FedEval-LLM: Federated Evaluation of Large Language Models on Downstream Tasks with Collective Wisdom
2404.12273
0
0
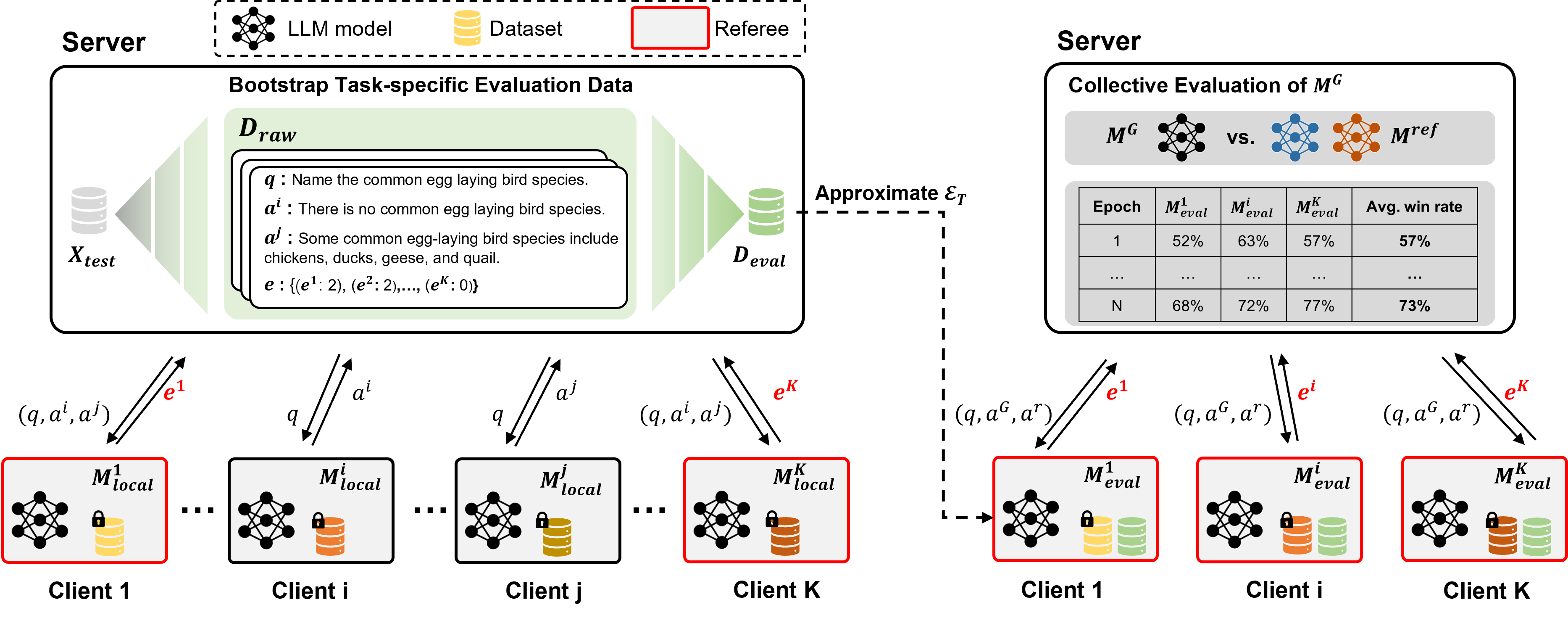
Abstract
Federated Learning (FL) has emerged as a promising solution for collaborative training of large language models (LLMs). However, the integration of LLMs into FL introduces new challenges, particularly concerning the evaluation of LLMs. Traditional evaluation methods that rely on labeled test sets and similarity-based metrics cover only a subset of the acceptable answers, thereby failing to accurately reflect the performance of LLMs on generative tasks. Meanwhile, although automatic evaluation methods that leverage advanced LLMs present potential, they face critical risks of data leakage due to the need to transmit data to external servers and suboptimal performance on downstream tasks due to the lack of domain knowledge. To address these issues, we propose a Federated Evaluation framework of Large Language Models, named FedEval-LLM, that provides reliable performance measurements of LLMs on downstream tasks without the reliance on labeled test sets and external tools, thus ensuring strong privacy-preserving capability. FedEval-LLM leverages a consortium of personalized LLMs from participants as referees to provide domain knowledge and collective evaluation capability, thus aligning to the respective downstream tasks and mitigating uncertainties and biases associated with a single referee. Experimental results demonstrate a significant improvement in the evaluation capability of personalized evaluation models on downstream tasks. When applied to FL, these evaluation models exhibit strong agreement with human preference and RougeL-score on meticulously curated test sets. FedEval-LLM effectively overcomes the limitations of traditional metrics and the reliance on external services, making it a promising framework for the evaluation of LLMs within collaborative training scenarios.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a new framework called FedEval-LLM for the federated evaluation of large language models (LLMs) on downstream tasks.
