Few-Shot Class Incremental Learning with Attention-Aware Self-Adaptive Prompt

0
❗
Sign in to get full access
Overview
- This paper presents a template for citing AI research papers in a standardized format called "PRIME AI Style Citation."
- The template includes key information such as the authors, title, page numbers, and digital object identifier (DOI) of the paper.
- The paper was generated using LaTeXML, a tool for converting LaTeX documents to HTML.
Plain English Explanation
The provided paper is a template for how to properly cite AI research papers in a standardized format. This is important for researchers and readers to quickly identify key details about a paper, such as who wrote it, what it's called, how many pages it is, and where it can be found online.
The template includes fields for listing the authors, the title, the page numbers, and the digital object identifier (DOI) - a unique code that identifies the paper's online location. Using a consistent format like this makes it easier to keep track of and find relevant AI research.
The paper itself was created using a tool called LaTeXML, which can convert documents written in the LaTeX markup language into web-friendly HTML format. This allows the template to be shared and accessed online.
Technical Explanation
The provided document is a template for citing AI research papers in a standardized "PRIME AI Style Citation" format. It includes the following key elements:
- Authors: The names of the paper's authors are listed.
- Title: The title of the research paper is provided.
- Pages: The page numbers for the paper are specified.
- DOI: The digital object identifier, a unique code that identifies the paper's online location, is included.
The template was generated using LaTeXML, a tool for converting LaTeX documents, a common markup language used in academic publishing, into HTML format for web display.
Critical Analysis
The provided template offers a clear and standardized way to cite AI research papers, which can be helpful for researchers, readers, and others working in the field. By including key metadata like author names, title, page numbers, and DOI, the template makes it easier to track down and reference specific papers.
However, the template itself does not provide any insights or analysis of the research. It is simply a formatting structure. Additional context about the significance, methodology, or findings of the cited papers would be needed to fully evaluate their contribution to the field.
Furthermore, the use of this particular citation style, "PRIME AI Style Citation," is not widely adopted yet. There may be other more commonly used citation formats that researchers would need to be aware of as well.
Conclusion
The provided paper offers a template for consistently citing AI research papers in a standardized "PRIME AI Style Citation" format. This can help organize and track the growing body of work in the field. By including key metadata like author names, title, page numbers, and DOI, the template makes it easier to locate and reference specific papers.
While the template itself does not analyze the research, it provides a useful framework for clearly communicating essential details about AI publications. As the field continues to evolve, establishing consistent citation practices can improve discoverability and collaboration among researchers and readers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
Few-Shot Class Incremental Learning with Attention-Aware Self-Adaptive Prompt
Chenxi Liu, Zhenyi Wang, Tianyi Xiong, Ruibo Chen, Yihan Wu, Junfeng Guo, Heng Huang
Few-Shot Class-Incremental Learning (FSCIL) models aim to incrementally learn new classes with scarce samples while preserving knowledge of old ones. Existing FSCIL methods usually fine-tune the entire backbone, leading to overfitting and hindering the potential to learn new classes. On the other hand, recent prompt-based CIL approaches alleviate forgetting by training prompts with sufficient data in each task. In this work, we propose a novel framework named Attention-aware Self-adaptive Prompt (ASP). ASP encourages task-invariant prompts to capture shared knowledge by reducing specific information from the attention aspect. Additionally, self-adaptive task-specific prompts in ASP provide specific information and transfer knowledge from old classes to new classes with an Information Bottleneck learning objective. In summary, ASP prevents overfitting on base task and does not require enormous data in few-shot incremental tasks. Extensive experiments on three benchmark datasets validate that ASP consistently outperforms state-of-the-art FSCIL and prompt-based CIL methods in terms of both learning new classes and mitigating forgetting.
Read more7/18/2024

0
New!Knowledge Adaptation Network for Few-Shot Class-Incremental Learning
Ye Wang, Yaxiong Wang, Guoshuai Zhao, Xueming Qian
Few-shot class-incremental learning (FSCIL) aims to incrementally recognize new classes using a few samples while maintaining the performance on previously learned classes. One of the effective methods to solve this challenge is to construct prototypical evolution classifiers. Despite the advancement achieved by most existing methods, the classifier weights are simply initialized using mean features. Because representations for new classes are weak and biased, we argue such a strategy is suboptimal. In this paper, we tackle this issue from two aspects. Firstly, thanks to the development of foundation models, we employ a foundation model, the CLIP, as the network pedestal to provide a general representation for each class. Secondly, to generate a more reliable and comprehensive instance representation, we propose a Knowledge Adapter (KA) module that summarizes the data-specific knowledge from training data and fuses it into the general representation. Additionally, to tune the knowledge learned from the base classes to the upcoming classes, we propose a mechanism of Incremental Pseudo Episode Learning (IPEL) by simulating the actual FSCIL. Taken together, our proposed method, dubbed as Knowledge Adaptation Network (KANet), achieves competitive performance on a wide range of datasets, including CIFAR100, CUB200, and ImageNet-R.
