Few-Shot Medical Image Segmentation with Large Kernel Attention

0

Sign in to get full access
Overview
- Introduces a new method for few-shot medical image segmentation using large kernel attention
- Proposes a novel architecture called Large Kernel Attention Network (LKANet) that outperforms existing few-shot segmentation models
- Demonstrates the effectiveness of LKANet on multiple medical imaging datasets
Plain English Explanation
This paper presents a new approach for few-shot medical image segmentation called the Large Kernel Attention Network (LKANet). The key idea is to use large kernel attention, which allows the model to focus on relevant features across a wider spatial area of the input image.
Typically, medical image segmentation models struggle when there are only a few training examples available. LKANet aims to address this challenge by leveraging large kernel attention, which helps the model better understand the contextual relationships in the image. This is important for medical images, which often have complex, high-resolution structures that require considering a broader spatial context.
The paper demonstrates that LKANet outperforms existing few-shot segmentation models on multiple medical imaging datasets. This suggests that the large kernel attention mechanism can effectively capture the necessary information to accurately segment medical images, even when limited training data is available.
Technical Explanation
The authors propose the Large Kernel Attention Network (LKANet), a novel architecture for few-shot medical image segmentation. LKANet uses a large kernel attention module that allows the model to attend to relevant features across a wider spatial area of the input image.
The key components of LKANet include:
- Encoder-Decoder Architecture: LKANet uses a typical encoder-decoder structure with skip connections, similar to a U-Net.
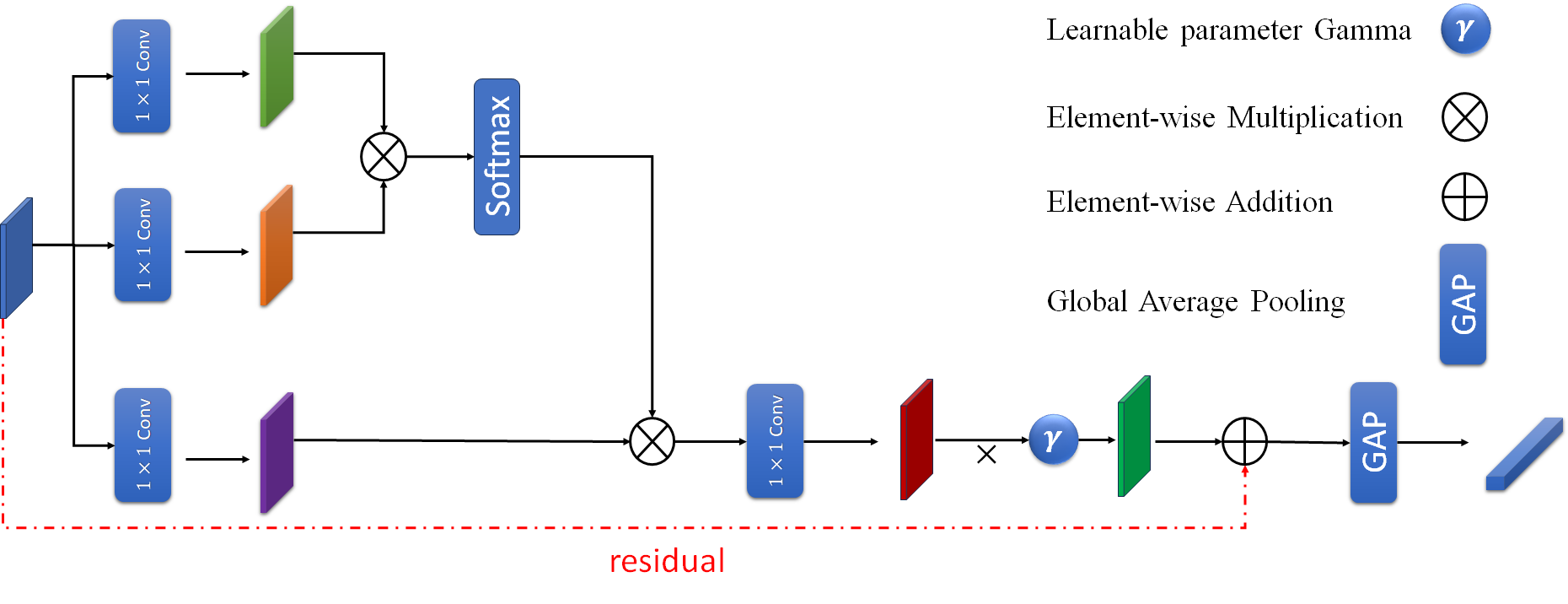
- Large Kernel Attention Module: This module employs large convolutional kernels (e.g., 7x7) to capture broader contextual information, unlike standard attention mechanisms that use smaller kernels.
