FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models
2404.06003
0
0
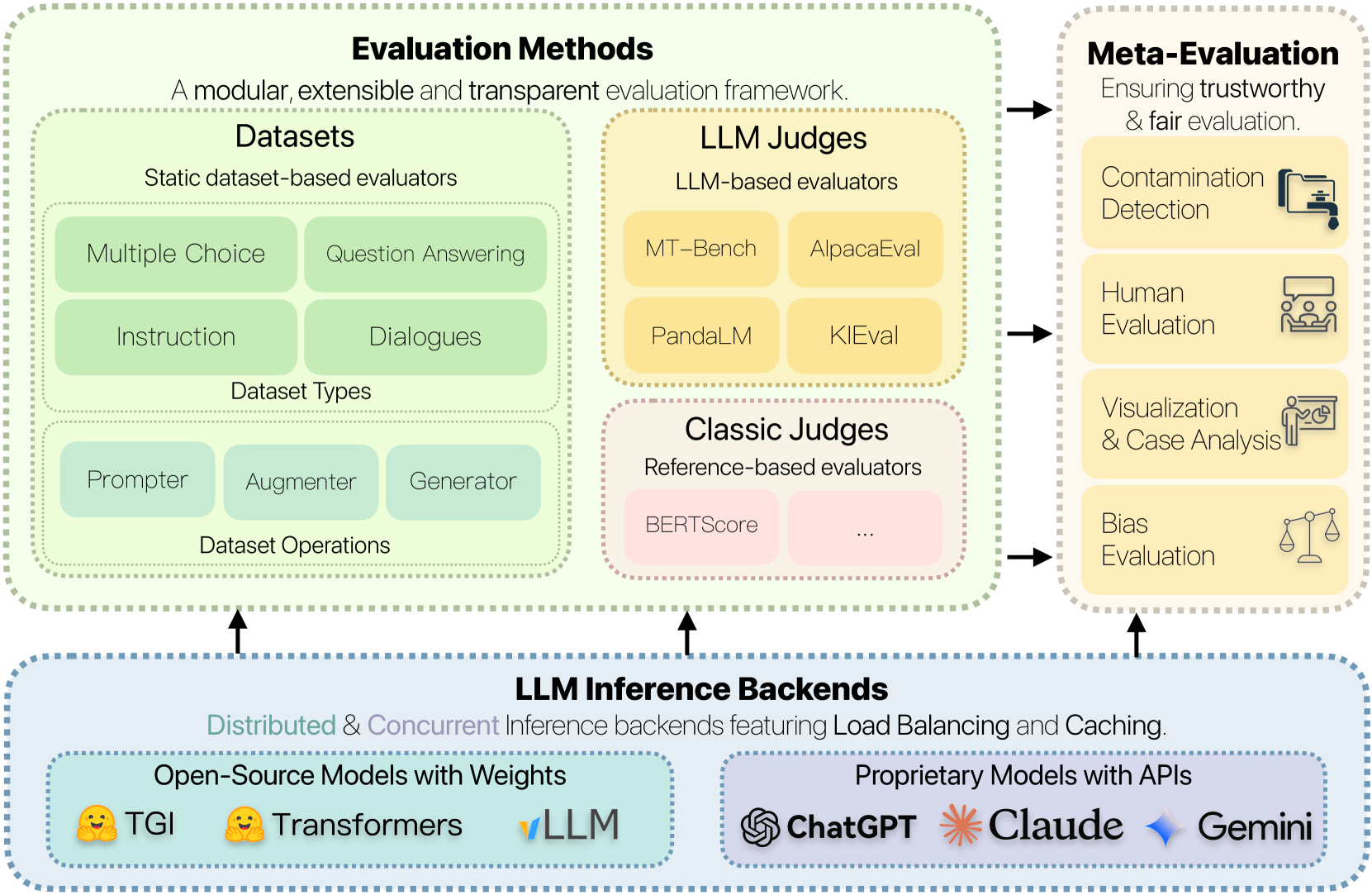
Abstract
The rapid development of large language model (LLM) evaluation methodologies and datasets has led to a profound challenge: integrating state-of-the-art evaluation techniques cost-effectively while ensuring reliability, reproducibility, and efficiency. Currently, there is a notable absence of a unified and adaptable framework that seamlessly integrates various evaluation approaches. Moreover, the reliability of evaluation findings is often questionable due to potential data contamination, with the evaluation efficiency commonly overlooked when facing the substantial costs associated with LLM inference. In response to these challenges, we introduce FreeEval, a modular and scalable framework crafted to enable trustworthy and efficient automatic evaluations of LLMs. Firstly, FreeEval's unified abstractions simplify the integration and improve the transparency of diverse evaluation methodologies, encompassing dynamic evaluation that demand sophisticated LLM interactions. Secondly, the framework integrates meta-evaluation techniques like human evaluation and data contamination detection, which, along with dynamic evaluation modules in the platform, enhance the fairness of the evaluation outcomes. Lastly, FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies, enabling extensive evaluations across multi-node, multi-GPU clusters for open-source and proprietary LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposes a new framework called FreeEval for efficiently and trustworthily evaluating large language models (LLMs)
- Aims to address limitations of existing evaluation methods and provide a more modular and scalable approach
- Introduces key concepts like task-specific prompts, crowdsourced evaluations, and automated baseline comparisons
Plain English Explanation
FreeEval is a new system designed to help researchers and developers better understand the capabilities of large language models (LLMs) like GPT-3 or BERT. LLMs are powerful AI systems that can generate human-like text, answer questions, and perform various other language-related tasks. However, accurately evaluating their abilities can be quite challenging.
The researchers behind FreeEval recognized that existing evaluation methods often have limitations, such as being time-consuming, expensive, or not comprehensive enough. FreeEval aims to address these issues by providing a more modular and scalable framework.