Read more9/19/2024
0
Learning Prompt with Distribution-Based Feature Replay for Few-Shot Class-Incremental Learning
Zitong Huang, Ze Chen, Zhixing Chen, Erjin Zhou, Xinxing Xu, Rick Siow Mong Goh, Yong Liu, Wangmeng Zuo, Chunmei Feng
Few-shot Class-Incremental Learning (FSCIL) aims to continuously learn new classes based on very limited training data without forgetting the old ones encountered. Existing studies solely relied on pure visual networks, while in this paper we solved FSCIL by leveraging the Vision-Language model (e.g., CLIP) and propose a simple yet effective framework, named Learning Prompt with Distribution-based Feature Replay (LP-DiF). We observe that simply using CLIP for zero-shot evaluation can substantially outperform the most influential methods. Then, prompt tuning technique is involved to further improve its adaptation ability, allowing the model to continually capture specific knowledge from each session. To prevent the learnable prompt from forgetting old knowledge in the new session, we propose a pseudo-feature replay approach. Specifically, we preserve the old knowledge of each class by maintaining a feature-level Gaussian distribution with a diagonal covariance matrix, which is estimated by the image features of training images and synthesized features generated from a VAE. When progressing to a new session, pseudo-features are sampled from old-class distributions combined with training images of the current session to optimize the prompt, thus enabling the model to learn new knowledge while retaining old knowledge. Experiments on three prevalent benchmarks, i.e., CIFAR100, mini-ImageNet, CUB-200, and two more challenging benchmarks, i.e., SUN-397 and CUB-200$^*$ proposed in this paper showcase the superiority of LP-DiF, achieving new state-of-the-art (SOTA) in FSCIL. Code is publicly available at https://github.com/1170300714/LP-DiF.
