A Federated Learning Benchmark on Tabular Data: Comparing Tree-Based Models and Neural Networks
2405.02074
0
0

Abstract
Federated Learning (FL) has lately gained traction as it addresses how machine learning models train on distributed datasets. FL was designed for parametric models, namely Deep Neural Networks (DNNs).Thus, it has shown promise on image and text tasks. However, FL for tabular data has received little attention. Tree-Based Models (TBMs) have been considered to perform better on tabular data and they are starting to see FL integrations. In this study, we benchmark federated TBMs and DNNs for horizontal FL, with varying data partitions, on 10 well-known tabular datasets. Our novel benchmark results indicates that current federated boosted TBMs perform better than federated DNNs in different data partitions. Furthermore, a federated XGBoost outperforms all other models. Lastly, we find that federated TBMs perform better than federated parametric models, even when increasing the number of clients significantly.
Create account to get full access
Overview
- This paper presents a federated learning benchmark on tabular data, comparing the performance of tree-based models and neural networks.
- Federated learning is a decentralized machine learning approach where models are trained on distributed devices without centralized data collection.
- The authors evaluate the effectiveness of different federated learning algorithms, including TabNet, FedXGBoost, and FedFT, on tabular datasets with non-IID (non-independent and identically distributed) data.
- The results provide insights into the performance of tree-based and neural network models in a federated learning setting, which can inform the selection of appropriate algorithms for real-world federated learning applications.
Plain English Explanation
In this paper, the researchers compare different machine learning models that can be used in a federated learning system. Federated learning is a way of training AI models without centralizing all the data. Instead, the data stays on people's devices, and the models are trained by sharing updates between the devices.
The researchers looked at how well tree-based models like XGBoost and neural networks like TabNet perform in a federated learning setting, using tabular (spreadsheet-like) data that is not evenly distributed across the devices.
They found that the tree-based models generally performed better than the neural networks, especially when the data was very different across the devices. This suggests that tree-based models may be a better choice for federated learning tasks involving tabular data, as they can handle the non-uniform data distribution better than neural networks.
These findings can help researchers and companies choose the right machine learning models for their federated learning projects, depending on the type of data they are working with.
Technical Explanation
The paper evaluates the performance of various federated learning algorithms on tabular datasets with non-IID data. The authors compare tree-based models, such as FedXGBoost, and neural networks, such as FedTabNet, in a federated learning setting.
The experiments are conducted using several tabular datasets, including some with non-IID data distributions across the client devices. The authors implement different federated learning algorithms, including FedFT, and evaluate their performance in terms of model accuracy, convergence speed, and communication efficiency.
The results show that tree-based models, such as FedXGBoost, generally outperform neural networks like FedTabNet in the federated learning setting, especially when the data is non-IID. The tree-based models demonstrate better performance, faster convergence, and lower communication overhead compared to the neural network models.
The authors attribute the superior performance of the tree-based models to their ability to better handle the non-uniform data distribution in the federated learning setting. The findings suggest that tree-based models may be a more suitable choice for federated learning tasks involving tabular data.
Critical Analysis
The paper provides a comprehensive benchmark of federated learning algorithms on tabular datasets, which is valuable for researchers and practitioners in the field. The authors have carefully designed the experiments and used appropriate evaluation metrics to assess the performance of the models.
One potential limitation of the study is the use of only a few tabular datasets, which may not capture the full range of data characteristics that can be encountered in real-world federated learning applications. It would be beneficial to expand the benchmark to include a wider variety of tabular datasets, potentially with different levels of non-IID distribution, to further validate the findings.
Additionally, the paper focuses on the comparison of tree-based models and neural networks, but it would be interesting to see how other federated learning algorithms, such as FedEM or FedMix, perform in this context. Expanding the benchmark to include a broader range of federated learning algorithms could provide a more comprehensive understanding of the trade-offs and suitability of different approaches for tabular data.
Conclusion
This paper presents a valuable benchmark for evaluating the performance of federated learning algorithms on tabular data. The key finding is that tree-based models, such as FedXGBoost, generally outperform neural networks like FedTabNet in a federated learning setting, especially when the data is non-IID across client devices.
These insights can inform the selection of appropriate machine learning models for federated learning applications involving tabular data, which are common in domains like healthcare, finance, and IoT. The results highlight the importance of considering the characteristics of the data and the federated learning environment when choosing the right algorithm for a given problem.
The paper contributes to the growing body of research on federated learning and provides a solid foundation for further exploration of federated learning techniques for tabular data and other real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Federated Learning for Tabular Data using TabNet: A Vehicular Use-Case
William Lindskog, Christian Prehofer
0
0
In this paper, we show how Federated Learning (FL) can be applied to vehicular use-cases in which we seek to classify obstacles, irregularities and pavement types on roads. Our proposed framework utilizes FL and TabNet, a state-of-the-art neural network for tabular data. We are the first to demonstrate how TabNet can be integrated with FL. Moreover, we achieve a maximum test accuracy of 93.6%. Finally, we reason why FL is a suitable concept for this data set.
5/6/2024