The key ideas in FreeEval include:
- Using task-specific prompts to test LLMs on a wide range of language tasks
- Relying on crowdsourced human evaluations to get trustworthy assessments of model performance
- Automating the process of comparing model results to established baselines
By combining these elements, FreeEval allows for efficient and thorough evaluations of LLMs that can provide valuable insights to researchers and developers. This could lead to the creation of more capable and reliable language AI systems in the future.
Technical Explanation
FreeEval is a new framework proposed by the authors to address limitations in the evaluation of large language models (LLMs). Existing methods, such as those used in METAL, S3EVal, RealHumanEval, and CodeEditorBench, can be time-consuming, expensive, or lack the necessary flexibility and scalability.
FreeEval aims to provide a more modular and efficient evaluation framework. Key elements include:
-
Task-Specific Prompts: FreeEval uses a diverse set of task-specific prompts to test LLMs on a wide range of language-related capabilities, from open-ended text generation to specialized tasks like code editing.
-
Crowdsourced Evaluations: The framework relies on crowdsourced human evaluations to assess the quality and correctness of model outputs, ensuring trustworthy assessments of LLM performance.
-
Automated Baseline Comparisons: FreeEval automates the process of comparing model results to established baselines, streamlining the evaluation process and enabling scalable benchmarking.
By combining these elements, FreeEval aims to enable more comprehensive, efficient, and trustworthy evaluations of LLMs, ultimately leading to the development of more capable and reliable language AI systems.
Critical Analysis
The FreeEval framework presented in the paper addresses several important limitations of existing LLM evaluation methods. By incorporating task-specific prompts, crowdsourced evaluations, and automated baseline comparisons, the authors have designed a more flexible and scalable approach.
However, the paper does not delve deeply into the potential challenges or limitations of the FreeEval framework itself. For example, the reliance on crowdsourced evaluations raises questions about the consistency and reliability of human assessments, especially for more subjective language tasks. Additionally, the automated baseline comparisons may be susceptible to bias if the chosen baselines do not accurately reflect the state-of-the-art in LLM performance.
