AudioLCM: Text-to-Audio Generation with Latent Consistency Models
2406.00356
0
0
Abstract
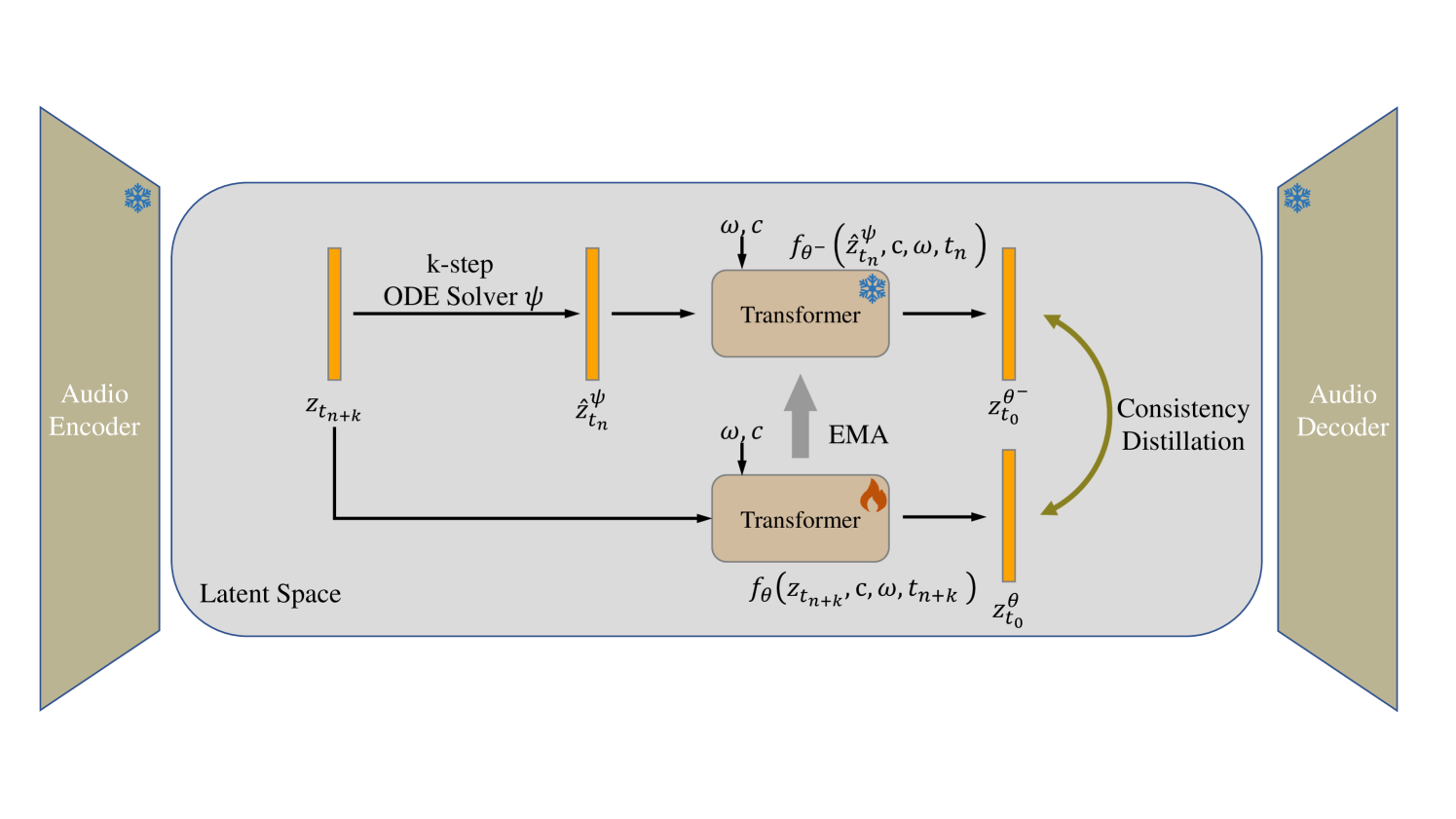
Recent advancements in Latent Diffusion Models (LDMs) have propelled them to the forefront of various generative tasks. However, their iterative sampling process poses a significant computational burden, resulting in slow generation speeds and limiting their application in text-to-audio generation deployment. In this work, we introduce AudioLCM, a novel consistency-based model tailored for efficient and high-quality text-to-audio generation. AudioLCM integrates Consistency Models into the generation process, facilitating rapid inference through a mapping from any point at any time step to the trajectory's initial point. To overcome the convergence issue inherent in LDMs with reduced sample iterations, we propose the Guided Latent Consistency Distillation with a multi-step Ordinary Differential Equation (ODE) solver. This innovation shortens the time schedule from thousands to dozens of steps while maintaining sample quality, thereby achieving fast convergence and high-quality generation. Furthermore, to optimize the performance of transformer-based neural network architectures, we integrate the advanced techniques pioneered by LLaMA into the foundational framework of transformers. This architecture supports stable and efficient training, ensuring robust performance in text-to-audio synthesis. Experimental results on text-to-sound generation and text-to-music synthesis tasks demonstrate that AudioLCM needs only 2 iterations to synthesize high-fidelity audios, while it maintains sample quality competitive with state-of-the-art models using hundreds of steps. AudioLCM enables a sampling speed of 333x faster than real-time on a single NVIDIA 4090Ti GPU, making generative models practically applicable to text-to-audio generation deployment. Our extensive preliminary analysis shows that each design in AudioLCM is effective.