- The framework leverages the collective wisdom of a diverse set of stakeholders to provide a comprehensive evaluation of LLMs.
- It addresses challenges in the current evaluation of LLMs, such as the lack of representative datasets and the need for more inclusive and transparent evaluation processes.
Plain English Explanation
The paper describes a new approach called FedEval-LLM that aims to improve the way we evaluate large language models (LLMs) - advanced AI systems that can understand and generate human-like text.
Today, evaluating LLMs can be a challenge. The datasets used for testing often don't represent the full range of real-world applications and perspectives. And the evaluation process can lack input from diverse stakeholders, leading to potential biases.
The FedEval-LLM framework tries to address these issues. It brings together a wide range of people - including domain experts, end-users, and marginalized communities - to collectively assess how well LLMs perform on various tasks. This "collective wisdom" helps create a more comprehensive and inclusive evaluation.
The goal is to end up with a better understanding of the strengths, weaknesses, and potential societal impacts of these powerful language models. This information can then guide the development of LLMs that are more robust and beneficial for everyone.
Technical Explanation
The paper proposes the FedEval-LLM framework to enable a more comprehensive and inclusive evaluation of large language models (LLMs) on downstream tasks. The key elements of the framework include:
-
Federated Evaluation: FedEval-LLM leverages a federated learning approach, where multiple stakeholders (e.g., domain experts, end-users, marginalized communities) collaborate to evaluate LLMs. This helps capture diverse perspectives and use cases.
-
Collective Wisdom: The framework incorporates the "collective wisdom" of the stakeholders to inform the evaluation process. This includes identifying relevant tasks, defining appropriate evaluation metrics, and interpreting the results.
-
Modular Design: FedEval-LLM has a modular design, allowing for the integration of different evaluation components (e.g., datasets, benchmarks, assessment tools) to support a wide range of downstream applications.
-
Transparency and Reproducibility: The framework emphasizes transparency and reproducibility, with detailed documentation of the evaluation process and open-source tools for others to use and extend.
The paper discusses the potential benefits of FedEval-LLM, such as creating more representative and inclusive evaluation datasets, identifying biases and limitations in LLMs, and guiding the development of more ethical and trustworthy language models.
Critical Analysis
The FedEval-LLM framework proposed in the paper addresses several important challenges in the current evaluation of large language models (LLMs). By incorporating diverse stakeholder perspectives, the framework aims to create a more comprehensive and inclusive evaluation process.
However, the paper also acknowledges some potential limitations and areas for further research:
-
Scalability: Coordinating and engaging a large and diverse group of stakeholders in the evaluation process may present scalability challenges, particularly for widely used LLMs.
-
Incentive Alignment: Ensuring that all stakeholders have aligned incentives and a shared understanding of the evaluation goals may be difficult to achieve in practice.
-
Interpretability: The paper notes the need for developing interpretable evaluation metrics and techniques to help stakeholders understand the underlying behavior of LLMs.
-
Deployment Challenges: Transitioning the FedEval-LLM framework from a research prototype to a widely adopted evaluation approach may face practical hurdles, such as overcoming institutional inertia and aligning with existing evaluation practices.
These limitations and challenges highlight the need for further research and experimentation to refine and validate the FedEval-LLM approach. Addressing these issues could help strengthen the framework and increase its real-world impact in improving the evaluation and development of large language models.
Conclusion
The FedEval-LLM framework proposed in this paper represents a promising approach to addressing the limitations of current evaluation practices for large language models (LLMs). By leveraging the collective wisdom of diverse stakeholders, the framework aims to create a more comprehensive, inclusive, and transparent evaluation process.
The potential benefits of FedEval-LLM include the development of more representative evaluation datasets, the identification of biases and limitations in LLMs, and the guidance of ethical and trustworthy language model development. While the paper acknowledges some challenges, such as scalability and incentive alignment, the overall approach has the potential to significantly improve the evaluation and responsible development of these powerful AI systems.
