SoundLoCD: An Efficient Conditional Discrete Contrastive Latent Diffusion Model for Text-to-Sound Generation
2405.15338
0
0
Abstract
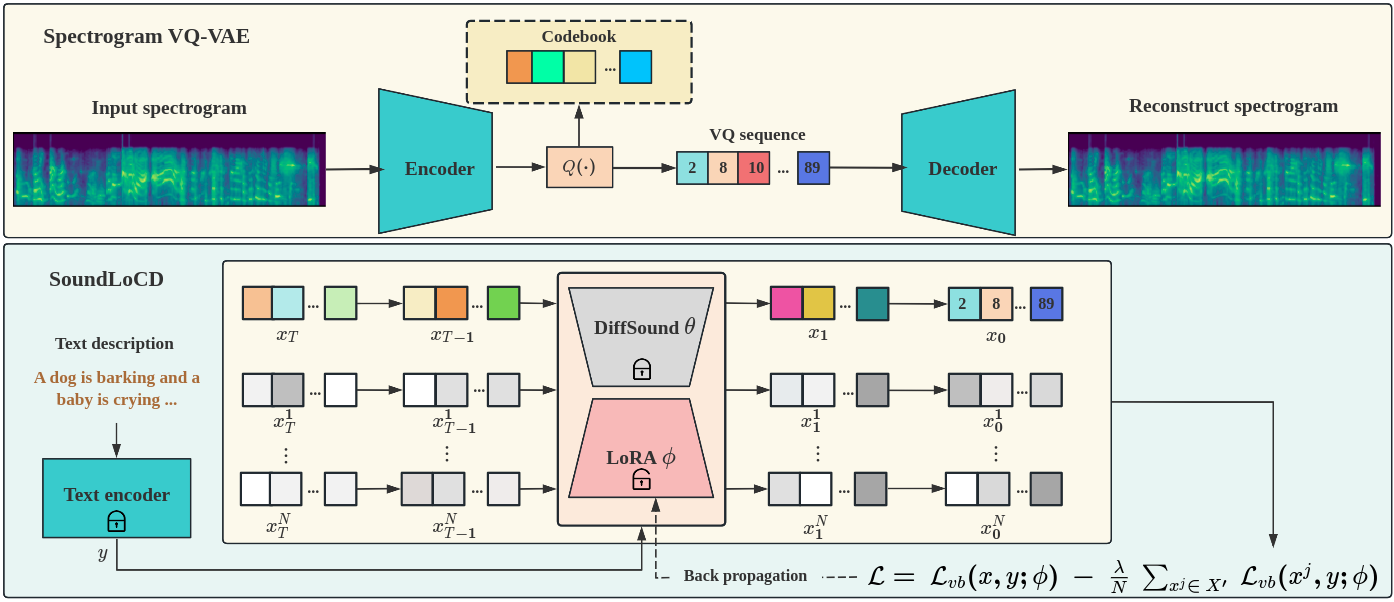
We present SoundLoCD, a novel text-to-sound generation framework, which incorporates a LoRA-based conditional discrete contrastive latent diffusion model. Unlike recent large-scale sound generation models, our model can be efficiently trained under limited computational resources. The integration of a contrastive learning strategy further enhances the connection between text conditions and the generated outputs, resulting in coherent and high-fidelity performance. Our experiments demonstrate that SoundLoCD outperforms the baseline with greatly reduced computational resources. A comprehensive ablation study further validates the contribution of each component within SoundLoCD. Demo page: url{https://XinleiNIU.github.io/demo-SoundLoCD/}.
Create account to get full access
Overview
• This paper presents SOUNDLOCD, an efficient conditional discrete contrastive latent diffusion model for text-to-sound generation. • The model leverages the power of diffusion models and contrastive learning to generate high-quality audio from textual input. • SOUNDLOCD demonstrates impressive performance on various text-to-sound generation tasks, outperforming existing approaches.
Plain English Explanation
SOUNDLOCD is a new AI system that can generate sounds based on text input. It works by using a technique called "diffusion models" and "contrastive learning" to create high-quality audio from text descriptions.
Diffusion models work by gradually adding noise to an image or sound, and then learning to reverse the process to generate new, realistic-looking content. Contrastive learning helps the model learn the relationships between text and audio, allowing it to better understand how to generate sounds that match the given text.