Create account to get full access
Overview
- This paper introduces AudioLCM, a text-to-audio generation model that uses a Latent Consistency Model (LCM) to produce realistic and coherent audio outputs.
- The key innovation is the use of a consistency model in the latent space, which helps ensure the generated audio is aligned with the input text and maintains a consistent style.
- The model is evaluated on multiple text-to-audio generation tasks, including speech synthesis and music generation, and demonstrates strong performance compared to prior approaches.
Plain English Explanation
The researchers developed a new system called AudioLCM that can convert text into realistic-sounding audio, such as speech or music. The core idea is to use a "consistency model" that helps ensure the generated audio matches the input text and maintains a consistent style or "personality" throughout.
Typically, text-to-audio models can struggle to produce coherent outputs, as each audio segment is generated independently. AudioLCM addresses this by modeling the latent (hidden) representations of the audio, ensuring they are consistent with the text input and with each other. This helps the model generate more natural-sounding and cohesive audio.
The researchers tested AudioLCM on various tasks, like synthesizing speech from text and generating music from text descriptions. They found it outperformed previous approaches, producing higher-quality and more consistent audio outputs. This suggests the consistency modeling approach is a promising direction for improving text-to-audio generation systems.
Technical Explanation
The key innovation in AudioLCM is the use of a Latent Consistency Model (LCM) to ensure the generated audio aligns with the input text and maintains a consistent style. Typically, text-to-audio models generate each audio segment independently, which can lead to incoherent outputs.
AudioLCM addresses this by modeling the latent representations of the audio, which capture high-level features like tone, rhythm, and timbre. The LCM is trained to ensure these latent representations are consistent with the input text as well as with each other, helping produce more natural-sounding and coherent audio.
The AudioLCM architecture consists of an encoder that maps text to a latent representation, a consistency model that enforces latent consistency, and a decoder that generates the final audio output. The model is trained end-to-end using a combination of text-audio alignment, latent consistency, and audio reconstruction losses.
Experiments on speech synthesis and music generation tasks show AudioLCM outperforms previous text-to-audio approaches in terms of audio quality and consistency. This demonstrates the effectiveness of the LCM in addressing the coherence issues that often plague text-to-audio generation.
Critical Analysis
The paper presents a compelling approach to improving text-to-audio generation through the use of a Latent Consistency Model. The key strengths are the focus on maintaining coherence and consistency in the generated audio, which is a crucial issue for many existing text-to-audio systems.
However, the paper does not extensively discuss the limitations or potential downsides of the AudioLCM approach. For example, it's unclear how the model would scale to more diverse or open-ended text-to-audio tasks, or how it might handle things like multilingual or multimodal inputs.
Additionally, while the results show improvements over prior methods, the absolute performance of AudioLCM is not necessarily state-of-the-art. Further research could explore ways to enhance the model's capabilities, such as by incorporating more advanced text understanding or audio generation techniques.
Overall, AudioLCM represents a promising step forward in text-to-audio generation, but there is likely room for continued innovation and improvement in this important research area. Readers are encouraged to think critically about the strengths, limitations, and potential future directions of this work.
Conclusion
The AudioLCM paper introduces a novel text-to-audio generation model that uses a Latent Consistency Model to improve the coherence and quality of the generated audio. By modeling the latent representations of the audio and ensuring consistency with the input text, the approach produces more natural-sounding and cohesive outputs compared to prior methods.
