FDive: Learning Relevance Models using Pattern-based Similarity Measures

0
🎯
Sign in to get full access
Overview
- Detecting interesting patterns in large high-dimensional datasets is challenging due to dimensionality and pattern complexity
- Analysts need automated support to extract relevant patterns from these datasets
- This paper presents FDive, a visual active learning system that helps create visually explorable relevance models, assisted by learning a pattern-based similarity
Plain English Explanation
The paper discusses the difficulty of finding interesting patterns in large, complex datasets. These datasets often have many dimensions (features) and complex patterns, making it hard for analysts to identify the most relevant information.
To address this challenge, the researchers developed a system called FDive. FDive uses active learning - where the user provides a small set of example patterns that are relevant or not relevant. The system then uses these labels to learn which similarity measures (combinations of feature descriptors and distance functions) work best for distinguishing relevant from irrelevant data.
Based on the best similarity measure, FDive creates an interactive self-organizing map that classifies the data into relevant and irrelevant clusters. The system also highlights areas of uncertainty, allowing the user to provide additional feedback to improve the model's accuracy.
The researchers evaluated FDive by comparing it to other feature selection techniques and demonstrated its usefulness in a case study analyzing electron microscopy images of brain cells. The results show that FDive can enhance both the quality and understanding of relevance models, leading to new insights for brain research.
Technical Explanation
The paper presents FDive, a visual active learning system that helps create visually explorable relevance models. FDive uses a small set of user-provided labels to rank similarity measures, consisting of feature descriptor and distance function combinations, by their ability to distinguish relevant from irrelevant data.
Based on the best-ranked similarity measure, FDive calculates an interactive self-organizing map-based relevance model, which classifies data according to cluster affiliation. The system also automatically prompts further relevance feedback to improve its accuracy. Uncertain areas, especially near the decision boundaries, are highlighted and can be refined by the user.
The researchers evaluated FDive by comparison to state-of-the-art feature selection techniques and demonstrated its usefulness in a case study classifying electron microscopy images of brain cells. The results show that FDive enhances both the quality and understanding of relevance models and can thus lead to new insights for brain research.
Critical Analysis
The paper provides a thorough description of the FDive system and its evaluation, but there are a few areas that could be explored further. The researchers mention that FDive relies on a small set of user-provided labels, but they don't discuss how the size or quality of this set might affect the system's performance. Additionally, the case study focused on a specific domain (brain cell imaging), so it would be interesting to see how well FDive generalizes to other types of high-dimensional datasets.
The paper also doesn't address potential issues with the self-organizing map approach, such as the difficulty of interpreting the resulting clusters or the sensitivity of the model to parameter settings. While the researchers demonstrate the usefulness of FDive, a more critical examination of its limitations and potential drawbacks would help readers assess the system's real-world applicability.
Conclusion
This paper presents FDive, a visual active learning system that helps create visually explorable relevance models for analyzing large, high-dimensional datasets. By using a small set of user-provided labels to learn optimal similarity measures, FDive can classify data into relevant and irrelevant clusters and highlight areas of uncertainty for further refinement.
The evaluation of FDive shows that it can enhance the quality and understanding of relevance models, leading to new insights in domains like brain research. While the paper provides a comprehensive description of the system, further exploration of its limitations and generalizability could help inform its future development and adoption by analysts working with complex, high-dimensional data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
0
FDive: Learning Relevance Models using Pattern-based Similarity Measures
Frederik L. Dennig, Tom Polk, Zudi Lin, Tobias Schreck, Hanspeter Pfister, Michael Behrisch
The detection of interesting patterns in large high-dimensional datasets is difficult because of their dimensionality and pattern complexity. Therefore, analysts require automated support for the extraction of relevant patterns. In this paper, we present FDive, a visual active learning system that helps to create visually explorable relevance models, assisted by learning a pattern-based similarity. We use a small set of user-provided labels to rank similarity measures, consisting of feature descriptor and distance function combinations, by their ability to distinguish relevant from irrelevant data. Based on the best-ranked similarity measure, the system calculates an interactive Self-Organizing Map-based relevance model, which classifies data according to the cluster affiliation. It also automatically prompts further relevance feedback to improve its accuracy. Uncertain areas, especially near the decision boundaries, are highlighted and can be refined by the user. We evaluate our approach by comparison to state-of-the-art feature selection techniques and demonstrate the usefulness of our approach by a case study classifying electron microscopy images of brain cells. The results show that FDive enhances both the quality and understanding of relevance models and can thus lead to new insights for brain research.