As the use of LLMs continues to grow, frameworks like FedEval-LLM will become increasingly important in ensuring that these technologies are evaluated and deployed in a way that benefits society as a whole. The insights and methodologies presented in this paper can serve as a valuable foundation for further research and innovation in the field of AI evaluation and responsible development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
FedJudge: Federated Legal Large Language Model
Linan Yue, Qi Liu, Yichao Du, Weibo Gao, Ye Liu, Fangzhou Yao
0
0
Large Language Models (LLMs) have gained prominence in the field of Legal Intelligence, offering potential applications in assisting legal professionals and laymen. However, the centralized training of these Legal LLMs raises data privacy concerns, as legal data is distributed among various institutions containing sensitive individual information. This paper addresses this challenge by exploring the integration of Legal LLMs with Federated Learning (FL) methodologies. By employing FL, Legal LLMs can be fine-tuned locally on devices or clients, and their parameters are aggregated and distributed on a central server, ensuring data privacy without directly sharing raw data. However, computation and communication overheads hinder the full fine-tuning of LLMs under the FL setting. Moreover, the distribution shift of legal data reduces the effectiveness of FL methods. To this end, in this paper, we propose the first Federated Legal Large Language Model (FedJudge) framework, which fine-tunes Legal LLMs efficiently and effectively. Specifically, FedJudge utilizes parameter-efficient fine-tuning methods to update only a few additional parameters during the FL training. Besides, we explore the continual learning methods to preserve the global model's important parameters when training local clients to mitigate the problem of data shifts. Extensive experimental results on three real-world datasets clearly validate the effectiveness of FedJudge. Code is released at https://github.com/yuelinan/FedJudge.
4/11/2024
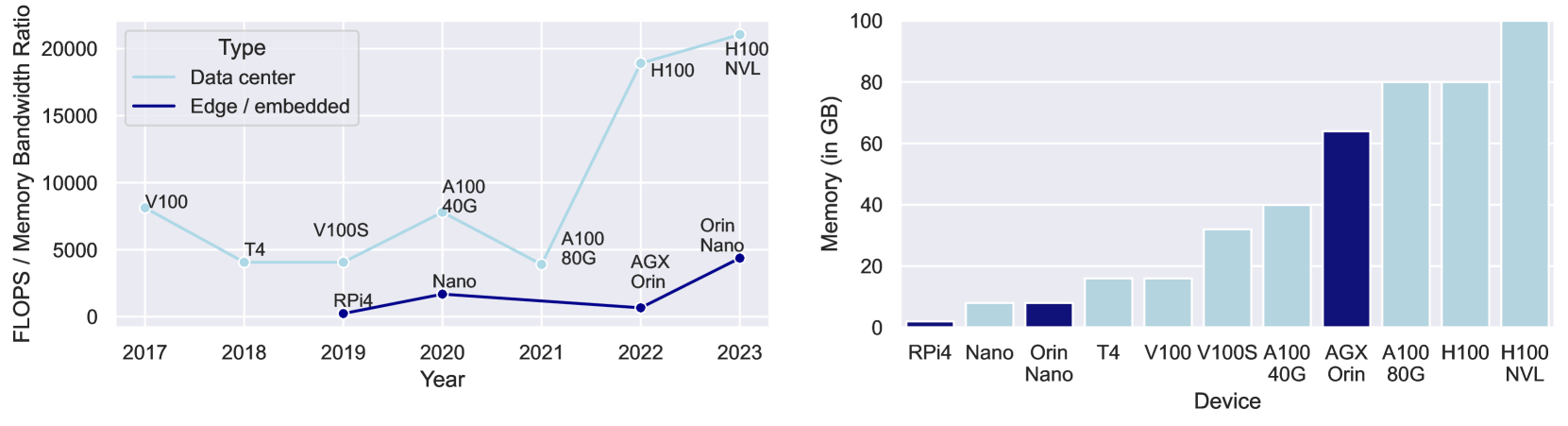
Federated Fine-Tuning of LLMs on the Very Edge: The Good, the Bad, the Ugly
Herbert Woisetschlager, Alexander Isenko, Shiqiang Wang, Ruben Mayer, Hans-Arno Jacobsen
0
0
Large Language Models (LLM) and foundation models are popular as they offer new opportunities for individuals and businesses to improve natural language processing, interact with data, and retrieve information faster. However, training or fine-tuning LLMs requires a vast amount of data, which can be challenging to access due to legal or technical restrictions and may require private computing resources. Federated Learning (FL) is a solution designed to overcome these challenges and expand data access for deep learning applications. This paper takes a hardware-centric approach to explore how LLMs can be brought to modern edge computing systems. Our study fine-tunes the FLAN-T5 model family, ranging from 80M to 3B parameters, using FL for a text summarization task. We provide a micro-level hardware benchmark, compare the model FLOP utilization to a state-of-the-art data center GPU, and study the network utilization in realistic conditions. Our contribution is twofold: First, we evaluate the current capabilities of edge computing systems and their potential for LLM FL workloads. Second, by comparing these systems with a data-center GPU, we demonstrate the potential for improvement and the next steps toward achieving greater computational efficiency at the edge.
