FeatUp: A Model-Agnostic Framework for Features at Any Resolution

1

Sign in to get full access
Overview
• FeatUp is a model-agnostic framework that allows features to be extracted at any resolution, even lower than the original input resolution.
• The framework is designed to work with a wide range of machine learning models and can be used for tasks like object detection, semantic segmentation, and image classification.
• FeatUp addresses the challenge of efficiently processing high-resolution images, which can be computationally intensive for many models.
Plain English Explanation
FeatUp is a tool that helps machine learning models work with high-resolution images more efficiently. Many models struggle to process large, high-quality images because it requires a lot of computing power. FeatUp solves this problem by allowing the models to extract important features from the images at a lower resolution, without losing critical information.
This is like taking a detailed photograph and then being able to zoom in on specific areas of interest, even though the overall image is smaller. The key details are still preserved, but the file size and processing requirements are reduced.
By using FeatUp, machine learning models can be applied to a wider range of high-resolution images, opening up new possibilities for tasks like identifying objects, understanding the contents of an image, or classifying images into different categories. This can be especially useful in fields like medical imaging, satellite imagery, or high-definition video analysis, where having access to detailed visual information is important.
Technical Explanation
The core idea behind FeatUp is to decouple the resolution of the input image from the resolution of the features extracted by the machine learning model. Traditional approaches require the model to process the entire high-resolution image, which can be computationally expensive.
FeatUp introduces a novel feature extraction module that can operate at a lower resolution than the input image. This is achieved by using a multi-scale feature fusion technique, which combines features from different levels of the model's neural network. The lower-resolution features are then upsampled to match the original input resolution, preserving the critical details while reducing the computational burden.
The FeatUp framework is designed to be model-agnostic, meaning it can be integrated with a wide range of existing machine learning architectures without requiring significant modifications. This allows researchers and developers to easily incorporate FeatUp into their existing workflows and benefit from its efficiency-enhancing capabilities.
Critical Analysis
The paper presents a thorough evaluation of the FeatUp framework, demonstrating its effectiveness across a variety of tasks and datasets. The authors have carefully considered the potential limitations of their approach, such as the impact of the upsampling process on feature quality and the trade-offs between computational efficiency and model performance.
However, the paper does not explore the scalability of FeatUp to extremely high-resolution images or the impact of different upsampling techniques on the final results. Additionally, the authors do not provide a detailed analysis of the memory and storage requirements of the FeatUp-enabled models, which could be an important consideration for real-world deployments.
Further research could investigate the performance of FeatUp on a broader range of machine learning tasks, as well as explore the integration of FeatUp with state-of-the-art model architectures and training techniques. Comparing the efficiency and accuracy of FeatUp-enabled models to other resolution-reduction approaches could also provide valuable insights.
Conclusion
FeatUp presents a promising solution to the challenge of processing high-resolution images efficiently in machine learning. By decoupling the input resolution from the feature resolution, the framework enables models to extract critical information without being bogged down by the computational complexity of large-scale images.
The flexibility and model-agnostic design of FeatUp make it a versatile tool that can be easily integrated into a wide range of machine learning workflows. As the demand for high-quality visual data continues to grow, FeatUp's ability to unlock the potential of high-resolution imagery for a variety of tasks could have significant implications for fields like computer vision, medical imaging, and remote sensing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
FeatUp: A Model-Agnostic Framework for Features at Any Resolution
Stephanie Fu, Mark Hamilton, Laura Brandt, Axel Feldman, Zhoutong Zhang, William T. Freeman
Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features often lack the spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction because models aggressively pool information over large areas. In this work, we introduce FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. We introduce two variants of FeatUp: one that guides features with high-resolution signal in a single forward pass, and one that fits an implicit model to a single image to reconstruct features at any resolution. Both approaches use a multi-view consistency loss with deep analogies to NeRFs. Our features retain their original semantics and can be swapped into existing applications to yield resolution and performance gains even without re-training. We show that FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, transfer learning for segmentation and depth prediction, and end-to-end training for semantic segmentation.
Read more4/3/2024