Read more5/15/2024
0
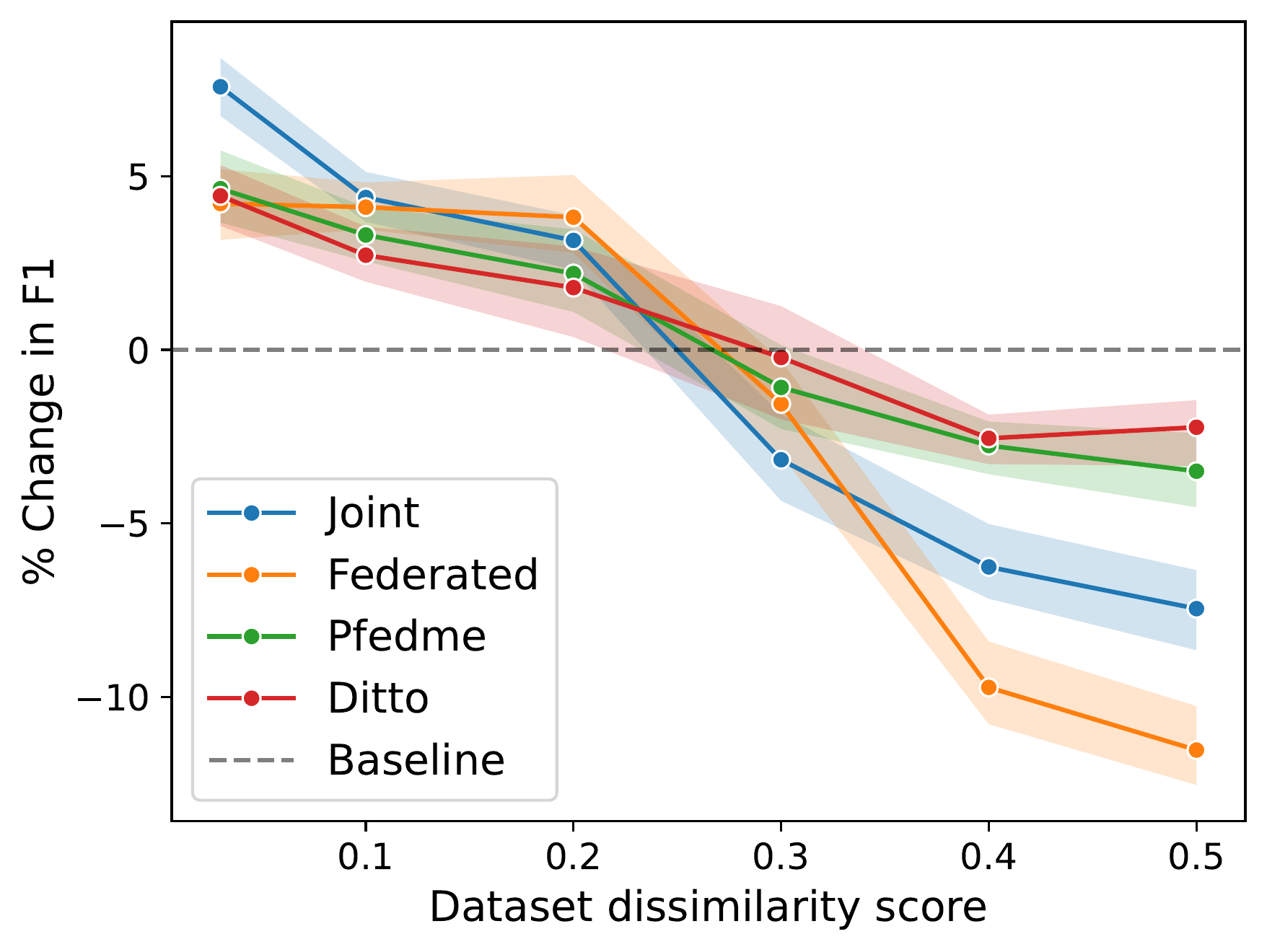
A Universal Metric of Dataset Similarity for Cross-silo Federated Learning
Ahmed Elhussein, Gamze Gursoy
Federated Learning is increasingly used in domains such as healthcare to facilitate collaborative model training without data-sharing. However, datasets located in different sites are often non-identically distributed, leading to degradation of model performance in FL. Most existing methods for assessing these distribution shifts are limited by being dataset or task-specific. Moreover, these metrics can only be calculated by exchanging data, a practice restricted in many FL scenarios. To address these challenges, we propose a novel metric for assessing dataset similarity. Our metric exhibits several desirable properties for FL: it is dataset-agnostic, is calculated in a privacy-preserving manner, and is computationally efficient, requiring no model training. In this paper, we first establish a theoretical connection between our metric and training dynamics in FL. Next, we extensively evaluate our metric on a range of datasets including synthetic, benchmark, and medical imaging datasets. We demonstrate that our metric shows a robust and interpretable relationship with model performance and can be calculated in privacy-preserving manner. As the first federated dataset similarity metric, we believe this metric can better facilitate successful collaborations between sites.
Read more4/30/2024
➖
0
Soft Measures for Extracting Causal Collective Intelligence
Maryam Berijanian, Spencer Dork, Kuldeep Singh, Michael Riley Millikan, Ashlin Riggs, Aadarsh Swaminathan, Sarah L. Gibbs, Scott E. Friedman, Nathan Brugnone
Understanding and modeling collective intelligence is essential for addressing complex social systems. Directed graphs called fuzzy cognitive maps (FCMs) offer a powerful tool for encoding causal mental models, but extracting high-integrity FCMs from text is challenging. This study presents an approach using large language models (LLMs) to automate FCM extraction. We introduce