5/3/2024
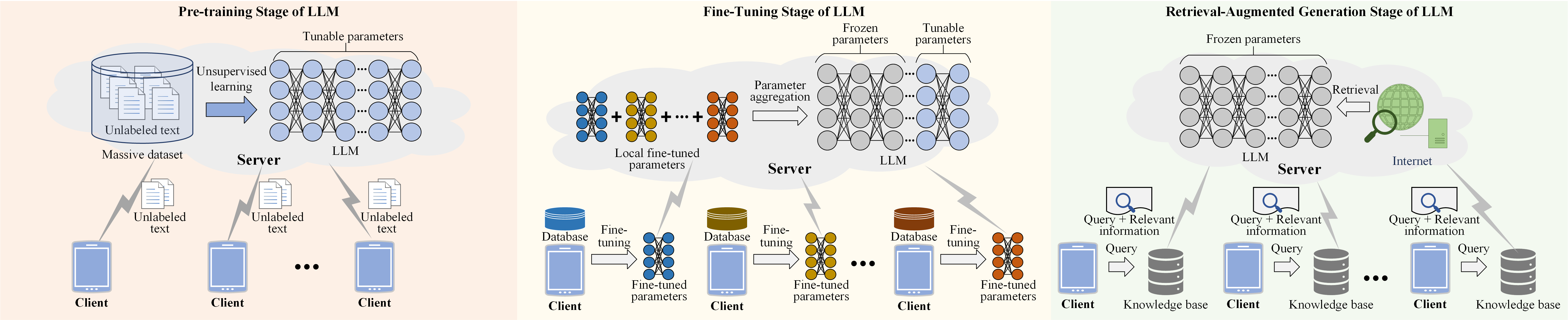
Personalized Wireless Federated Learning for Large Language Models
Feibo Jiang, Li Dong, Siwei Tu, Yubo Peng, Kezhi Wang, Kun Yang, Cunhua Pan, Dusit Niyato
0
0
Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their deployment in wireless networks still face challenges, i.e., a lack of privacy and security protection mechanisms. Federated Learning (FL) has emerged as a promising approach to address these challenges. Yet, it suffers from issues including inefficient handling with big and heterogeneous data, resource-intensive training, and high communication overhead. To tackle these issues, we first compare different learning stages and their features of LLMs in wireless networks. Next, we introduce two personalized wireless federated fine-tuning methods with low communication overhead, i.e., (1) Personalized Federated Instruction Tuning (PFIT), which employs reinforcement learning to fine-tune local LLMs with diverse reward models to achieve personalization; (2) Personalized Federated Task Tuning (PFTT), which can leverage global adapters and local Low-Rank Adaptations (LoRA) to collaboratively fine-tune local LLMs, where the local LoRAs can be applied to achieve personalization without aggregation. Finally, we perform simulations to demonstrate the effectiveness of the proposed two methods and comprehensively discuss open issues.
