Recursive Joint Cross-Modal Attention for Multimodal Fusion in Dimensional Emotion Recognition
2403.13659
0
0
Abstract
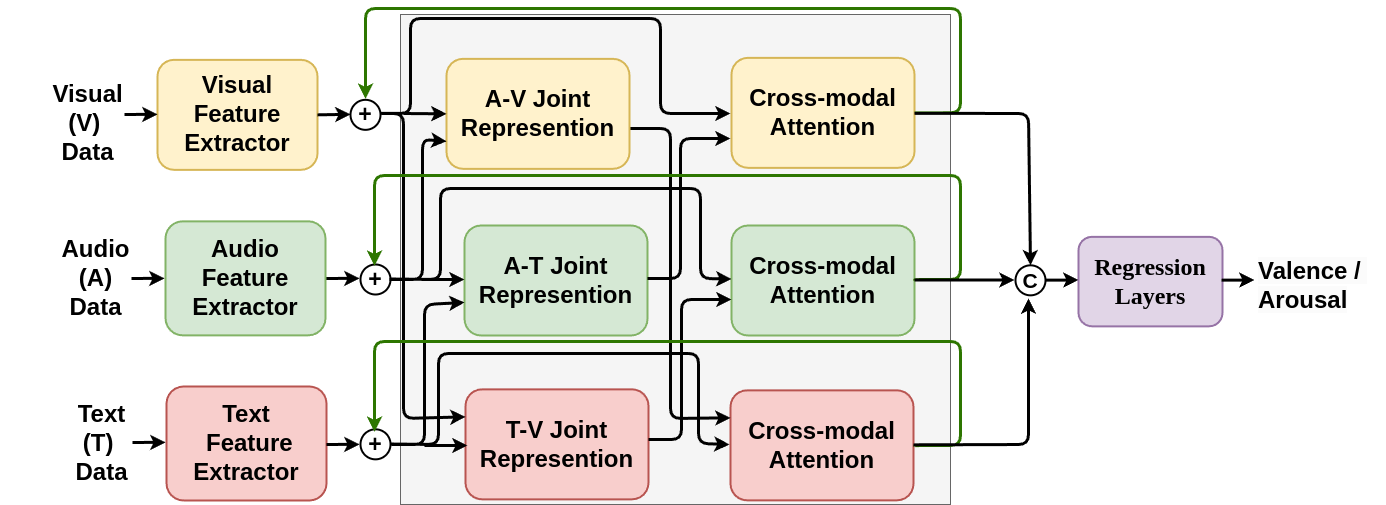
Though multimodal emotion recognition has achieved significant progress over recent years, the potential of rich synergic relationships across the modalities is not fully exploited. In this paper, we introduce Recursive Joint Cross-Modal Attention (RJCMA) to effectively capture both intra- and inter-modal relationships across audio, visual, and text modalities for dimensional emotion recognition. In particular, we compute the attention weights based on cross-correlation between the joint audio-visual-text feature representations and the feature representations of individual modalities to simultaneously capture intra- and intermodal relationships across the modalities. The attended features of the individual modalities are again fed as input to the fusion model in a recursive mechanism to obtain more refined feature representations. We have also explored Temporal Convolutional Networks (TCNs) to improve the temporal modeling of the feature representations of individual modalities. Extensive experiments are conducted to evaluate the performance of the proposed fusion model on the challenging Affwild2 dataset. By effectively capturing the synergic intra- and inter-modal relationships across audio, visual, and text modalities, the proposed fusion model achieves a Concordance Correlation Coefficient (CCC) of 0.585 (0.542) and 0.674 (0.619) for valence and arousal respectively on the validation set(test set). This shows a significant improvement over the baseline of 0.240 (0.211) and 0.200 (0.191) for valence and arousal, respectively, in the validation set (test set), achieving second place in the valence-arousal challenge of the 6th Affective Behavior Analysis in-the-Wild (ABAW) competition.