Read more4/8/2024
0
Few Shot Class Incremental Learning using Vision-Language models
Anurag Kumar, Chinmay Bharti, Saikat Dutta, Srikrishna Karanam, Biplab Banerjee
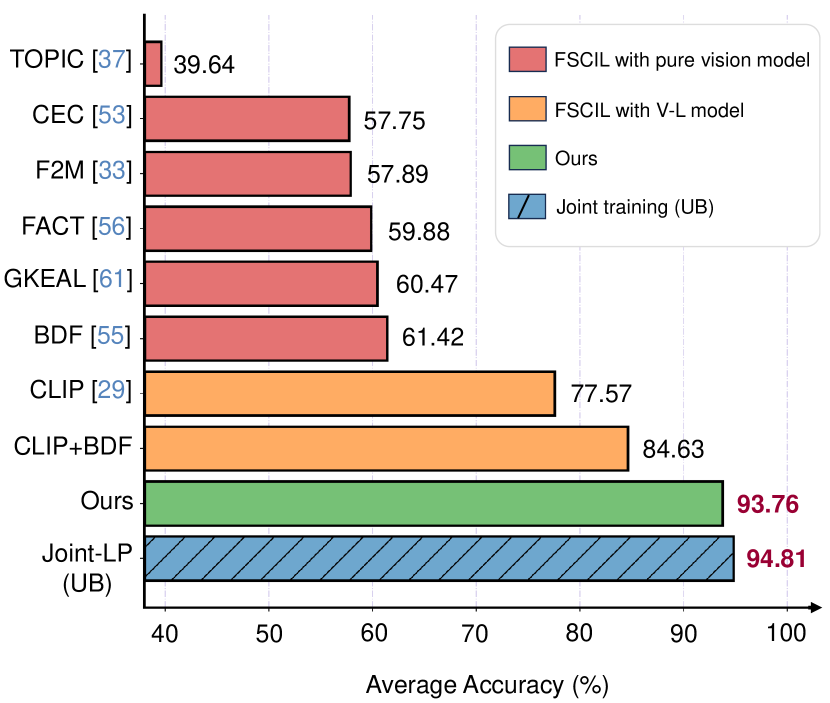
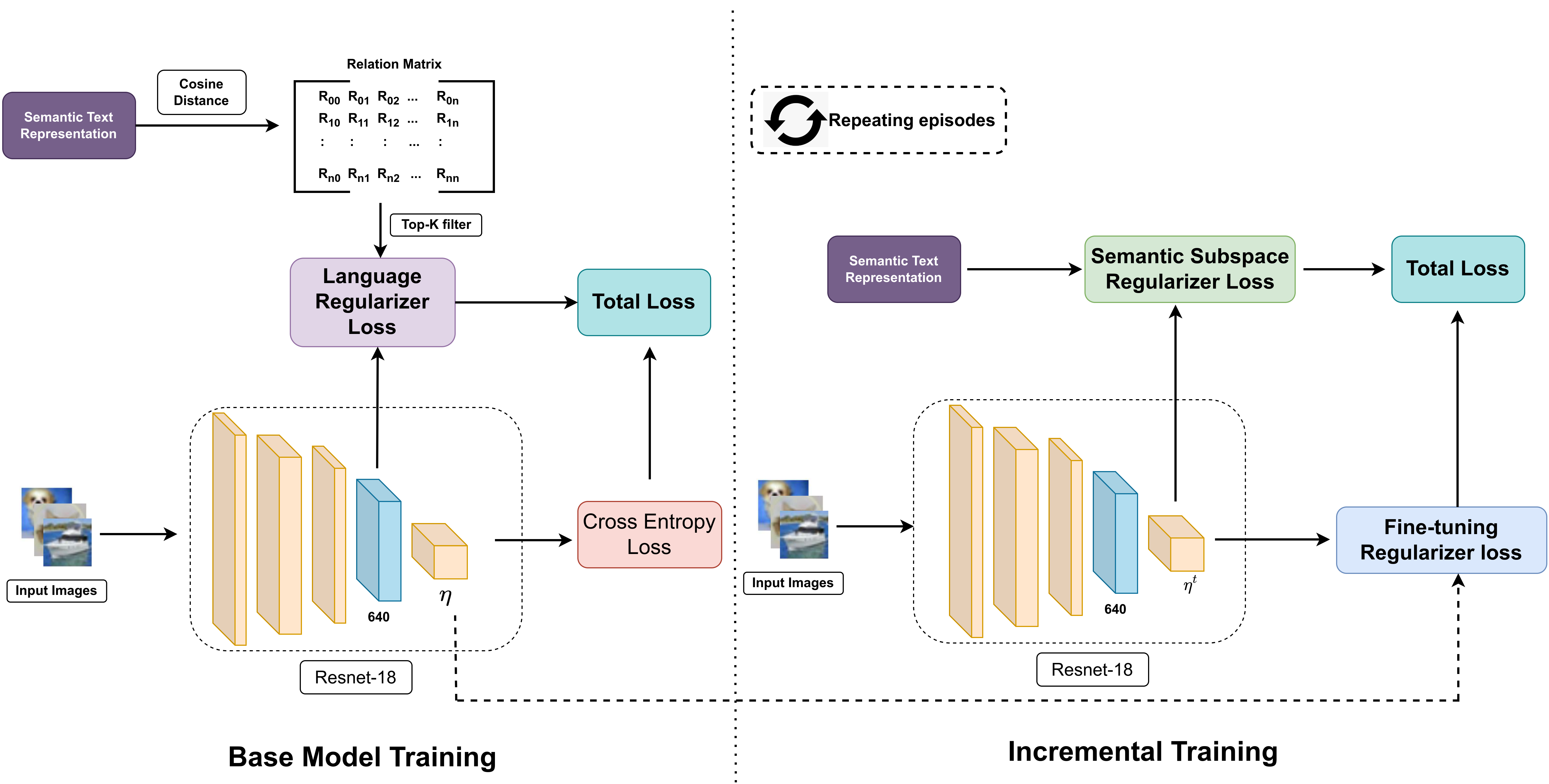
Recent advancements in deep learning have demonstrated remarkable performance comparable to human capabilities across various supervised computer vision tasks. However, the prevalent assumption of having an extensive pool of training data encompassing all classes prior to model training often diverges from real-world scenarios, where limited data availability for novel classes is the norm. The challenge emerges in seamlessly integrating new classes with few samples into the training data, demanding the model to adeptly accommodate these additions without compromising its performance on base classes. To address this exigency, the research community has introduced several solutions under the realm of few-shot class incremental learning (FSCIL). In this study, we introduce an innovative FSCIL framework that utilizes language regularizer and subspace regularizer. During base training, the language regularizer helps incorporate semantic information extracted from a Vision-Language model. The subspace regularizer helps in facilitating the model's acquisition of nuanced connections between image and text semantics inherent to base classes during incremental training. Our proposed framework not only empowers the model to embrace novel classes with limited data, but also ensures the preservation of performance on base classes. To substantiate the efficacy of our approach, we conduct comprehensive experiments on three distinct FSCIL benchmarks, where our framework attains state-of-the-art performance.
Read more8/16/2024