sound effects, from text descriptions can be computationally demanding. Previous approaches often struggled to produce audio that varied naturally in duration. The research paper introduces a new model called Stable Audio that addresses these challenges.
Stable Audio uses a technique called "latent diffusion" to efficiently generate long-form, variable-length stereo audio at a high sample rate of 44.1kHz. It is conditioned on both text prompts and timing embeddings, allowing for fine control over the content and length of the generated audio.
Despite its computational efficiency and fast inference speed, Stable Audio outperforms state-of-the-art models on public benchmarks for text-to-music and text-to-audio generation. Uniquely, it can generate music with a clear structure and stereo sound effects, which sets it apart from other leading models in this area.
Technical Explanation
Stable Audio is based on a latent diffusion model, where the latent space is defined by a fully-convolutional variational autoencoder. This allows the model to efficiently generate long-form, variable-length stereo audio at 44.1kHz sample rate.
The model is conditioned on both text prompts and timing embeddings, which gives it fine-grained control over the content and duration of the generated audio. This contrasts with many previous approaches that struggled to produce audio with naturally varying lengths.
Stable Audio is capable of rendering stereo signals of up to 95 seconds in just 8 seconds on an A100 GPU. Despite this computational efficiency, the model outperforms state-of-the-art approaches on public text-to-music and text-to-audio benchmarks. Uniquely, it can also generate music with clear structure and stereo sound effects, which sets it apart from other leading models like AudioLDM and SonicDiffusion.
Critical Analysis
The researchers acknowledge that while Stable Audio is computationally efficient and high-performing, there are still some limitations to the model. For example, the paper notes that the model may struggle with generating highly complex or chaotic audio, and that further research is needed to improve its handling of longer-form audio.
Additionally, the researchers do not address potential biases or ethical considerations that may arise from a model capable of generating realistic-sounding audio from text prompts. As with any generative AI system, there are concerns about the model being used to create misleading or harmful content.
Overall, the Stable Audio model represents a significant advancement in the field of text-to-audio generation, but there is still room for improvement and further research to address its limitations and ethical implications.
Conclusion
The research paper introduces Stable Audio, a novel generative model that can efficiently produce high-quality, long-form stereo audio from text prompts. By leveraging latent diffusion and a fully-convolutional variational autoencoder, Stable Audio is able to generate variable-length music and sound effects at a 44.1kHz sample rate, outperforming state-of-the-art models on public benchmarks.
This breakthrough in text-to-audio generation has the potential to significantly impact various industries, from media and entertainment to accessibility and assistive technologies. As the researchers continue to refine and expand the capabilities of Stable Audio, it will be interesting to see how the model is applied and the ethical considerations that arise from its use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Long-form music generation with latent diffusion
Zach Evans, Julian D. Parker, CJ Carr, Zack Zukowski, Josiah Taylor, Jordi Pons
0
0
Audio-based generative models for music have seen great strides recently, but so far have not managed to produce full-length music tracks with coherent musical structure. We show that by training a generative model on long temporal contexts it is possible to produce long-form music of up to 4m45s. Our model consists of a diffusion-transformer operating on a highly downsampled continuous latent representation (latent rate of 21.5Hz). It obtains state-of-the-art generations according to metrics on audio quality and prompt alignment, and subjective tests reveal that it produces full-length music with coherent structure.