Further research is needed to explore the long-term viability and real-world applicability of the FreeEval framework. Potential areas for improvement include developing more sophisticated methods for ensuring the quality and reliability of crowdsourced evaluations, as well as investigating ways to make the baseline comparisons more robust and representative of the broader LLM landscape.
Conclusion
FreeEval is a promising new framework that aims to address the limitations of existing methods for evaluating large language models (LLMs). By incorporating task-specific prompts, crowdsourced evaluations, and automated baseline comparisons, the authors have designed a more flexible, scalable, and trustworthy approach to assessing LLM capabilities.
The potential impact of FreeEval is significant, as it could lead to the development of more capable and reliable language AI systems. However, further research is needed to explore the long-term viability and real-world applicability of the framework, particularly in addressing potential challenges related to crowdsourced evaluations and baseline comparisons.
Overall, the FreeEval paper represents a valuable contribution to the ongoing efforts to improve the evaluation and understanding of large language models, which play a crucial role in the advancement of natural language processing and artificial intelligence.
Related Papers
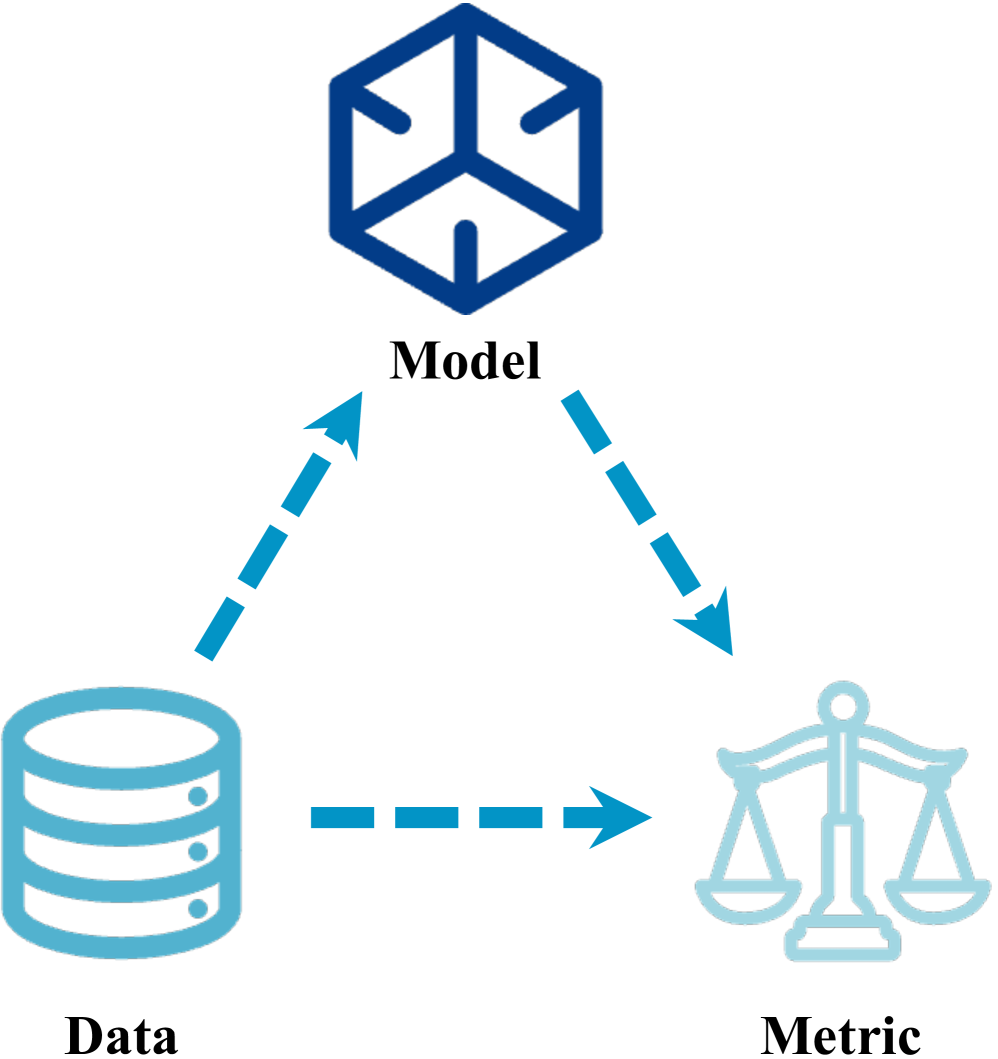
UltraEval: A Lightweight Platform for Flexible and Comprehensive Evaluation for LLMs