- Prototype Fusion: LKANet fuses the feature representations of the support and query images using a prototype-based approach, which has been shown effective for few-shot learning.
The authors evaluate LKANet on several medical image segmentation datasets, including CT lung segmentation, retinal vessel segmentation, and heart segmentation. They demonstrate that LKANet outperforms existing few-shot segmentation models, highlighting the benefits of the large kernel attention mechanism for medical image understanding.
Critical Analysis
The paper presents a compelling approach to address the challenge of few-shot medical image segmentation. The authors provide a thorough evaluation, demonstrating the effectiveness of LKANet across multiple medical imaging datasets.
However, the paper does not discuss the potential limitations or caveats of the proposed method. For example, it is unclear how LKANet would perform on more diverse or complex medical imaging tasks, or whether the large kernel attention module introduces significant computational overhead.
Additionally, the paper could have explored the trade-offs between the size of the attention kernels and the model's performance. Investigating the optimal kernel size for different medical imaging applications could provide valuable insights for practitioners.
Further research could also examine the interpretability of the large kernel attention mechanism and how it contributes to the model's decision-making process. Understanding the underlying reasoning behind LKANet's predictions could lead to improved trust and adoption in clinical settings.
Conclusion
This paper introduces the Large Kernel Attention Network (LKANet), a novel architecture for few-shot medical image segmentation. LKANet leverages large kernel attention to capture broader contextual information, which helps the model perform well even with limited training data.
The authors demonstrate the effectiveness of LKANet on several medical imaging datasets, showcasing its potential to address the challenges of few-shot segmentation. While the paper provides a strong technical foundation, further research is needed to explore the limitations, trade-offs, and interpretability of the proposed approach.
Overall, this work represents an important step forward in the field of few-shot medical image segmentation, and the insights gained from this study can inform the development of more robust and reliable medical imaging AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Few-Shot Medical Image Segmentation with Large Kernel Attention
Xiaoxiao Wu, Xiaowei Chen, Zhenguo Gao, Shulei Qu, Yuanyuan Qiu
Medical image segmentation has witnessed significant advancements with the emergence of deep learning. However, the reliance of most neural network models on a substantial amount of annotated data remains a challenge for medical image segmentation. To address this issue, few-shot segmentation methods based on meta-learning have been employed. Presently, the methods primarily focus on aligning the support set and query set to enhance performance, but this approach hinders further improvement of the model's effectiveness. In this paper, our objective is to propose a few-shot medical segmentation model that acquire comprehensive feature representation capabilities, which will boost segmentation accuracy by capturing both local and long-range features. To achieve this, we introduce a plug-and-play attention module that dynamically enhances both query and support features, thereby improving the representativeness of the extracted features. Our model comprises four key modules: a dual-path feature extractor, an attention module, an adaptive prototype prediction module, and a multi-scale prediction fusion module. Specifically, the dual-path feature extractor acquires multi-scale features by obtaining features of 32{times}32 size and 64{times}64 size. The attention module follows the feature extractor and captures local and long-range information. The adaptive prototype prediction module automatically adjusts the anomaly score threshold to predict prototypes, while the multi-scale fusion prediction module integrates prediction masks of various scales to produce the final segmentation result. We conducted experiments on publicly available MRI datasets, namely CHAOS and CMR, and compared our method with other advanced techniques. The results demonstrate that our method achieves state-of-the-art performance.