Create account to get full access
Overview
- This paper proposes a new approach called "Recursive Cross-Modal Attention" for fusing multimodal data (visual and audio) to recognize emotions in a dimensional framework.
- The key idea is to use attention mechanisms to adaptively combine the visual and audio features, allowing the model to learn how to best integrate the different modalities.
- The authors demonstrate the effectiveness of their approach on standard emotion recognition benchmarks, showing improved performance compared to previous multimodal fusion methods.
Plain English Explanation
Emotions are complex and can be expressed through various means, like facial expressions, tone of voice, body language, and more. Recognizing emotions based on these different signals is an important task with applications in areas like mental health, entertainment, and human-computer interaction.
The paper introduces a novel technique called "Recursive Cross-Modal Attention" that aims to better fuse visual and audio information to improve emotion recognition. The key idea is to use "attention" - a machine learning concept that allows the model to focus on the most relevant parts of the input data.
Specifically, the model learns to adaptively combine the visual features (like facial expressions) and audio features (like tone of voice) in a way that maximizes the emotion recognition performance. This is done recursively, meaning the model refines the fusion process multiple times to get the best result.
By using this cross-modal attention mechanism, the model can discover the most informative relationships between the visual and audio signals for recognizing different emotions. This allows it to outperform previous approaches that used simpler ways of combining the modalities.
Technical Explanation
The proposed approach consists of two main components: a Visual Network and an Audio Network. Each network processes its respective modality (visual or audio) and extracts relevant features.
The Visual Network uses a convolutional neural network to process the input images and extract visual features. The Audio Network uses a recurrent neural network to process the audio waveform and extract audio features.
The key innovation is the Recursive Cross-Modal Attention module, which takes the visual and audio features as input and learns to fuse them in an adaptive way. This module applies attention mechanisms to discover the most relevant relationships between the visual and audio features for emotion recognition.
Specifically, the module first computes cross-modal attention weights that indicate how much each visual feature should attend to each audio feature, and vice versa. It then uses these weights to create fused multimodal features. Crucially, this process is repeated recursively, with the fused features fed back into the attention mechanism to further refine the feature fusion.
The final fused features are then passed through fully-connected layers to predict the emotion dimensions (valence and arousal). The authors demonstrate the effectiveness of their approach on standard emotion recognition benchmarks, showing improved performance over previous multimodal fusion methods.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the proposed Recursive Cross-Modal Attention approach, testing it on multiple emotion recognition datasets and comparing it to a variety of baselines.
One potential limitation is that the paper does not provide an in-depth analysis of the learned attention weights or fused features. Understanding how the model is actually combining the visual and audio modalities could provide additional insights and suggest ways to further improve the approach.
Additionally, the paper does not discuss the computational complexity or runtime of the recursive attention mechanism. As the number of recursive steps increases, the computational overhead may become a practical concern, especially for real-time applications.
Finally, while the authors demonstrate the effectiveness of their approach on standard benchmarks, it would be valuable to see how it generalizes to more diverse or challenging emotion recognition scenarios, such as in-the-wild data or cross-cultural settings.
Conclusion
This paper presents a novel multimodal fusion technique called Recursive Cross-Modal Attention that adaptively combines visual and audio features to improve emotion recognition performance. By using attention mechanisms to discover the most relevant relationships between the modalities, the approach outperforms previous multimodal fusion methods.
