Feature Compression for Cloud-Edge Multimodal 3D Object Detection

0
Sign in to get full access
Overview
- This paper proposes a feature compression technique for cloud-edge multimodal 3D object detection.
- It addresses the challenge of efficiently transmitting high-dimensional multimodal features from edge devices to the cloud for processing.
- The key ideas include sparse tensor representation and feature coding to reduce the size of feature data.
Plain English Explanation
The paper tackles the problem of transmitting 3D object detection data from edge devices (like cameras) to a cloud-based system for processing. Edge devices can collect a lot of sensor data, but this data needs to be compressed before sending it to the cloud, to save bandwidth and reduce costs.
The researchers developed a way to compress the 3D object detection features by representing them as a sparse tensor. This means only storing the most important parts of the data, instead of the full dense representation.
They also used feature coding, which is a technique to further reduce the size of the feature data by encoding it in a more compact way. This allows the edge device to send a compressed version of the 3D object detection data to the cloud, which can then be decompressed and used for the final object detection.
The key benefit of this approach is that it enables efficient transmission of high-quality 3D object detection data from edge devices to the cloud, without requiring a lot of bandwidth. This could be useful for applications like self-driving cars, smart cities, or robot vision, where 3D perception is important but bandwidth is limited.
Technical Explanation
The paper proposes a feature compression technique for cloud-edge multimodal 3D object detection. The key technical ideas are:
-
Sparse Tensor Representation: The authors represent the high-dimensional multimodal features as a sparse tensor, which only stores the most important elements. This reduces the size of the feature data compared to a dense representation.
-
Feature Coding: They also apply feature coding techniques to further compress the sparse tensor representation. This involves encoding the feature data in a more compact way, similar to how image or audio data is compressed.
The overall system works as follows:
- Edge devices capture multimodal sensor data (e.g. RGB images, depth maps, point clouds) and extract high-dimensional features.
- These features are compressed using the sparse tensor and feature coding methods.
- The compressed features are transmitted from the edge device to the cloud.
- On the cloud side, the features are decompressed and used for the final 3D object detection task.
The authors evaluate their approach on several 3D object detection benchmarks, comparing it to baseline methods. They show that their compressed features can achieve similar detection performance to the original high-dimensional features, while reducing the transmission bandwidth required.
Critical Analysis
The paper presents a promising approach for efficient cloud-edge multimodal 3D object detection. The use of sparse tensor representation and feature coding to compress the high-dimensional features is a clever way to address the bandwidth constraints of edge-cloud systems.
However, the paper does not discuss certain limitations or potential issues with the proposed method:
- The compression techniques may introduce some loss of information or accuracy, which could impact the final 3D object detection performance. The authors should have provided a more thorough analysis of the accuracy-compression tradeoffs.
- The method may not generalize well to all types of multimodal sensor data or object detection tasks. Further evaluation on a wider range of datasets and applications would be helpful.
- The computational overhead of the compression and decompression steps on the edge and cloud devices is not analyzed. This could be an important practical consideration.
Overall, the research is technically sound, but a more critical discussion of the limitations and potential pitfalls would strengthen the paper.
Conclusion
This paper presents a feature compression technique for cloud-edge multimodal 3D object detection. By representing the high-dimensional features as sparse tensors and applying feature coding, the method can efficiently transmit the data from edge devices to the cloud while maintaining detection performance.
The key contribution is the ability to enable high-quality 3D perception at the edge while minimizing the required bandwidth for cloud-based processing. This could have important implications for applications like autonomous vehicles, smart cities, and robotic systems, where 3D understanding is crucial but compute and communication resources are constrained.