Chaoqun He, Renjie Luo, Shengding Hu, Yuanqian Zhao, Jie Zhou, Hanghao Wu, Jiajie Zhang, Xu Han, Zhiyuan Liu, Maosong Sun
0
0
Evaluation is pivotal for honing Large Language Models (LLMs), pinpointing their capabilities and guiding enhancements. The rapid development of LLMs calls for a lightweight and easy-to-use framework for swift evaluation deployment. However, due to the various implementation details to consider, developing a comprehensive evaluation platform is never easy. Existing platforms are often complex and poorly modularized, hindering seamless incorporation into researcher's workflows. This paper introduces UltraEval, a user-friendly evaluation framework characterized by lightweight, comprehensiveness, modularity, and efficiency. We identify and reimplement three core components of model evaluation (models, data, and metrics). The resulting composability allows for the free combination of different models, tasks, prompts, and metrics within a unified evaluation workflow. Additionally, UltraEval supports diverse models owing to a unified HTTP service and provides sufficient inference acceleration. UltraEval is now available for researchers publicly~footnote{Website is at url{https://github.com/OpenBMB/UltraEval}}.
4/12/2024
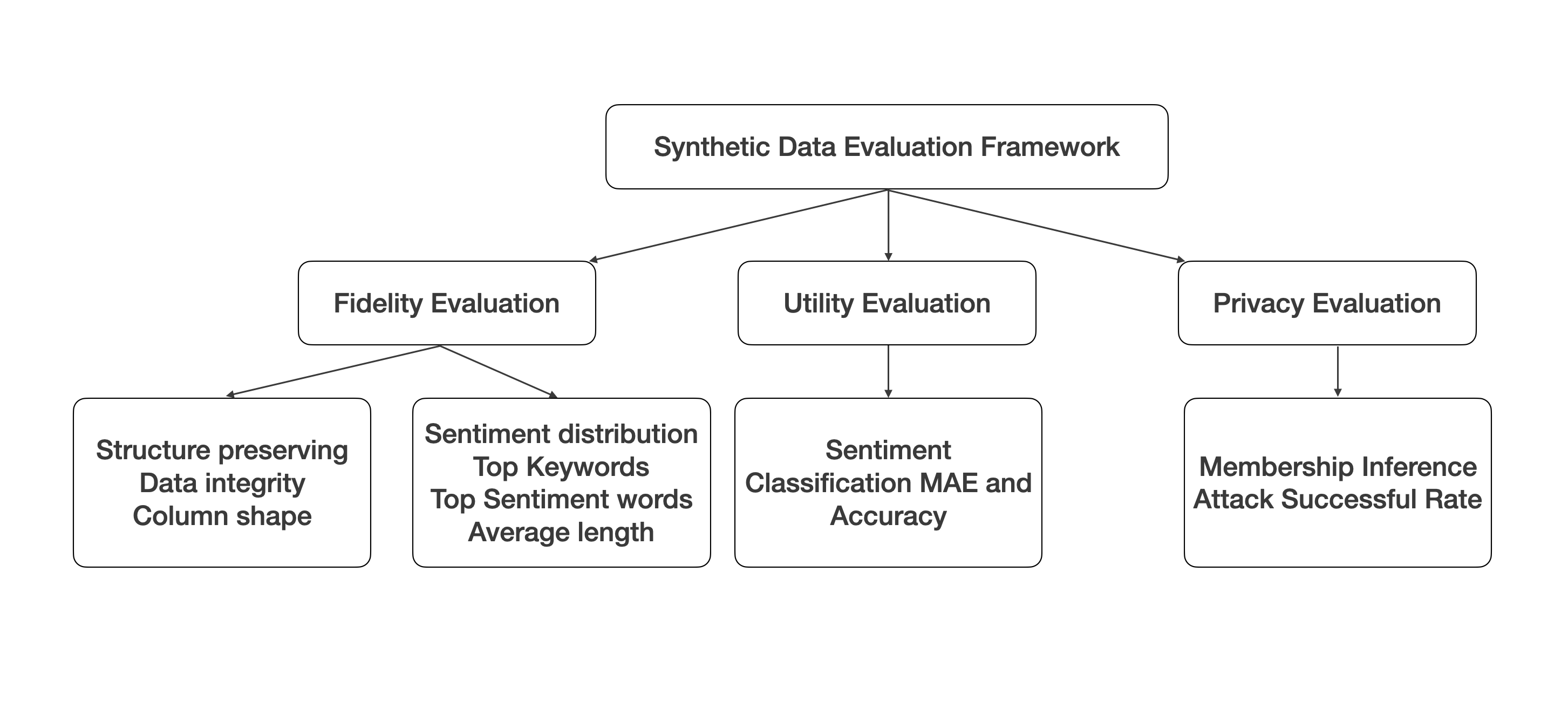
A Multi-Faceted Evaluation Framework for Assessing Synthetic Data Generated by Large Language Models
Yefeng Yuan, Yuhong Liu, Liang Cheng
0
0
