PV-SSD: A Multi-Modal Point Cloud Feature Fusion Method for Projection Features and Variable Receptive Field Voxel Features
2308.06791
0
0
✨
Abstract
LiDAR-based 3D object detection and classification is crucial for autonomous driving. However, real-time inference from extremely sparse 3D data is a formidable challenge. To address this problem, a typical class of approaches transforms the point cloud cast into a regular data representation (voxels or projection maps). Then, it performs feature extraction with convolutional neural networks. However, such methods often result in a certain degree of information loss due to down-sampling or over-compression of feature information. This paper proposes a multi-modal point cloud feature fusion method for projection features and variable receptive field voxel features (PV-SSD) based on projection and variable voxelization to solve the information loss problem. We design a two-branch feature extraction structure with a 2D convolutional neural network to extract the point cloud's projection features in bird's-eye view to focus on the correlation between local features. A voxel feature extraction branch is used to extract local fine-grained features. Meanwhile, we propose a voxel feature extraction method with variable sensory fields to reduce the information loss of voxel branches due to downsampling. It avoids missing critical point information by selecting more useful feature points based on feature point weights for the detection task. In addition, we propose a multi-modal feature fusion module for point clouds. To validate the effectiveness of our method, we tested it on the KITTI dataset and ONCE dataset.
Create account to get full access
Overview
- This paper proposes a new method for 3D object detection and classification using LiDAR data for autonomous driving.
- The key challenge is performing real-time inference on extremely sparse 3D data.
- Typical approaches transform the point cloud into regular data representations like voxels or projection maps, then use convolutional neural networks for feature extraction.
- However, these methods can result in information loss due to downsampling or over-compression.
- The proposed approach, called PV-SSD, uses a multi-modal fusion of projection features and variable receptive field voxel features to address this information loss problem.
Plain English Explanation
LiDAR sensors are crucial for autonomous driving systems to detect and classify objects in 3D space. However, the data collected by LiDAR is very sparse, making it difficult to process in real-time. Most current methods try to solve this by converting the 3D point cloud data into a more regular format, like voxels or projection maps, and then using convolutional neural networks to extract features.
The problem with these approaches is that they can lose important information during the conversion process, either by downsampling the data or compressing it too much. This makes it harder for the neural network to accurately detect and classify objects.
To address this, the PV-SSD method uses a two-pronged approach. First, it extracts projection features by looking at the 2D bird's-eye view of the point cloud data. This helps the system understand the spatial relationships between nearby objects. Second, it extracts variable receptive field voxel features by using a more flexible way of dividing the 3D space into voxels. This reduces the information loss that can happen with standard voxel-based methods.
The key innovation is how these two types of features are combined using a multi-modal feature fusion module. This allows the system to take advantage of the strengths of both the 2D projection features and the 3D voxel features, leading to more accurate object detection and classification.
Technical Explanation
The PV-SSD method uses a two-branch feature extraction architecture. The 2D projection branch takes the bird's-eye view of the point cloud and uses 2D convolutional neural networks to extract spatially-aware features. The 3D voxel branch divides the point cloud into voxels, but uses a variable receptive field approach to better capture local, fine-grained features without as much information loss from downsampling.
The key innovation is the multi-modal feature fusion module that combines the 2D projection features and 3D voxel features. This allows the system to leverage the strengths of both feature types - the spatial awareness of the 2D features and the local detail of the 3D features.
To validate the effectiveness of their approach, the researchers tested PV-SSD on two widely-used datasets for autonomous driving: the KITTI dataset and the ONCE dataset. The results showed significant improvements in 3D object detection and classification performance compared to previous state-of-the-art methods.
Critical Analysis
The PV-SSD method represents an important advance in LiDAR-based 3D object detection for autonomous driving. By carefully fusing 2D projection features and 3D voxel features, the system is able to overcome the information loss issues that plague many previous approaches.
However, the paper does not address some potential limitations of the method. For example, the computational complexity of the multi-modal fusion module is not analyzed, which could be a concern for real-time inference on resource-constrained embedded systems. Additionally, the performance of PV-SSD on more challenging, occluded, or dynamic scenes is not explored.
Further research could also investigate alternative feature fusion techniques, such as attention mechanisms or differentiable rendering, to improve the synergy between the 2D and 3D feature representations. Exploring more efficient sparse convolution operators could also help address computational concerns.
Overall, the PV-SSD method is a promising step forward in LiDAR-based 3D perception for autonomous driving, but there is still room for further refinement and optimization.
Conclusion
This paper presents a novel multi-modal feature fusion approach called PV-SSD for real-time 3D object detection and classification from LiDAR data. By combining 2D projection features and 3D voxel features with variable receptive fields, the system is able to overcome the information loss issues that plague many previous methods.