Further research is needed to fully understand the tradeoffs and limitations of the approach, but this work represents an important step forward in addressing the challenges of cloud-edge multimodal perception.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Feature Compression for Cloud-Edge Multimodal 3D Object Detection
Chongzhen Tian, Zhengxin Li, Hui Yuan, Raouf Hamzaoui, Liquan Shen, Sam Kwong
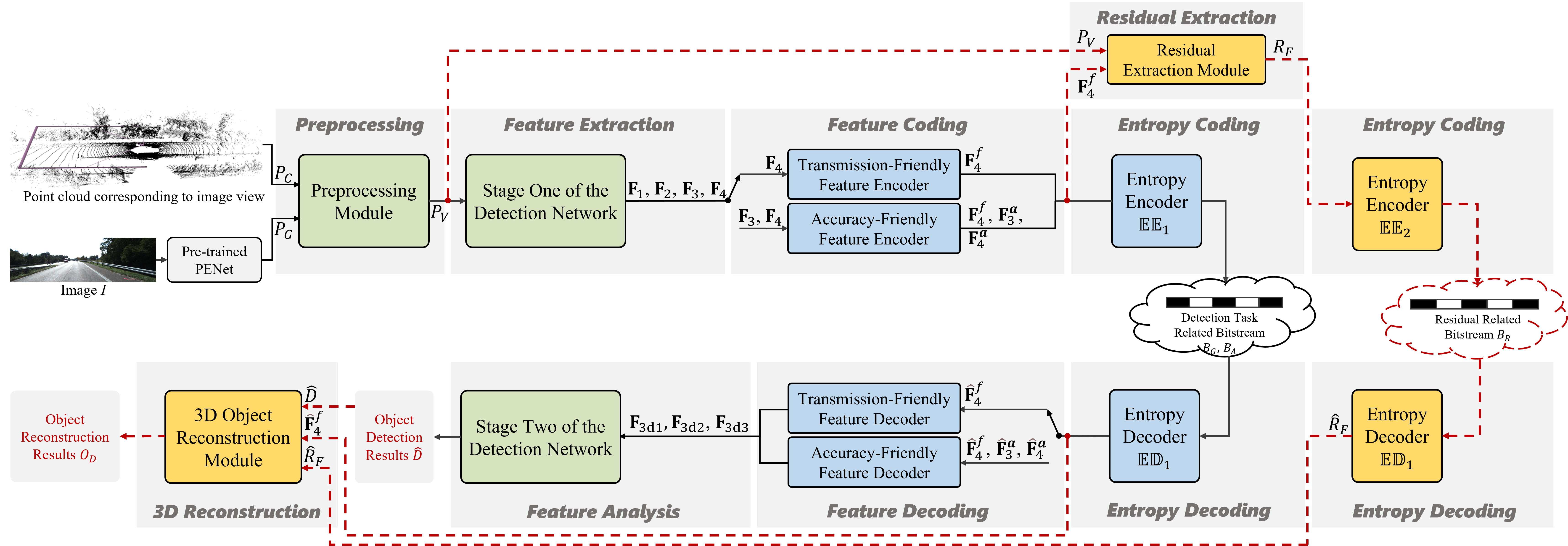
Machine vision systems, which can efficiently manage extensive visual perception tasks, are becoming increasingly popular in industrial production and daily life. Due to the challenge of simultaneously obtaining accurate depth and texture information with a single sensor, multimodal data captured by cameras and LiDAR is commonly used to enhance performance. Additionally, cloud-edge cooperation has emerged as a novel computing approach to improve user experience and ensure data security in machine vision systems. This paper proposes a pioneering solution to address the feature compression problem in multimodal 3D object detection. Given a sparse tensor-based object detection network at the edge device, we introduce two modes to accommodate different application requirements: Transmission-Friendly Feature Compression (T-FFC) and Accuracy-Friendly Feature Compression (A-FFC). In T-FFC mode, only the output of the last layer of the network's backbone is transmitted from the edge device. The received feature is processed at the cloud device through a channel expansion module and two spatial upsampling modules to generate multi-scale features. In A-FFC mode, we expand upon the T-FFC mode by transmitting two additional types of features. These added features enable the cloud device to generate more accurate multi-scale features. Experimental results on the KITTI dataset using the VirConv-L detection network showed that T-FFC was able to compress the features by a factor of 6061 with less than a 3% reduction in detection performance. On the other hand, A-FFC compressed the features by a factor of about 901 with almost no degradation in detection performance. We also designed optional residual extraction and 3D object reconstruction modules to facilitate the reconstruction of detected objects. The reconstructed objects effectively reflected details of the original objects.