0
Adaptive Deep Iris Feature Extractor at Arbitrary Resolutions
Yuho Shoji, Yuka Ogino, Takahiro Toizumi, Atsushi Ito
This paper proposes a deep feature extractor for iris recognition at arbitrary resolutions. Resolution degradation reduces the recognition performance of deep learning models trained by high-resolution images. Using various-resolution images for training can improve the model's robustness while sacrificing recognition performance for high-resolution images. To achieve higher recognition performance at various resolutions, we propose a method of resolution-adaptive feature extraction with automatically switching networks. Our framework includes resolution expert modules specialized for different resolution degradations, including down-sampling and out-of-focus blurring. The framework automatically switches them depending on the degradation condition of an input image. Lower-resolution experts are trained by knowledge-distillation from the high-resolution expert in such a manner that both experts can extract common identity features. We applied our framework to three conventional neural network models. The experimental results show that our method enhances the recognition performance at low-resolution in the conventional methods and also maintains their performance at high-resolution.
Read more7/15/2024

0
Multi-Feature Aggregation in Diffusion Models for Enhanced Face Super-Resolution
Marcelo dos Santos, Rayson Laroca, Rafael O. Ribeiro, Jo~ao C. Neves, David Menotti
Super-resolution algorithms often struggle with images from surveillance environments due to adverse conditions such as unknown degradation, variations in pose, irregular illumination, and occlusions. However, acquiring multiple images, even of low quality, is possible with surveillance cameras. In this work, we develop an algorithm based on diffusion models that utilize a low-resolution image combined with features extracted from multiple low-quality images to generate a super-resolved image while minimizing distortions in the individual's identity. Unlike other algorithms, our approach recovers facial features without explicitly providing attribute information or without the need to calculate a gradient of a function during the reconstruction process. To the best of our knowledge, this is the first time multi-features combined with low-resolution images are used as conditioners to generate more reliable super-resolution images using stochastic differential equations. The FFHQ dataset was employed for training, resulting in state-of-the-art performance in facial recognition and verification metrics when evaluated on the CelebA and Quis-Campi datasets. Our code is publicly available at https://github.com/marcelowds/fasr
Read more8/29/2024
0
XFeat: Accelerated Features for Lightweight Image Matching
Guilherme Potje, Felipe Cadar, Andre Araujo, Renato Martins, Erickson R. Nascimento
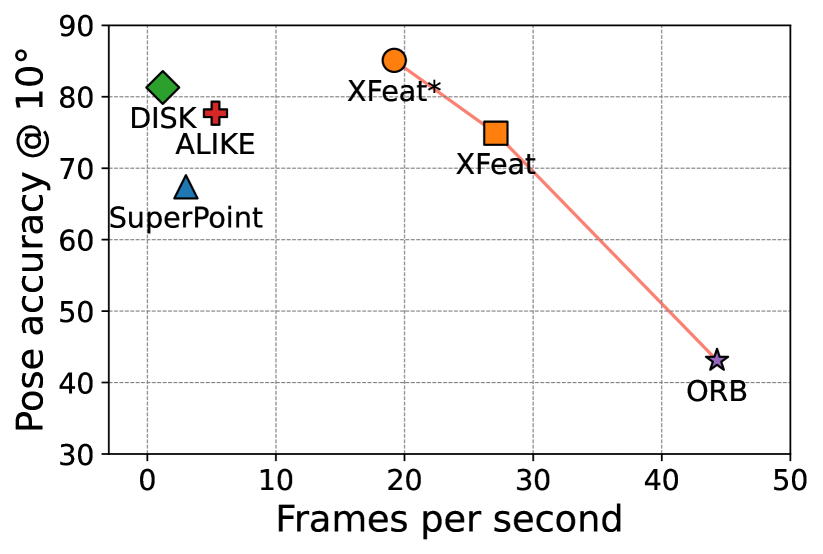
We introduce a lightweight and accurate architecture for resource-efficient visual correspondence. Our method, dubbed XFeat (Accelerated Features), revisits fundamental design choices in convolutional neural networks for detecting, extracting, and matching local features. Our new model satisfies a critical need for fast and robust algorithms suitable to resource-limited devices. In particular, accurate image matching requires sufficiently large image resolutions - for this reason, we keep the resolution as large as possible while limiting the number of channels in the network. Besides, our model is designed to offer the choice of matching at the sparse or semi-dense levels, each of which may be more suitable for different downstream applications, such as visual navigation and augmented reality. Our model is the first to offer semi-dense matching efficiently, leveraging a novel match refinement module that relies on coarse local descriptors. XFeat is versatile and hardware-independent, surpassing current deep learning-based local features in speed (up to 5x faster) with comparable or better accuracy, proven in pose estimation and visual localization. We showcase it running in real-time on an inexpensive laptop CPU without specialized hardware optimizations. Code and weights are available at www.verlab.dcc.ufmg.br/descriptors/xfeat_cvpr24.
Read more5/1/2024