The key innovation of SOUNDLOCD is that it combines these two powerful techniques in an efficient way, allowing it to generate sounds faster and with higher quality than previous text-to-sound systems. This could have many practical applications, such as [link to https://aimodels.fyi/papers/arxiv/fast-timing-conditioned-latent-audio-diffusion] automatically creating sound effects for videos or [link to https://aimodels.fyi/papers/arxiv/sonicdiffusion-audio-driven-image-generation-editing-pretrained] generating audio to match images.
Technical Explanation
SOUNDLOCD is a conditional discrete contrastive latent diffusion model for text-to-sound generation. The model builds on the success of [link to https://aimodels.fyi/papers/arxiv/tango-2-aligning-diffusion-based-text-to] Tango-2, which used diffusion models to generate audio from text, and [link to https://aimodels.fyi/papers/arxiv/cacophony-improved-contrastive-audio-text-model] Cacophony, which used contrastive learning to improve the alignment between audio and text.
SOUNDLOCD combines these techniques in a novel architecture that first encodes the text input into a discrete latent representation, then uses a diffusion model to generate the corresponding audio from this latent space. The contrastive loss helps the model learn the strong connections between the text and audio, allowing it to generate sounds that closely match the input description.
The authors demonstrate that SOUNDLOCD outperforms previous state-of-the-art approaches on a range of text-to-sound generation benchmarks, producing higher-quality audio output while being more computationally efficient.
Critical Analysis
The SOUNDLOCD paper presents a compelling approach to text-to-sound generation, but there are a few potential limitations and areas for further research:
- The authors acknowledge that SOUNDLOCD may struggle with generating audio for more abstract or complex text descriptions, as the model relies on learning the statistical relationships between text and audio. [link to https://aimodels.fyi/papers/arxiv/sonicvisionlm-playing-sound-vision-language-models] Exploring ways to better handle such challenging inputs could be an interesting area for future work.
- While the model demonstrates impressive efficiency, the authors do not provide detailed comparisons of computational costs and inference times with other approaches. Quantifying these metrics more thoroughly could help users better understand the practical advantages of SOUNDLOCD.
- The paper focuses on evaluating SOUNDLOCD's performance on standard text-to-sound benchmarks. Assessing the model's ability to generate audio for real-world applications, such as [link to https://aimodels.fyi/papers/arxiv/fast-timing-conditioned-latent-audio-diffusion] video production or [link to https://aimodels.fyi/papers/arxiv/sonicdiffusion-audio-driven-image-generation-editing-pretrained] audio-driven image generation, could further demonstrate its utility.
Overall, SOUNDLOCD represents an exciting step forward in text-to-sound generation, leveraging the strengths of diffusion models and contrastive learning to achieve impressive results. Continued research in this area could lead to even more powerful and versatile systems for generating high-quality audio from text.
Conclusion
The SOUNDLOCD paper presents a novel approach to text-to-sound generation that combines diffusion models and contrastive learning. By encoding text into a discrete latent representation and using a diffusion process to generate the corresponding audio, SOUNDLOCD is able to produce high-quality sounds that closely match the input text descriptions.
The model's strong performance on standard benchmarks and its computational efficiency make SOUNDLOCD a promising tool for a wide range of applications, from [link to https://aimodels.fyi/papers/arxiv/fast-timing-conditioned-latent-audio-diffusion] video production to [link to https://aimodels.fyi/papers/arxiv/sonicdiffusion-audio-driven-image-generation-editing-pretrained] audio-driven image generation. As research in this field continues, we can expect to see even more advanced text-to-sound models that can handle increasingly complex and diverse inputs, further expanding the possibilities for creative and practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
AudioLCM: Text-to-Audio Generation with Latent Consistency Models
Huadai Liu, Rongjie Huang, Yang Liu, Hengyuan Cao, Jialei Wang, Xize Cheng, Siqi Zheng, Zhou Zhao
0
0
Recent advancements in Latent Diffusion Models (LDMs) have propelled them to the forefront of various generative tasks. However, their iterative sampling process poses a significant computational burden, resulting in slow generation speeds and limiting their application in text-to-audio generation deployment. In this work, we introduce AudioLCM, a novel consistency-based model tailored for efficient and high-quality text-to-audio generation. AudioLCM integrates Consistency Models into the generation process, facilitating rapid inference through a mapping from any point at any time step to the trajectory's initial point. To overcome the convergence issue inherent in LDMs with reduced sample iterations, we propose the Guided Latent Consistency Distillation with a multi-step Ordinary Differential Equation (ODE) solver. This innovation shortens the time schedule from thousands to dozens of steps while maintaining sample quality, thereby achieving fast convergence and high-quality generation. Furthermore, to optimize the performance of transformer-based neural network architectures, we integrate the advanced techniques pioneered by LLaMA into the foundational framework of transformers. This architecture supports stable and efficient training, ensuring robust performance in text-to-audio synthesis. Experimental results on text-to-sound generation and text-to-music synthesis tasks demonstrate that AudioLCM needs only 2 iterations to synthesize high-fidelity audios, while it maintains sample quality competitive with state-of-the-art models using hundreds of steps. AudioLCM enables a sampling speed of 333x faster than real-time on a single NVIDIA 4090Ti GPU, making generative models practically applicable to text-to-audio generation deployment. Our extensive preliminary analysis shows that each design in AudioLCM is effective.