The rapid advancements in generative AI and large language models (LLMs) have opened up new avenues for producing synthetic data, particularly in the realm of structured tabular formats, such as product reviews. Despite the potential benefits, concerns regarding privacy leakage have surfaced, especially when personal information is utilized in the training datasets. In addition, there is an absence of a comprehensive evaluation framework capable of quantitatively measuring the quality of the generated synthetic data and their utility for downstream tasks. In response to this gap, we introduce SynEval, an open-source evaluation framework designed to assess the fidelity, utility, and privacy preservation of synthetically generated tabular data via a suite of diverse evaluation metrics. We validate the efficacy of our proposed framework - SynEval - by applying it to synthetic product review data generated by three state-of-the-art LLMs: ChatGPT, Claude, and Llama. Our experimental findings illuminate the trade-offs between various evaluation metrics in the context of synthetic data generation. Furthermore, SynEval stands as a critical instrument for researchers and practitioners engaged with synthetic tabular data,, empowering them to judiciously determine the suitability of the generated data for their specific applications, with an emphasis on upholding user privacy.
4/24/2024
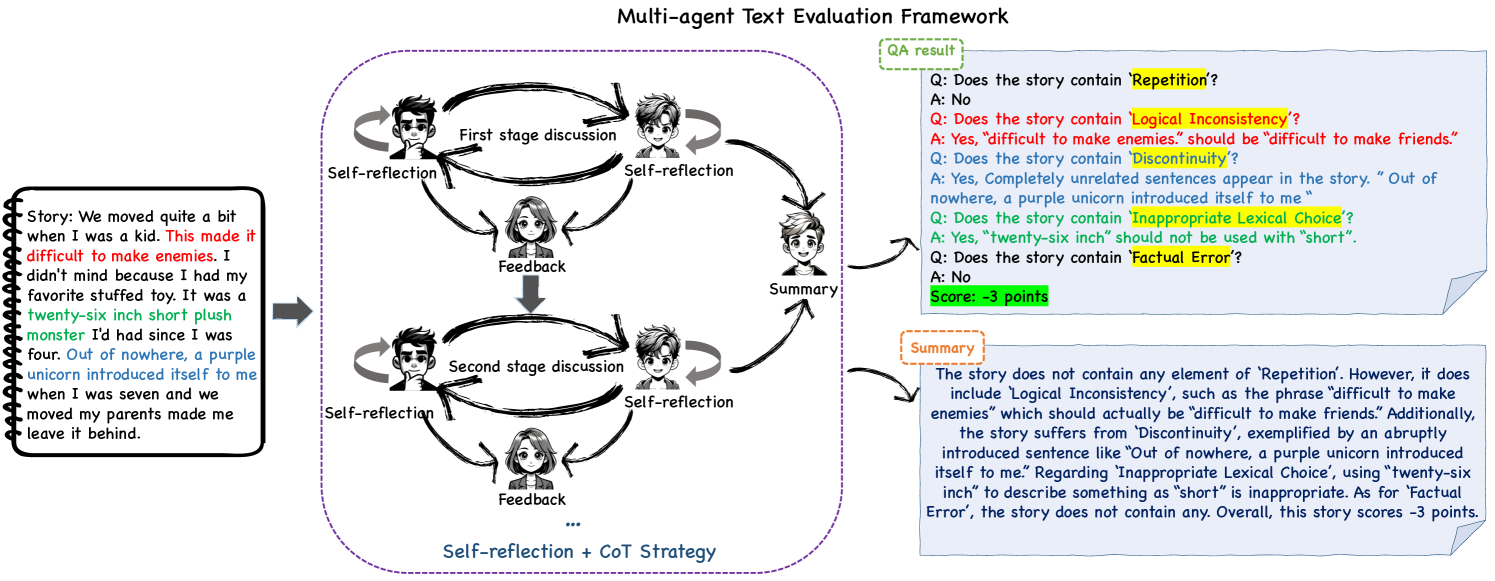
MATEval: A Multi-Agent Discussion Framework for Advancing Open-Ended Text Evaluation
Yu Li, Shenyu Zhang, Rui Wu, Xiutian Huang, Yongrui Chen, Wenhao Xu, Guilin Qi, Dehai Min
0
0
Recent advancements in generative Large Language Models(LLMs) have been remarkable, however, the quality of the text generated by these models often reveals persistent issues. Evaluating the quality of text generated by these models, especially in open-ended text, has consistently presented a significant challenge. Addressing this, recent work has explored the possibility of using LLMs as evaluators. While using a single LLM as an evaluation agent shows potential, it is filled with significant uncertainty and instability. To address these issues, we propose the MATEval: A Multi-Agent Text Evaluation framework where all agents are played by LLMs like GPT-4. The MATEval framework emulates human collaborative discussion methods, integrating multiple agents' interactions to evaluate open-ended text. Our framework incorporates self-reflection and Chain-of-Thought (CoT) strategies, along with feedback mechanisms, enhancing the depth and breadth of the evaluation process and guiding discussions towards consensus, while the framework generates comprehensive evaluation reports, including error localization, error types and scoring. Experimental results show that our framework outperforms existing open-ended text evaluation methods and achieves the highest correlation with human evaluation, which confirms the effectiveness and advancement of our framework in addressing the uncertainties and instabilities in evaluating LLMs-generated text. Furthermore, our framework significantly improves the efficiency of text evaluation and model iteration in industrial scenarios.