New!A Closer Look at Deep Learning on Tabular Data
Han-Jia Ye, Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, De-Chuan Zhan
0
0
Tabular data is prevalent across various domains in machine learning. Although Deep Neural Network (DNN)-based methods have shown promising performance comparable to tree-based ones, in-depth evaluation of these methods is challenging due to varying performance ranks across diverse datasets. In this paper, we propose a comprehensive benchmark comprising 300 tabular datasets, covering a wide range of task types, size distributions, and domains. We perform an extensive comparison between state-of-the-art deep tabular methods and tree-based methods, revealing the average rank of all methods and highlighting the key factors that influence the success of deep tabular methods. Next, we analyze deep tabular methods based on their training dynamics, including changes in validation metrics and other statistics. For each dataset-method pair, we learn a mapping from both the meta-features of datasets and the first part of the validation curve to the final validation set performance and even the evolution of validation curves. This mapping extracts essential meta-features that influence prediction accuracy, helping the analysis of tabular methods from novel aspects. Based on the performance of all methods on this large benchmark, we identify two subsets of 45 datasets each. The first subset contains datasets that favor either tree-based methods or DNN-based methods, serving as effective analysis tools to evaluate strategies (e.g., attribute encoding strategies) for improving deep tabular models. The second subset contains datasets where the ranks of methods are consistent with the overall benchmark, acting as a probe for tabular analysis. These ``tiny tabular benchmarks'' will facilitate further studies on tabular data.
7/2/2024

Histogram-Based Federated XGBoost using Minimal Variance Sampling for Federated Tabular Data
William Lindskog, Christian Prehofer, Sarandeep Singh
0
0
Federated Learning (FL) has gained considerable traction, yet, for tabular data, FL has received less attention. Most FL research has focused on Neural Networks while Tree-Based Models (TBMs) such as XGBoost have historically performed better on tabular data. It has been shown that subsampling of training data when building trees can improve performance but it is an open problem whether such subsampling can improve performance in FL. In this paper, we evaluate a histogram-based federated XGBoost that uses Minimal Variance Sampling (MVS). We demonstrate the underlying algorithm and show that our model using MVS can improve performance in terms of accuracy and regression error in a federated setting. In our evaluation, our model using MVS performs better than uniform (random) sampling and no sampling at all. It achieves both outstanding local and global performance on a new set of federated tabular datasets. Federated XGBoost using MVS also outperforms centralized XGBoost in half of the studied cases.
5/6/2024
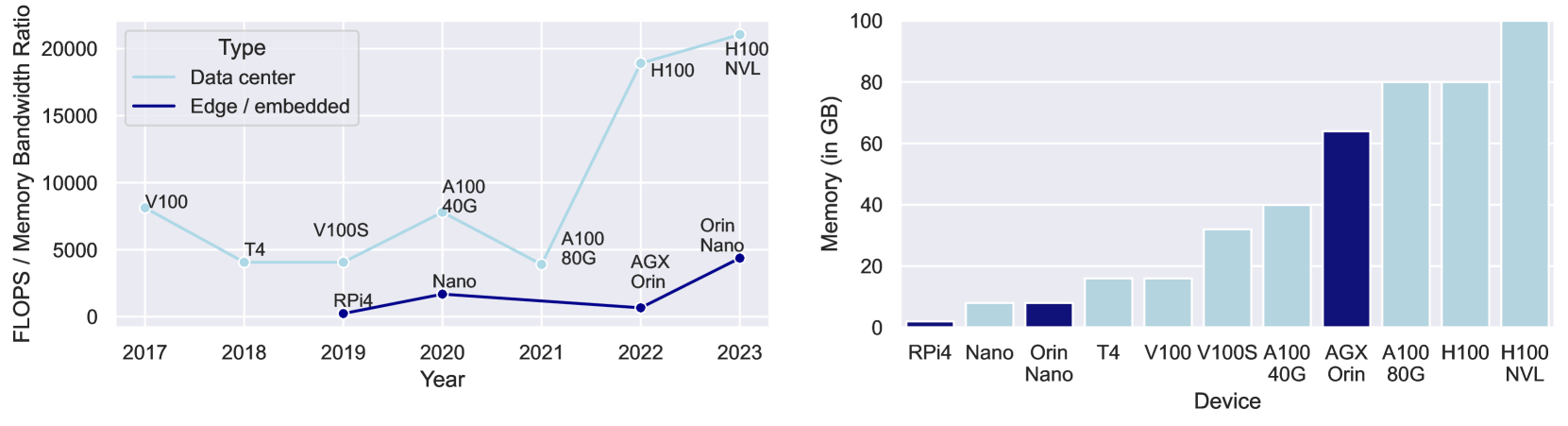
Federated Fine-Tuning of LLMs on the Very Edge: The Good, the Bad, the Ugly
Herbert Woisetschlager, Alexander Isenko, Shiqiang Wang, Ruben Mayer, Hans-Arno Jacobsen
0
0
Large Language Models (LLM) and foundation models are popular as they offer new opportunities for individuals and businesses to improve natural language processing, interact with data, and retrieve information faster. However, training or fine-tuning LLMs requires a vast amount of data, which can be challenging to access due to legal or technical restrictions and may require private computing resources. Federated Learning (FL) is a solution designed to overcome these challenges and expand data access for deep learning applications. This paper takes a hardware-centric approach to explore how LLMs can be brought to modern edge computing systems. Our study fine-tunes the FLAN-T5 model family, ranging from 80M to 3B parameters, using FL for a text summarization task. We provide a micro-level hardware benchmark, compare the model FLOP utilization to a state-of-the-art data center GPU, and study the network utilization in realistic conditions. Our contribution is twofold: First, we evaluate the current capabilities of edge computing systems and their potential for LLM FL workloads. Second, by comparing these systems with a data-center GPU, we demonstrate the potential for improvement and the next steps toward achieving greater computational efficiency at the edge.
5/3/2024