XFeat: Accelerated Features for Lightweight Image Matching

0
Sign in to get full access
Overview
- The paper introduces XFeat, a new accelerated feature extraction method for lightweight image matching.
- XFeat aims to enable efficient image matching on resource-constrained devices like mobile phones.
- It achieves high matching accuracy while being computationally efficient and lightweight.
Plain English Explanation
XFeat: Accelerated Features for Lightweight Image Matching is a new technique for extracting visual features from images in a fast and efficient way. The goal is to enable accurate image matching on devices with limited computing power, like smartphones.
Traditional feature extraction methods can be computationally intensive, making them difficult to use on mobile devices. XFeat addresses this by using a more streamlined approach that is both accurate and efficient. This allows it to perform image matching tasks quickly, even on hardware with modest processing capabilities.
The key insight behind XFeat is finding ways to simplify the feature extraction process without sacrificing too much performance. The researchers achieved this through a series of architectural and algorithmic innovations. The result is a system that can match images accurately while being lightweight enough to run on a wide range of devices.
This type of efficient image matching has many practical applications, such as visual search, augmented reality, and mobile visual assistance. By making these capabilities available on everyday devices, XFeat has the potential to enable new user experiences and unlock novel use cases.
Technical Explanation
XFeat: Accelerated Features for Lightweight Image Matching introduces a novel feature extraction method designed for efficient image matching on resource-constrained platforms. The key contributions include:
-
Lightweight Architecture: The XFeat network has a streamlined design with fewer parameters and computation compared to traditional feature extractors. This makes it suitable for deployment on mobile and embedded devices.
-
Accelerated Feature Extraction: XFeat employs several techniques to speed up the feature extraction process, such as leveraging depthwise separable convolutions and efficient attention mechanisms.
-
Multi-Scale Feature Fusion: XFeat aggregates features at multiple scales to capture both local and global image information, improving the overall matching performance.
-
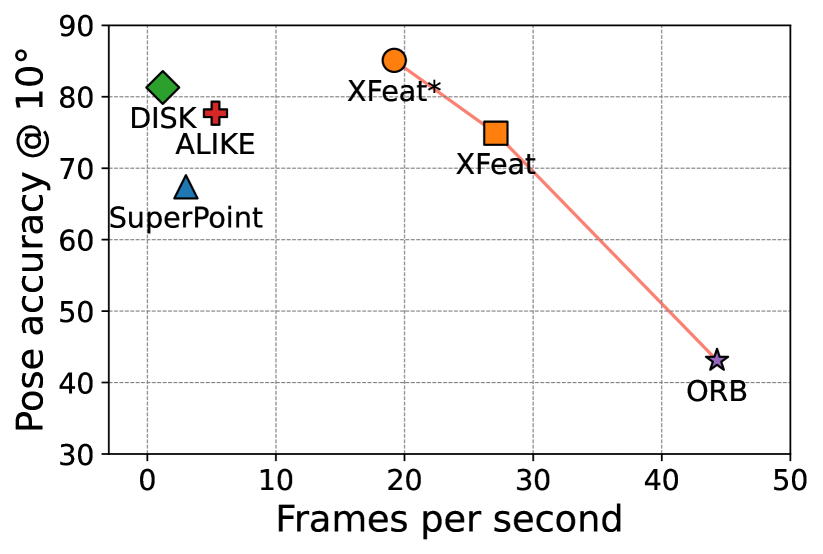
Extensive Evaluation: The authors thoroughly evaluate XFeat on standard benchmarks, demonstrating its superior efficiency and accuracy compared to state-of-the-art methods, including FeatUp, Diffusion Hyperfeatures, LW-Transformer, and MESA.
The efficient design of XFeat, combined with its strong performance, makes it a promising solution for enabling accurate and lightweight image matching on a wide range of devices, from smartphones to embedded systems.
Critical Analysis
The authors of the XFeat: Accelerated Features for Lightweight Image Matching paper have clearly put a lot of thought and effort into developing an efficient feature extraction method for image matching tasks. The technical evaluation demonstrates the advantages of XFeat over existing state-of-the-art approaches, both in terms of computational efficiency and matching accuracy.
However, the paper does not extensively discuss the limitations or potential drawbacks of the proposed method. For example, it would be interesting to understand the performance of XFeat on specific types of images or under various environmental conditions, such as low-light or occlusion scenarios. Additionally, the paper could have explored the generalization capabilities of XFeat beyond the evaluated benchmarks.
Further research could also investigate the tradeoffs between the architectural choices made in XFeat and their impact on different performance metrics, such as energy consumption or memory footprint. Exploring these aspects could provide a more comprehensive understanding of the method's strengths and weaknesses.
Conclusion
XFeat: Accelerated Features for Lightweight Image Matching presents a promising approach for enabling efficient image matching on resource-constrained devices. By designing a lightweight and computationally efficient feature extraction method, the researchers have taken an important step towards bringing advanced computer vision capabilities to a wide range of mobile and embedded applications.
The strong performance of XFeat, combined with its small model size and low latency, suggest that it could be a valuable tool for developers working on visual search, augmented reality, and other vision-based applications targeting mobile and IoT devices. As the demand for such capabilities continues to grow, innovative solutions like XFeat will play a crucial role in bridging the gap between the complexity of computer vision and the limited resources of everyday devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
XFeat: Accelerated Features for Lightweight Image Matching
Guilherme Potje, Felipe Cadar, Andre Araujo, Renato Martins, Erickson R. Nascimento
We introduce a lightweight and accurate architecture for resource-efficient visual correspondence. Our method, dubbed XFeat (Accelerated Features), revisits fundamental design choices in convolutional neural networks for detecting, extracting, and matching local features. Our new model satisfies a critical need for fast and robust algorithms suitable to resource-limited devices. In particular, accurate image matching requires sufficiently large image resolutions - for this reason, we keep the resolution as large as possible while limiting the number of channels in the network. Besides, our model is designed to offer the choice of matching at the sparse or semi-dense levels, each of which may be more suitable for different downstream applications, such as visual navigation and augmented reality. Our model is the first to offer semi-dense matching efficiently, leveraging a novel match refinement module that relies on coarse local descriptors. XFeat is versatile and hardware-independent, surpassing current deep learning-based local features in speed (up to 5x faster) with comparable or better accuracy, proven in pose estimation and visual localization. We showcase it running in real-time on an inexpensive laptop CPU without specialized hardware optimizations. Code and weights are available at www.verlab.dcc.ufmg.br/descriptors/xfeat_cvpr24.
Read more5/1/2024