4/16/2024
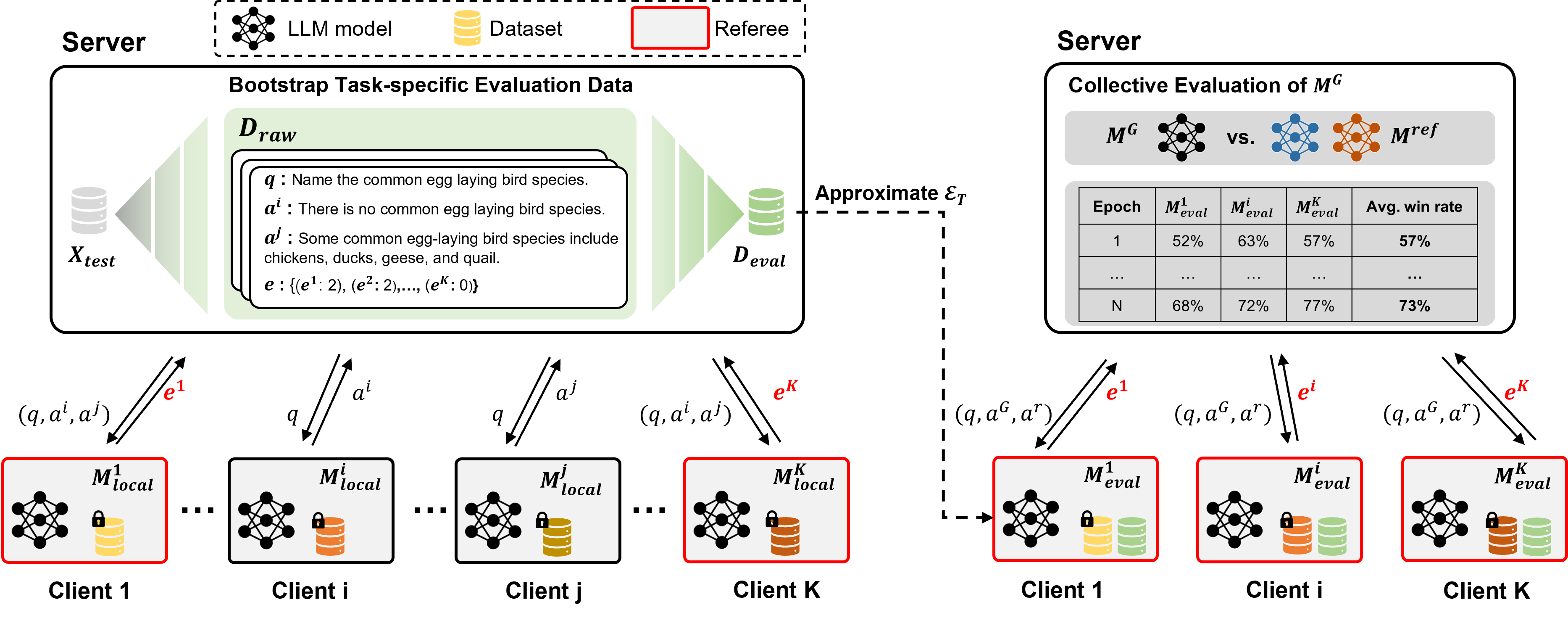
FedEval-LLM: Federated Evaluation of Large Language Models on Downstream Tasks with Collective Wisdom
Yuanqin He, Yan Kang, Lixin Fan, Qiang Yang
0
0
Federated Learning (FL) has emerged as a promising solution for collaborative training of large language models (LLMs). However, the integration of LLMs into FL introduces new challenges, particularly concerning the evaluation of LLMs. Traditional evaluation methods that rely on labeled test sets and similarity-based metrics cover only a subset of the acceptable answers, thereby failing to accurately reflect the performance of LLMs on generative tasks. Meanwhile, although automatic evaluation methods that leverage advanced LLMs present potential, they face critical risks of data leakage due to the need to transmit data to external servers and suboptimal performance on downstream tasks due to the lack of domain knowledge. To address these issues, we propose a Federated Evaluation framework of Large Language Models, named FedEval-LLM, that provides reliable performance measurements of LLMs on downstream tasks without the reliance on labeled test sets and external tools, thus ensuring strong privacy-preserving capability. FedEval-LLM leverages a consortium of personalized LLMs from participants as referees to provide domain knowledge and collective evaluation capability, thus aligning to the respective downstream tasks and mitigating uncertainties and biases associated with a single referee. Experimental results demonstrate a significant improvement in the evaluation capability of personalized evaluation models on downstream tasks. When applied to FL, these evaluation models exhibit strong agreement with human preference and RougeL-score on meticulously curated test sets. FedEval-LLM effectively overcomes the limitations of traditional metrics and the reliance on external services, making it a promising framework for the evaluation of LLMs within collaborative training scenarios.
4/19/2024