6/4/2024
🌐
Fast Timing-Conditioned Latent Audio Diffusion
Zach Evans, CJ Carr, Josiah Taylor, Scott H. Hawley, Jordi Pons
0
0
Generating long-form 44.1kHz stereo audio from text prompts can be computationally demanding. Further, most previous works do not tackle that music and sound effects naturally vary in their duration. Our research focuses on the efficient generation of long-form, variable-length stereo music and sounds at 44.1kHz using text prompts with a generative model. Stable Audio is based on latent diffusion, with its latent defined by a fully-convolutional variational autoencoder. It is conditioned on text prompts as well as timing embeddings, allowing for fine control over both the content and length of the generated music and sounds. Stable Audio is capable of rendering stereo signals of up to 95 sec at 44.1kHz in 8 sec on an A100 GPU. Despite its compute efficiency and fast inference, it is one of the best in two public text-to-music and -audio benchmarks and, differently from state-of-the-art models, can generate music with structure and stereo sounds.
5/14/2024

SoundCTM: Uniting Score-based and Consistency Models for Text-to-Sound Generation
Koichi Saito, Dongjun Kim, Takashi Shibuya, Chieh-Hsin Lai, Zhi Zhong, Yuhta Takida, Yuki Mitsufuji
0
0
Sound content is an indispensable element for multimedia works such as video games, music, and films. Recent high-quality diffusion-based sound generation models can serve as valuable tools for the creators. However, despite producing high-quality sounds, these models often suffer from slow inference speeds. This drawback burdens creators, who typically refine their sounds through trial and error to align them with their artistic intentions. To address this issue, we introduce Sound Consistency Trajectory Models (SoundCTM). Our model enables flexible transitioning between high-quality 1-step sound generation and superior sound quality through multi-step generation. This allows creators to initially control sounds with 1-step samples before refining them through multi-step generation. While CTM fundamentally achieves flexible 1-step and multi-step generation, its impressive performance heavily depends on an additional pretrained feature extractor and an adversarial loss, which are expensive to train and not always available in other domains. Thus, we reframe CTM's training framework and introduce a novel feature distance by utilizing the teacher's network for a distillation loss. Additionally, while distilling classifier-free guided trajectories, we train conditional and unconditional student models simultaneously and interpolate between these models during inference. We also propose training-free controllable frameworks for SoundCTM, leveraging its flexible sampling capability. SoundCTM achieves both promising 1-step and multi-step real-time sound generation without using any extra off-the-shelf networks. Furthermore, we demonstrate SoundCTM's capability of controllable sound generation in a training-free manner. Our codes, pretrained models, and audio samples are available at https://github.com/sony/soundctm.
6/12/2024

SonicDiffusion: Audio-Driven Image Generation and Editing with Pretrained Diffusion Models
Burak Can Biner, Farrin Marouf Sofian, Umur Berkay Karakac{s}, Duygu Ceylan, Erkut Erdem, Aykut Erdem
0
0
We are witnessing a revolution in conditional image synthesis with the recent success of large scale text-to-image generation methods. This success also opens up new opportunities in controlling the generation and editing process using multi-modal input. While spatial control using cues such as depth, sketch, and other images has attracted a lot of research, we argue that another equally effective modality is audio since sound and sight are two main components of human perception. Hence, we propose a method to enable audio-conditioning in large scale image diffusion models. Our method first maps features obtained from audio clips to tokens that can be injected into the diffusion model in a fashion similar to text tokens. We introduce additional audio-image cross attention layers which we finetune while freezing the weights of the original layers of the diffusion model. In addition to audio conditioned image generation, our method can also be utilized in conjuction with diffusion based editing methods to enable audio conditioned image editing. We demonstrate our method on a wide range of audio and image datasets. We perform extensive comparisons with recent methods and show favorable performance.
5/3/2024