0
ConDL: Detector-Free Dense Image Matching
Monika Kwiatkowski, Simon Matern, Olaf Hellwich
In this work, we introduce a deep-learning framework designed for estimating dense image correspondences. Our fully convolutional model generates dense feature maps for images, where each pixel is associated with a descriptor that can be matched across multiple images. Unlike previous methods, our model is trained on synthetic data that includes significant distortions, such as perspective changes, illumination variations, shadows, and specular highlights. Utilizing contrastive learning, our feature maps achieve greater invariance to these distortions, enabling robust matching. Notably, our method eliminates the need for a keypoint detector, setting it apart from many existing image-matching techniques.
Read more8/7/2024

1
FeatUp: A Model-Agnostic Framework for Features at Any Resolution
Stephanie Fu, Mark Hamilton, Laura Brandt, Axel Feldman, Zhoutong Zhang, William T. Freeman
Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features often lack the spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction because models aggressively pool information over large areas. In this work, we introduce FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. We introduce two variants of FeatUp: one that guides features with high-resolution signal in a single forward pass, and one that fits an implicit model to a single image to reconstruct features at any resolution. Both approaches use a multi-view consistency loss with deep analogies to NeRFs. Our features retain their original semantics and can be swapped into existing applications to yield resolution and performance gains even without re-training. We show that FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, transfer learning for segmentation and depth prediction, and end-to-end training for semantic segmentation.
Read more4/3/2024
✅
0
Affine-based Deformable Attention and Selective Fusion for Semi-dense Matching
Hongkai Chen, Zixin Luo, Yurun Tian, Xuyang Bai, Ziyu Wang, Lei Zhou, Mingmin Zhen, Tian Fang, David McKinnon, Yanghai Tsin, Long Quan
Identifying robust and accurate correspondences across images is a fundamental problem in computer vision that enables various downstream tasks. Recent semi-dense matching methods emphasize the effectiveness of fusing relevant cross-view information through Transformer. In this paper, we propose several improvements upon this paradigm. Firstly, we introduce affine-based local attention to model cross-view deformations. Secondly, we present selective fusion to merge local and global messages from cross attention. Apart from network structure, we also identify the importance of enforcing spatial smoothness in loss design, which has been omitted by previous works. Based on these augmentations, our network demonstrate strong matching capacity under different settings. The full version of our network achieves state-of-the-art performance among semi-dense matching methods at a similar cost to LoFTR, while the slim version reaches LoFTR baseline's performance with only 15% computation cost and 18% parameters.
Read more5/24/2024