novel graph-based similarity measures and evaluate them by correlating their outputs with human judgments through the Elo rating system. Results show positive correlations with human evaluations, but even the best-performing measure exhibits limitations in capturing FCM nuances. Fine-tuning LLMs improves performance, but existing measures still fall short. This study highlights the need for soft similarity measures tailored to FCM extraction, advancing collective intelligence modeling with NLP.
Read more9/30/2024

0
Supervised Pattern Recognition Involving Skewed Feature Densities
Alexandre Benatti, Luciano da F. Costa
Pattern recognition constitutes a particularly important task underlying a great deal of scientific and technologica activities. At the same time, pattern recognition involves several challenges, including the choice of features to represent the data elements, as well as possible respective transformations. In the present work, the classification potential of the Euclidean distance and a dissimilarity index based on the coincidence similarity index are compared by using the k-neighbors supervised classification method respectively to features resulting from several types of transformations of one- and two-dimensional symmetric densities. Given two groups characterized by respective densities without or with overlap, different types of respective transformations are obtained and employed to quantitatively evaluate the performance of k-neighbors methodologies based on the Euclidean distance an coincidence similarity index. More specifically, the accuracy of classifying the intersection point between the densities of two adjacent groups is taken into account for the comparison. Several interesting results are described and discussed, including the enhanced potential of the dissimilarity index for classifying datasets with right skewed feature densities, as well as the identification that the sharpness of the comparison between data elements can be independent of the respective supervised classification performance.
Read more9/4/2024