Read more7/30/2024
0
Enhancing Few-Shot Image Classification through Learnable Multi-Scale Embedding and Attention Mechanisms
Fatemeh Askari, Amirreza Fateh, Mohammad Reza Mohammadi
In the context of few-shot classification, the goal is to train a classifier using a limited number of samples while maintaining satisfactory performance. However, traditional metric-based methods exhibit certain limitations in achieving this objective. These methods typically rely on a single distance value between the query feature and support feature, thereby overlooking the contribution of shallow features. To overcome this challenge, we propose a novel approach in this paper. Our approach involves utilizing multi-output embedding network that maps samples into distinct feature spaces. The proposed method extract feature vectors at different stages, enabling the model to capture both global and abstract features. By utilizing these diverse feature spaces, our model enhances its performance. Moreover, employing a self-attention mechanism improves the refinement of features at each stage, leading to even more robust representations and improved overall performance. Furthermore, assigning learnable weights to each stage significantly improved performance and results. We conducted comprehensive evaluations on the MiniImageNet and FC100 datasets, specifically in the 5-way 1-shot and 5-way 5-shot scenarios. Additionally, we performed a cross-domain task from MiniImageNet to the CUB dataset, achieving high accuracy in the testing domain. These evaluations demonstrate the efficacy of our proposed method in comparison to state-of-the-art approaches. https://github.com/FatemehAskari/MSENet
Read more9/14/2024

0
Correlation Weighted Prototype-based Self-Supervised One-Shot Segmentation of Medical Images
Siladittya Manna, Saumik Bhattacharya, Umapada Pal
Medical image segmentation is one of the domains where sufficient annotated data is not available. This necessitates the application of low-data frameworks like few-shot learning. Contemporary prototype-based frameworks often do not account for the variation in features within the support and query images, giving rise to a large variance in prototype alignment. In this work, we adopt a prototype-based self-supervised one-way one-shot learning framework using pseudo-labels generated from superpixels to learn the semantic segmentation task itself. We use a correlation-based probability score to generate a dynamic prototype for each query pixel from the bag of prototypes obtained from the support feature map. This weighting scheme helps to give a higher weightage to contextually related prototypes. We also propose a quadrant masking strategy in the downstream segmentation task by utilizing prior domain information to discard unwanted false positives. We present extensive experimentations and evaluations on abdominal CT and MR datasets to show that the proposed simple but potent framework performs at par with the state-of-the-art methods.
Read more8/13/2024

0
Retrieval-augmented Few-shot Medical Image Segmentation with Foundation Models
Lin Zhao, Xiao Chen, Eric Z. Chen, Yikang Liu, Terrence Chen, Shanhui Sun
Medical image segmentation is crucial for clinical decision-making, but the scarcity of annotated data presents significant challenges. Few-shot segmentation (FSS) methods show promise but often require retraining on the target domain and struggle to generalize across different modalities. Similarly, adapting foundation models like the Segment Anything Model (SAM) for medical imaging has limitations, including the need for finetuning and domain-specific adaptation. To address these issues, we propose a novel method that adapts DINOv2 and Segment Anything Model 2 (SAM 2) for retrieval-augmented few-shot medical image segmentation. Our approach uses DINOv2's feature as query to retrieve similar samples from limited annotated data, which are then encoded as memories and stored in memory bank. With the memory attention mechanism of SAM 2, the model leverages these memories as conditions to generate accurate segmentation of the target image. We evaluated our framework on three medical image segmentation tasks, demonstrating superior performance and generalizability across various modalities without the need for any retraining or finetuning. Overall, this method offers a practical and effective solution for few-shot medical image segmentation and holds significant potential as a valuable annotation tool in clinical applications.
Read more8/19/2024