FC3DNet: A Fully Connected Encoder-Decoder for Efficient Demoir'eing

0

Sign in to get full access
Overview
- The paper proposes a novel deep learning architecture called FC3DNET for efficient demoiréing of images.
- Demoiréing is the process of removing unwanted moiré patterns from images, which can be caused by the interaction between the camera sensor and the subject.
- The FC3DNET model uses a fully connected encoder-decoder structure to effectively remove these moiré patterns.
Plain English Explanation
The paper introduces a new deep learning model called FC3DNET that can help fix a problem called "moiré patterns" in images. Moiré patterns are unwanted visual artifacts that can appear in images, often caused by the interaction between the camera sensor and the subject being photographed.
The FC3DNET model uses a special type of neural network architecture that is "fully connected", meaning the different parts of the network are all linked together. This allows the model to effectively remove the moiré patterns from the images, resulting in cleaner and higher-quality images.
The key advantage of the FC3DNET model is its efficiency, as it can perform this demoiréing task more quickly and with fewer computational resources compared to other approaches. This makes it a practical solution for real-world applications where fast and resource-efficient image processing is important, such as in smartphone cameras or other mobile devices.
Technical Explanation
The authors propose a novel deep learning architecture called FC3DNET for the task of efficient demoiréing. The model uses a fully connected encoder-decoder structure, which is different from the more commonly used convolutional neural networks (CNNs) for image-to-image translation tasks.
The encoder part of the FC3DNET model takes the input image and encodes it into a compact feature representation. The decoder then takes this feature representation and generates the demoiréd output image. The fully connected nature of the network allows it to effectively capture the complex mappings between the input and output, which is important for removing the intricate moiré patterns.
The authors also introduce several architectural innovations, such as the use of channel-wise attention mechanisms and skip connections, to further improve the demoiréing performance of the model. Experiments on both synthetic and real-world datasets show that FC3DNET outperforms state-of-the-art demoiréing methods in terms of both objective metrics and visual quality, while also being more computationally efficient.
Critical Analysis
The paper presents a compelling approach to the problem of demoiréing, which is an important image processing task with practical applications. The authors' choice of a fully connected encoder-decoder architecture is novel and shows promising results, particularly in terms of efficiency compared to other methods.
However, the paper does not provide much insight into the limitations or potential drawbacks of the FC3DNET model. For example, it is unclear how the model would perform on more complex or diverse moiré patterns, or how it would handle edge cases or noise in the input images.
Additionally, the paper would benefit from a deeper discussion of the broader context of demoiréing research, including a comparison to related work such as ShapeMoire, AADNet, and other approaches. This would help readers better understand the significance and novelty of the proposed FC3DNET model.
Conclusion
The FC3DNET model presented in this paper offers a novel and efficient solution for the problem of demoiréing in images. By using a fully connected encoder-decoder architecture, the model is able to effectively remove complex moiré patterns while maintaining computational efficiency.
The results suggest that FC3DNET could be a valuable tool for real-world applications where fast and resource-efficient image processing is important, such as in smartphone cameras or other mobile devices. The authors' work contributes to the ongoing research in demoiréing and image-to-image translation, and the ideas presented in this paper could potentially inspire further advancements in these fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FC3DNet: A Fully Connected Encoder-Decoder for Efficient Demoir'eing
Zhibo Du, Long Peng, Yang Wang, Yang Cao, Zheng-Jun Zha
Moir'e patterns are commonly seen when taking photos of screens. Camera devices usually have limited hardware performance but take high-resolution photos. However, users are sensitive to the photo processing time, which presents a hardly considered challenge of efficiency for demoir'eing methods. To balance the network speed and quality of results, we propose a textbf{F}ully textbf{C}onnected entextbf{C}oder-detextbf{C}oder based textbf{D}emoir'eing textbf{Net}work (FC3DNet). FC3DNet utilizes features with multiple scales in each stage of the decoder for comprehensive information, which contains long-range patterns as well as various local moir'e styles that both are crucial aspects in demoir'eing. Besides, to make full use of multiple features, we design a Multi-Feature Multi-Attention Fusion (MFMAF) module to weigh the importance of each feature and compress them for efficiency. These designs enable our network to achieve performance comparable to state-of-the-art (SOTA) methods in real-world datasets while utilizing only a fraction of parameters, FLOPs, and runtime.
Read more6/24/2024

0
ShapeMoir'e: Channel-Wise Shape-Guided Network for Image Demoir'eing
Jinming Cao, Sicheng Shen, Qiu Zhou, Yifang Yin, Yangyan Li, Roger Zimmermann
Photographing optoelectronic displays often introduces unwanted moir'e patterns due to analog signal interference between the pixel grids of the display and the camera sensor arrays. This work identifies two problems that are largely ignored by existing image demoir'eing approaches: 1) moir'e patterns vary across different channels (RGB); 2) repetitive patterns are constantly observed. However, employing conventional convolutional (CNN) layers cannot address these problems. Instead, this paper presents the use of our recently proposed Shape concept. It was originally employed to model consistent features from fragmented regions, particularly when identical or similar objects coexist in an RGB-D image. Interestingly, we find that the Shape information effectively captures the moir'e patterns in artifact images. Motivated by this discovery, we propose a ShapeMoir'e method to aid in image demoir'eing. Beyond modeling shape features at the patch-level, we further extend this to the global image-level and design a novel Shape-Architecture. Consequently, our proposed method, equipped with both ShapeConv and Shape-Architecture, can be seamlessly integrated into existing approaches without introducing additional parameters or computation overhead during inference. We conduct extensive experiments on four widely used datasets, and the results demonstrate that our ShapeMoir'e achieves state-of-the-art performance, particularly in terms of the PSNR metric. We then apply our method across four popular architectures to showcase its generalization capabilities. Moreover, our ShapeMoir'e is robust and viable under real-world demoir'eing scenarios involving smartphone photographs.
Read more4/30/2024