4/17/2024
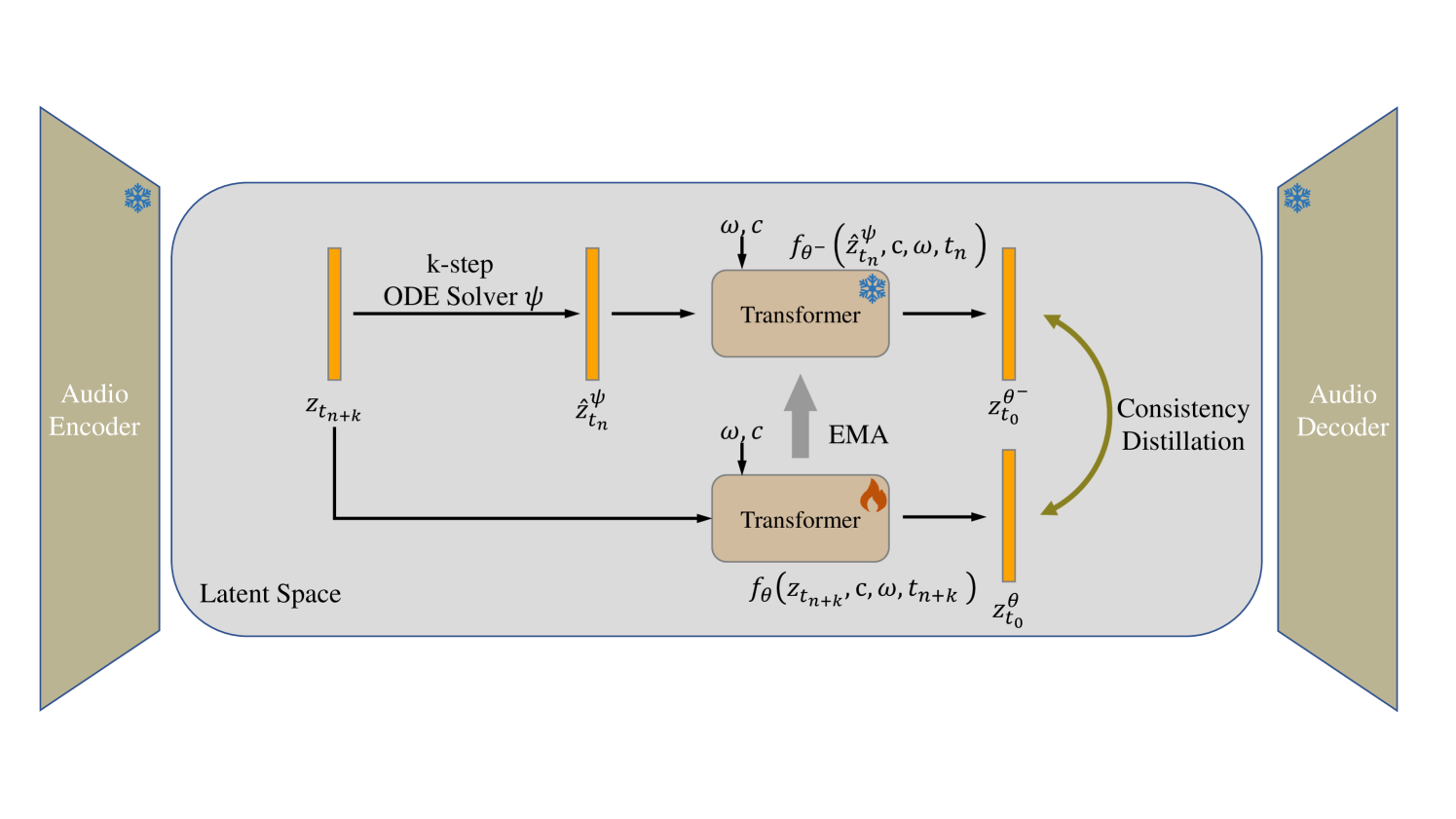
AudioLCM: Text-to-Audio Generation with Latent Consistency Models
Huadai Liu, Rongjie Huang, Yang Liu, Hengyuan Cao, Jialei Wang, Xize Cheng, Siqi Zheng, Zhou Zhao
0
0
Recent advancements in Latent Diffusion Models (LDMs) have propelled them to the forefront of various generative tasks. However, their iterative sampling process poses a significant computational burden, resulting in slow generation speeds and limiting their application in text-to-audio generation deployment. In this work, we introduce AudioLCM, a novel consistency-based model tailored for efficient and high-quality text-to-audio generation. AudioLCM integrates Consistency Models into the generation process, facilitating rapid inference through a mapping from any point at any time step to the trajectory's initial point. To overcome the convergence issue inherent in LDMs with reduced sample iterations, we propose the Guided Latent Consistency Distillation with a multi-step Ordinary Differential Equation (ODE) solver. This innovation shortens the time schedule from thousands to dozens of steps while maintaining sample quality, thereby achieving fast convergence and high-quality generation. Furthermore, to optimize the performance of transformer-based neural network architectures, we integrate the advanced techniques pioneered by LLaMA into the foundational framework of transformers. This architecture supports stable and efficient training, ensuring robust performance in text-to-audio synthesis. Experimental results on text-to-sound generation and text-to-music synthesis tasks demonstrate that AudioLCM needs only 2 iterations to synthesize high-fidelity audios, while it maintains sample quality competitive with state-of-the-art models using hundreds of steps. AudioLCM enables a sampling speed of 333x faster than real-time on a single NVIDIA 4090Ti GPU, making generative models practically applicable to text-to-audio generation deployment. Our extensive preliminary analysis shows that each design in AudioLCM is effective.