Read more9/9/2024
✨
0
PV-SSD: A Multi-Modal Point Cloud Feature Fusion Method for Projection Features and Variable Receptive Field Voxel Features
Yongxin Shao, Aihong Tan, Zhetao Sun, Enhui Zheng, Tianhong Yan, Peng Liao
LiDAR-based 3D object detection and classification is crucial for autonomous driving. However, real-time inference from extremely sparse 3D data is a formidable challenge. To address this problem, a typical class of approaches transforms the point cloud cast into a regular data representation (voxels or projection maps). Then, it performs feature extraction with convolutional neural networks. However, such methods often result in a certain degree of information loss due to down-sampling or over-compression of feature information. This paper proposes a multi-modal point cloud feature fusion method for projection features and variable receptive field voxel features (PV-SSD) based on projection and variable voxelization to solve the information loss problem. We design a two-branch feature extraction structure with a 2D convolutional neural network to extract the point cloud's projection features in bird's-eye view to focus on the correlation between local features. A voxel feature extraction branch is used to extract local fine-grained features. Meanwhile, we propose a voxel feature extraction method with variable sensory fields to reduce the information loss of voxel branches due to downsampling. It avoids missing critical point information by selecting more useful feature points based on feature point weights for the detection task. In addition, we propose a multi-modal feature fusion module for point clouds. To validate the effectiveness of our method, we tested it on the KITTI dataset and ONCE dataset.
Read more4/9/2024
✅
0
Inter-Frame Compression for Dynamic Point Cloud Geometry Coding
Anique Akhtar, Zhu Li, Geert Van der Auwera
Efficient point cloud compression is essential for applications like virtual and mixed reality, autonomous driving, and cultural heritage. This paper proposes a deep learning-based inter-frame encoding scheme for dynamic point cloud geometry compression. We propose a lossy geometry compression scheme that predicts the latent representation of the current frame using the previous frame by employing a novel feature space inter-prediction network. The proposed network utilizes sparse convolutions with hierarchical multiscale 3D feature learning to encode the current frame using the previous frame. The proposed method introduces a novel predictor network for motion compensation in the feature domain to map the latent representation of the previous frame to the coordinates of the current frame to predict the current frame's feature embedding. The framework transmits the residual of the predicted features and the actual features by compressing them using a learned probabilistic factorized entropy model. At the receiver, the decoder hierarchically reconstructs the current frame by progressively rescaling the feature embedding. The proposed framework is compared to the state-of-the-art Video-based Point Cloud Compression (V-PCC) and Geometry-based Point Cloud Compression (G-PCC) schemes standardized by the Moving Picture Experts Group (MPEG). The proposed method achieves more than 88% BD-Rate (Bjontegaard Delta Rate) reduction against G-PCCv20 Octree, more than 56% BD-Rate savings against G-PCCv20 Trisoup, more than 62% BD-Rate reduction against V-PCC intra-frame encoding mode, and more than 52% BD-Rate savings against V-PCC P-frame-based inter-frame encoding mode using HEVC. These significant performance gains are cross-checked and verified in the MPEG working group.
Read more9/4/2024

0
Texture-guided Coding for Deep Features
Lei Xiong, Xin Luo, Zihao Wang, Chaofan He, Shuyuan Zhu, Bing Zeng
With the rapid development of machine vision technology in recent years, many researchers have begun to focus on feature compression that is better suited for machine vision tasks. The target of feature compression is deep features, which arise from convolution in the middle layer of a pre-trained convolutional neural network. However, due to the large volume of data and high level of abstraction of deep features, their application is primarily limited to machine-centric scenarios, which poses significant constraints in situations requiring human-computer interaction. This paper investigates features and textures and proposes a texture-guided feature compression strategy based on their characteristics. Specifically, the strategy comprises feature layers and texture layers. The feature layers serve the machine, including a feature selection module and a feature reconstruction network. With the assistance of texture images, they selectively compress and transmit channels relevant to visual tasks, reducing feature data while providing high-quality features for the machine. The texture layers primarily serve humans and consist of an image reconstruction network. This image reconstruction network leverages features and texture images to reconstruct preview images for humans. Our method fully exploits the characteristics of texture and features. It eliminates feature redundancy, reconstructs high-quality preview images for humans, and supports decision-making. The experimental results demonstrate excellent performance when employing our proposed method to compress the deep features.
Read more5/31/2024