0
AADNet: Attention aware Demoir'eing Network
M Rakesh Reddy, Shubham Mandloi, Aman Kumar
Moire pattern frequently appears in photographs captured with mobile devices and digital cameras, potentially degrading image quality. Despite recent advancements in computer vision, image demoire'ing remains a challenging task due to the dynamic textures and variations in colour, shape, and frequency of moire patterns. Most existing methods struggle to generalize to unseen datasets, limiting their effectiveness in removing moire patterns from real-world scenarios. In this paper, we propose a novel lightweight architecture, AADNet (Attention Aware Demoireing Network), for high-resolution image demoire'ing that effectively works across different frequency bands and generalizes well to unseen datasets. Extensive experiments conducted on the UHDM dataset validate the effectiveness of our approach, resulting in high-fidelity images.
Read more5/7/2024
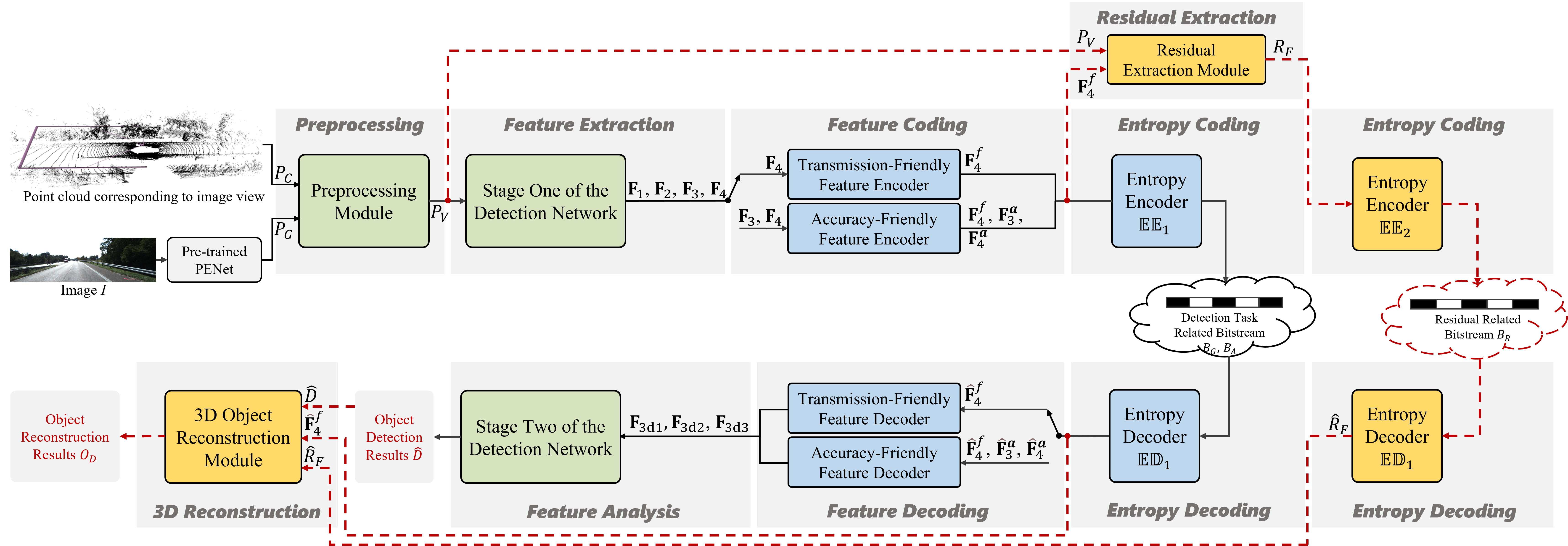
0
Feature Compression for Cloud-Edge Multimodal 3D Object Detection
Chongzhen Tian, Zhengxin Li, Hui Yuan, Raouf Hamzaoui, Liquan Shen, Sam Kwong
Machine vision systems, which can efficiently manage extensive visual perception tasks, are becoming increasingly popular in industrial production and daily life. Due to the challenge of simultaneously obtaining accurate depth and texture information with a single sensor, multimodal data captured by cameras and LiDAR is commonly used to enhance performance. Additionally, cloud-edge cooperation has emerged as a novel computing approach to improve user experience and ensure data security in machine vision systems. This paper proposes a pioneering solution to address the feature compression problem in multimodal 3D object detection. Given a sparse tensor-based object detection network at the edge device, we introduce two modes to accommodate different application requirements: Transmission-Friendly Feature Compression (T-FFC) and Accuracy-Friendly Feature Compression (A-FFC). In T-FFC mode, only the output of the last layer of the network's backbone is transmitted from the edge device. The received feature is processed at the cloud device through a channel expansion module and two spatial upsampling modules to generate multi-scale features. In A-FFC mode, we expand upon the T-FFC mode by transmitting two additional types of features. These added features enable the cloud device to generate more accurate multi-scale features. Experimental results on the KITTI dataset using the VirConv-L detection network showed that T-FFC was able to compress the features by a factor of 6061 with less than a 3% reduction in detection performance. On the other hand, A-FFC compressed the features by a factor of about 901 with almost no degradation in detection performance. We also designed optional residual extraction and 3D object reconstruction modules to facilitate the reconstruction of detected objects. The reconstructed objects effectively reflected details of the original objects.
Read more9/9/2024