The results demonstrate the effectiveness of the consistency modeling approach and suggest it could be a valuable technique for enhancing various text-to-audio generation tasks. As the field continues to advance, further research exploring the scalability, robustness, and potential applications of AudioLCM and similar models may lead to even more capable and impactful text-to-audio systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ConsistencyTTA: Accelerating Diffusion-Based Text-to-Audio Generation with Consistency Distillation
Yatong Bai, Trung Dang, Dung Tran, Kazuhito Koishida, Somayeh Sojoudi
0
0
Diffusion models are instrumental in text-to-audio (TTA) generation. Unfortunately, they suffer from slow inference due to an excessive number of queries to the underlying denoising network per generation. To address this bottleneck, we introduce ConsistencyTTA, a framework requiring only a single non-autoregressive network query, thereby accelerating TTA by hundreds of times. We achieve so by proposing CFG-aware latent consistency model, which adapts consistency generation into a latent space and incorporates classifier-free guidance (CFG) into model training. Moreover, unlike diffusion models, ConsistencyTTA can be finetuned closed-loop with audio-space text-aware metrics, such as CLAP score, to further enhance the generations. Our objective and subjective evaluation on the AudioCaps dataset shows that compared to diffusion-based counterparts, ConsistencyTTA reduces inference computation by 400x while retaining generation quality and diversity.
6/26/2024
📈
Phased Consistency Model
Fu-Yun Wang, Zhaoyang Huang, Alexander William Bergman, Dazhong Shen, Peng Gao, Michael Lingelbach, Keqiang Sun, Weikang Bian, Guanglu Song, Yu Liu, Hongsheng Li, Xiaogang Wang
0
0
The consistency model (CM) has recently made significant progress in accelerating the generation of diffusion models. However, its application to high-resolution, text-conditioned image generation in the latent space (a.k.a., LCM) remains unsatisfactory. In this paper, we identify three key flaws in the current design of LCM. We investigate the reasons behind these limitations and propose the Phased Consistency Model (PCM), which generalizes the design space and addresses all identified limitations. Our evaluations demonstrate that PCM significantly outperforms LCM across 1--16 step generation settings. While PCM is specifically designed for multi-step refinement, it achieves even superior or comparable 1-step generation results to previously state-of-the-art specifically designed 1-step methods. Furthermore, we show that PCM's methodology is versatile and applicable to video generation, enabling us to train the state-of-the-art few-step text-to-video generator. More details are available at https://g-u-n.github.io/projects/pcm/.
5/29/2024

MLCM: Multistep Consistency Distillation of Latent Diffusion Model
Qingsong Xie, Zhenyi Liao, Chen chen, Zhijie Deng, Shixiang Tang, Haonan Lu
0
0
Distilling large latent diffusion models (LDMs) into ones that are fast to sample from is attracting growing research interest. However, the majority of existing methods face a dilemma where they either (i) depend on multiple individual distilled models for different sampling budgets, or (ii) sacrifice generation quality with limited (e.g., 2-4) and/or moderate (e.g., 5-8) sampling steps. To address these, we extend the recent multistep consistency distillation (MCD) strategy to representative LDMs, establishing the Multistep Latent Consistency Models (MLCMs) approach for low-cost high-quality image synthesis. MLCM serves as a unified model for various sampling steps due to the promise of MCD. We further augment MCD with a progressive training strategy to strengthen inter-segment consistency to boost the quality of few-step generations. We take the states from the sampling trajectories of the teacher model as training data for MLCMs to lift the requirements for high-quality training datasets and to bridge the gap between the training and inference of the distilled model. MLCM is compatible with preference learning strategies for further improvement of visual quality and aesthetic appeal. Empirically, MLCM can generate high-quality, delightful images with only 2-8 sampling steps. On the MSCOCO-2017 5K benchmark, MLCM distilled from SDXL gets a CLIP Score of 33.30, Aesthetic Score of 6.19, and Image Reward of 1.20 with only 4 steps, substantially surpassing 4-step LCM [23], 8-step SDXL-Lightning [17], and 8-step HyperSD [33]. We also demonstrate the versatility of MLCMs in applications including controllable generation, image style transfer, and Chinese-to-image generation.
6/13/2024

EdgeFusion: On-Device Text-to-Image Generation
Thibault Castells, Hyoung-Kyu Song, Tairen Piao, Shinkook Choi, Bo-Kyeong Kim, Hanyoung Yim, Changgwun Lee, Jae Gon Kim, Tae-Ho Kim
0
0
The intensive computational burden of Stable Diffusion (SD) for text-to-image generation poses a significant hurdle for its practical application. To tackle this challenge, recent research focuses on methods to reduce sampling steps, such as Latent Consistency Model (LCM), and on employing architectural optimizations, including pruning and knowledge distillation. Diverging from existing approaches, we uniquely start with a compact SD variant, BK-SDM. We observe that directly applying LCM to BK-SDM with commonly used crawled datasets yields unsatisfactory results. It leads us to develop two strategies: (1) leveraging high-quality image-text pairs from leading generative models and (2) designing an advanced distillation process tailored for LCM. Through our thorough exploration of quantization, profiling, and on-device deployment, we achieve rapid generation of photo-realistic, text-aligned images in just two steps, with latency under one second on resource-limited edge devices.
4/19/2024