The technical contributions and strong empirical results suggest that this approach could be a valuable tool for building more accurate and robust emotion recognition systems, with potential applications in human-computer interaction, mental health monitoring, and beyond. Further research into the interpretability of the learned attention mechanisms and the scalability of the recursive fusion process could help unlock the full potential of this technique.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Joint Multimodal Transformer for Emotion Recognition in the Wild
Paul Waligora, Haseeb Aslam, Osama Zeeshan, Soufiane Belharbi, Alessandro Lameiras Koerich, Marco Pedersoli, Simon Bacon, Eric Granger
0
0
Multimodal emotion recognition (MMER) systems typically outperform unimodal systems by leveraging the inter- and intra-modal relationships between, e.g., visual, textual, physiological, and auditory modalities. This paper proposes an MMER method that relies on a joint multimodal transformer (JMT) for fusion with key-based cross-attention. This framework can exploit the complementary nature of diverse modalities to improve predictive accuracy. Separate backbones capture intra-modal spatiotemporal dependencies within each modality over video sequences. Subsequently, our JMT fusion architecture integrates the individual modality embeddings, allowing the model to effectively capture inter- and intra-modal relationships. Extensive experiments on two challenging expression recognition tasks -- (1) dimensional emotion recognition on the Affwild2 dataset (with face and voice) and (2) pain estimation on the Biovid dataset (with face and biosensors) -- indicate that our JMT fusion can provide a cost-effective solution for MMER. Empirical results show that MMER systems with our proposed fusion allow us to outperform relevant baseline and state-of-the-art methods.
4/23/2024
👁️
Inconsistency-Aware Cross-Attention for Audio-Visual Fusion in Dimensional Emotion Recognition
R Gnana Praveen, Jahangir Alam
0
0
Leveraging complementary relationships across modalities has recently drawn a lot of attention in multimodal emotion recognition. Most of the existing approaches explored cross-attention to capture the complementary relationships across the modalities. However, the modalities may also exhibit weak complementary relationships, which may deteriorate the cross-attended features, resulting in poor multimodal feature representations. To address this problem, we propose Inconsistency-Aware Cross-Attention (IACA), which can adaptively select the most relevant features on-the-fly based on the strong or weak complementary relationships across audio and visual modalities. Specifically, we design a two-stage gating mechanism that can adaptively select the appropriate relevant features to deal with weak complementary relationships. Extensive experiments are conducted on the challenging Aff-Wild2 dataset to show the robustness of the proposed model.
5/22/2024

Audio-Visual Person Verification based on Recursive Fusion of Joint Cross-Attention
R. Gnana Praveen, Jahangir Alam
0
0
Person or identity verification has been recently gaining a lot of attention using audio-visual fusion as faces and voices share close associations with each other. Conventional approaches based on audio-visual fusion rely on score-level or early feature-level fusion techniques. Though existing approaches showed improvement over unimodal systems, the potential of audio-visual fusion for person verification is not fully exploited. In this paper, we have investigated the prospect of effectively capturing both the intra- and inter-modal relationships across audio and visual modalities, which can play a crucial role in significantly improving the fusion performance over unimodal systems. In particular, we introduce a recursive fusion of a joint cross-attentional model, where a joint audio-visual feature representation is employed in the cross-attention framework in a recursive fashion to progressively refine the feature representations that can efficiently capture the intra-and inter-modal relationships. To further enhance the audio-visual feature representations, we have also explored BLSTMs to improve the temporal modeling of audio-visual feature representations. Extensive experiments are conducted on the Voxceleb1 dataset to evaluate the proposed model. Results indicate that the proposed model shows promising improvement in fusion performance by adeptly capturing the intra-and inter-modal relationships across audio and visual modalities.
4/29/2024

Feature Fusion Based on Mutual-Cross-Attention Mechanism for EEG Emotion Recognition
Yimin Zhao, Jin Gu
0
0
An objective and accurate emotion diagnostic reference is vital to psychologists, especially when dealing with patients who are difficult to communicate with for pathological reasons. Nevertheless, current systems based on Electroencephalography (EEG) data utilized for sentiment discrimination have some problems, including excessive model complexity, mediocre accuracy, and limited interpretability. Consequently, we propose a novel and effective feature fusion mechanism named Mutual-Cross-Attention (MCA). Combining with a specially customized 3D Convolutional Neural Network (3D-CNN), this purely mathematical mechanism adeptly discovers the complementary relationship between time-domain and frequency-domain features in EEG data. Furthermore, the new designed Channel-PSD-DE 3D feature also contributes to the high performance. The proposed method eventually achieves 99.49% (valence) and 99.30% (arousal) accuracy on DEAP dataset.
6/21/2024