6/4/2024
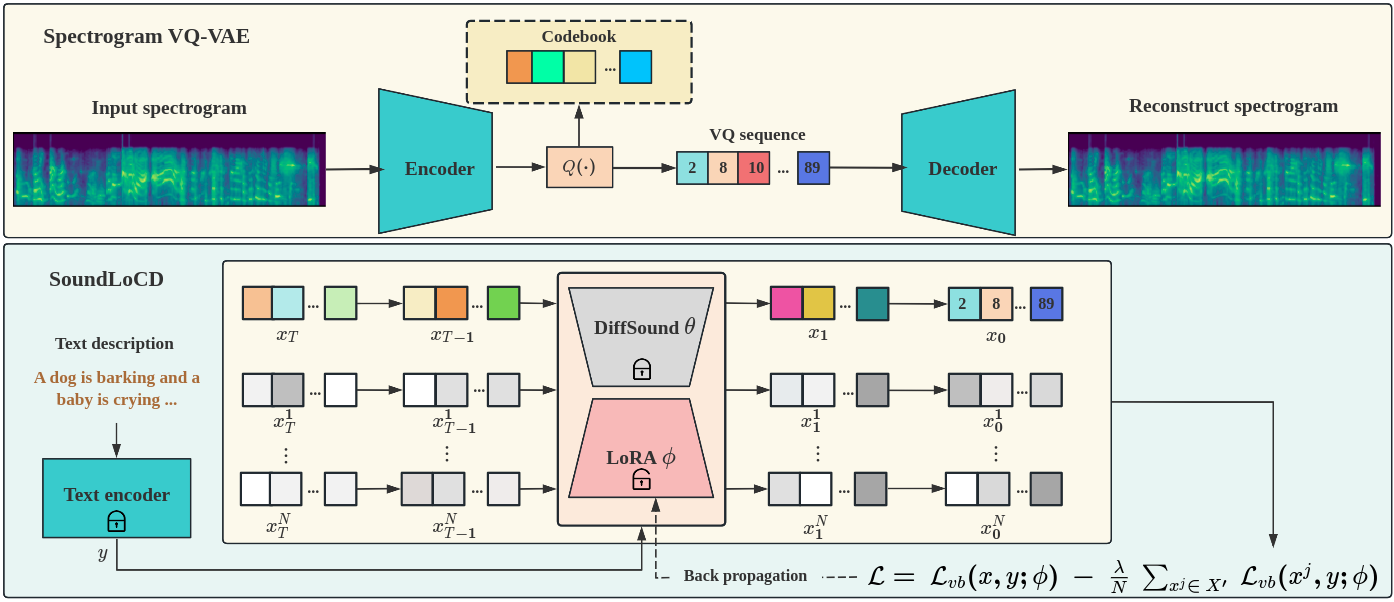
SoundLoCD: An Efficient Conditional Discrete Contrastive Latent Diffusion Model for Text-to-Sound Generation
Xinlei Niu, Jing Zhang, Christian Walder, Charles Patrick Martin
0
0
We present SoundLoCD, a novel text-to-sound generation framework, which incorporates a LoRA-based conditional discrete contrastive latent diffusion model. Unlike recent large-scale sound generation models, our model can be efficiently trained under limited computational resources. The integration of a contrastive learning strategy further enhances the connection between text conditions and the generated outputs, resulting in coherent and high-fidelity performance. Our experiments demonstrate that SoundLoCD outperforms the baseline with greatly reduced computational resources. A comprehensive ablation study further validates the contribution of each component within SoundLoCD. Demo page: url{https://XinleiNIU.github.io/demo-SoundLoCD/}.
5/27/2024

Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
Navonil Majumder, Chia-Yu Hung, Deepanway Ghosal, Wei-Ning Hsu, Rada Mihalcea, Soujanya Poria
0
0
Generative multimodal content is increasingly prevalent in much of the content creation arena, as it has the potential to allow artists and media personnel to create pre-production mockups by quickly bringing their ideas to life. The generation of audio from text prompts is an important aspect of such processes in the music and film industry. Many of the recent diffusion-based text-to-audio models focus on training increasingly sophisticated diffusion models on a large set of datasets of prompt-audio pairs. These models do not explicitly focus on the presence of concepts or events and their temporal ordering in the output audio with respect to the input prompt. Our hypothesis is focusing on how these aspects of audio generation could improve audio generation performance in the presence of limited data. As such, in this work, using an existing text-to-audio model Tango, we synthetically create a preference dataset where each prompt has a winner audio output and some loser audio outputs for the diffusion model to learn from. The loser outputs, in theory, have some concepts from the prompt missing or in an incorrect order. We fine-tune the publicly available Tango text-to-audio model using diffusion-DPO (direct preference optimization) loss on our preference dataset and show that it leads to improved audio output over Tango and AudioLDM2, in terms of both automatic- and manual-evaluation metrics.
4/17/2024