The results on benchmark datasets demonstrate significant performance improvements over state-of-the-art techniques. While the paper does not address all potential limitations, PV-SSD represents an important advance in LiDAR-based perception for autonomous driving systems. Further research building on this work could lead to even more robust and efficient 3D object detection solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

PillarNeXt: Improving the 3D detector by introducing Voxel2Pillar feature encoding and extracting multi-scale features
Xusheng Li, Chengliang Wang, Shumao Wang, Zhuo Zeng, Ji Liu
0
0
The multi-line LiDAR is widely used in autonomous vehicles, so point cloud-based 3D detectors are essential for autonomous driving. Extracting rich multi-scale features is crucial for point cloud-based 3D detectors in autonomous driving due to significant differences in the size of different types of objects. However, because of the real-time requirements, large-size convolution kernels are rarely used to extract large-scale features in the backbone. Current 3D detectors commonly use feature pyramid networks to obtain large-scale features; however, some objects containing fewer point clouds are further lost during down-sampling, resulting in degraded performance. Since pillar-based schemes require much less computation than voxel-based schemes, they are more suitable for constructing real-time 3D detectors. Hence, we propose the PillarNeXt, a pillar-based scheme. We redesigned the feature encoding, the backbone, and the neck of the 3D detector. We propose the Voxel2Pillar feature encoding, which uses a sparse convolution constructor to construct pillars with richer point cloud features, especially height features. The Voxel2Pillar adds more learnable parameters to the feature encoding, enabling the initial pillars to have higher performance ability. We extract multi-scale and large-scale features in the proposed fully sparse backbone, which does not utilize large-size convolutional kernels; the backbone consists of the proposed multi-scale feature extraction module. The neck consists of the proposed sparse ConvNeXt, whose simple structure significantly improves the performance. We validate the effectiveness of the proposed PillarNeXt on the Waymo Open Dataset, and the object detection accuracy for vehicles, pedestrians, and cyclists is improved. We also verify the effectiveness of each proposed module in detail through ablation studies.
5/21/2024
🔎
PVTransformer: Point-to-Voxel Transformer for Scalable 3D Object Detection
Zhaoqi Leng, Pei Sun, Tong He, Dragomir Anguelov, Mingxing Tan
0
0
3D object detectors for point clouds often rely on a pooling-based PointNet to encode sparse points into grid-like voxels or pillars. In this paper, we identify that the common PointNet design introduces an information bottleneck that limits 3D object detection accuracy and scalability. To address this limitation, we propose PVTransformer: a transformer-based point-to-voxel architecture for 3D detection. Our key idea is to replace the PointNet pooling operation with an attention module, leading to a better point-to-voxel aggregation function. Our design respects the permutation invariance of sparse 3D points while being more expressive than the pooling-based PointNet. Experimental results show our PVTransformer achieves much better performance compared to the latest 3D object detectors. On the widely used Waymo Open Dataset, our PVTransformer achieves state-of-the-art 76.5 mAPH L2, outperforming the prior art of SWFormer by +1.7 mAPH L2.
5/7/2024
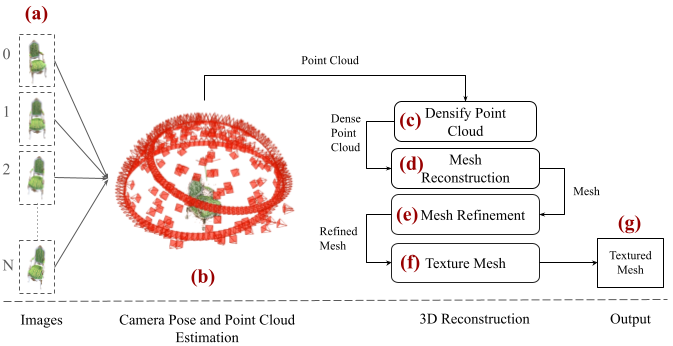
MVSBoost: An Efficient Point Cloud-based 3D Reconstruction
Umair Haroon, Ahmad AlMughrabi, Ricardo Marques, Petia Radeva
0
0
Efficient and accurate 3D reconstruction is crucial for various applications, including augmented and virtual reality, medical imaging, and cinematic special effects. While traditional Multi-View Stereo (MVS) systems have been fundamental in these applications, using neural implicit fields in implicit 3D scene modeling has introduced new possibilities for handling complex topologies and continuous surfaces. However, neural implicit fields often suffer from computational inefficiencies, overfitting, and heavy reliance on data quality, limiting their practical use. This paper presents an enhanced MVS framework that integrates multi-view 360-degree imagery with robust camera pose estimation via Structure from Motion (SfM) and advanced image processing for point cloud densification, mesh reconstruction, and texturing. Our approach significantly improves upon traditional MVS methods, offering superior accuracy and precision as validated using Chamfer distance metrics on the Realistic Synthetic 360 dataset. The developed MVS technique enhances the detail and clarity of 3D reconstructions and demonstrates superior computational efficiency and robustness in complex scene reconstruction, effectively handling occlusions and varying viewpoints. These improvements suggest that our MVS framework can compete with and potentially exceed current state-of-the-art neural implicit field methods, especially in scenarios requiring real-time processing and scalability.
6/21/2024

Zero-shot detection of buildings in mobile LiDAR using Language Vision Model
June Moh Goo, Zichao Zeng, Jan Boehm
0
0
Recent advances have demonstrated that Language Vision Models (LVMs) surpass the existing State-of-the-Art (SOTA) in two-dimensional (2D) computer vision tasks, motivating attempts to apply LVMs to three-dimensional (3D) data. While LVMs are efficient and effective in addressing various downstream 2D vision tasks without training, they face significant challenges when it comes to point clouds, a representative format for representing 3D data. It is more difficult to extract features from 3D data and there are challenges due to large data sizes and the cost of the collection and labelling, resulting in a notably limited availability of datasets. Moreover, constructing LVMs for point clouds is even more challenging due to the requirements for large amounts of data and training time. To address these issues, our research aims to 1) apply the Grounded SAM through Spherical Projection to transfer 3D to 2D, and 2) experiment with synthetic data to evaluate its effectiveness in bridging the gap between synthetic and real-world data domains. Our approach exhibited high performance with an accuracy of 0.96, an IoU of 0.85, precision of 0.92, recall of 0.91, and an F1 score of 0.92, confirming its potential. However, challenges such as occlusion problems and pixel-level overlaps of multi-label points during spherical image generation remain to be addressed in future studies.
4/16/2024