4/23/2024
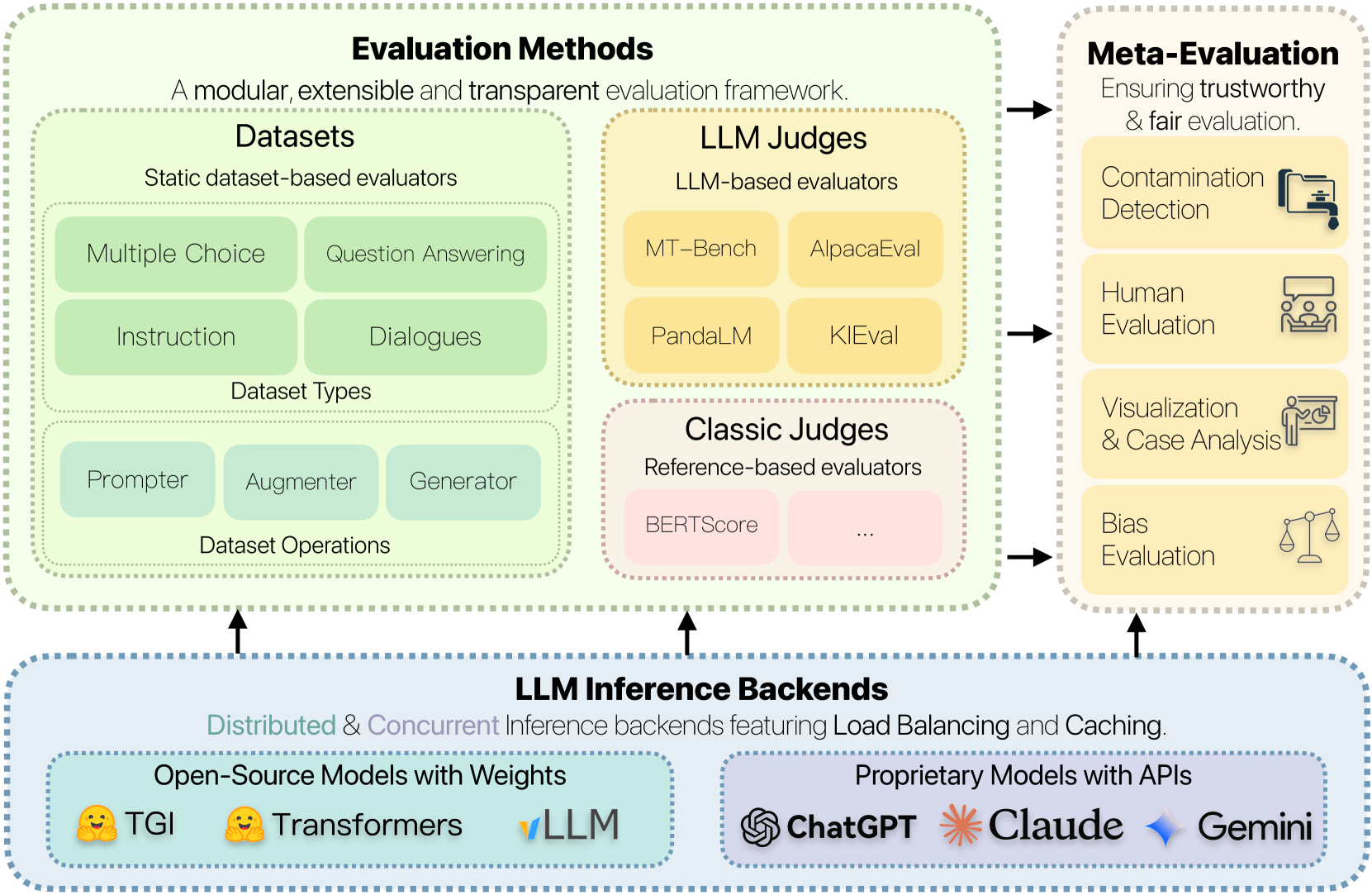
FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models
Zhuohao Yu, Chang Gao, Wenjin Yao, Yidong Wang, Zhengran Zeng, Wei Ye, Jindong Wang, Yue Zhang, Shikun Zhang
0
0
The rapid development of large language model (LLM) evaluation methodologies and datasets has led to a profound challenge: integrating state-of-the-art evaluation techniques cost-effectively while ensuring reliability, reproducibility, and efficiency. Currently, there is a notable absence of a unified and adaptable framework that seamlessly integrates various evaluation approaches. Moreover, the reliability of evaluation findings is often questionable due to potential data contamination, with the evaluation efficiency commonly overlooked when facing the substantial costs associated with LLM inference. In response to these challenges, we introduce FreeEval, a modular and scalable framework crafted to enable trustworthy and efficient automatic evaluations of LLMs. Firstly, FreeEval's unified abstractions simplify the integration and improve the transparency of diverse evaluation methodologies, encompassing dynamic evaluation that demand sophisticated LLM interactions. Secondly, the framework integrates meta-evaluation techniques like human evaluation and data contamination detection, which, along with dynamic evaluation modules in the platform, enhance the fairness of the evaluation outcomes. Lastly, FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies, enabling extensive evaluations across multi-node, multi-GPU clusters for open-source and proprietary LLMs.
4/10/2024