Few-shot Object Localization

0

Sign in to get full access
Overview
- Few-shot object localization aims to efficiently locate objects in images using only a few training examples.
- This is an important challenge as it could enable faster and more flexible object detection systems, particularly for rare or novel objects.
- The paper explores techniques for few-shot object localization, which can be useful for a variety of applications like robotics, surveillance, and autonomous vehicles.
Plain English Explanation
Object localization is the task of finding the location of specific objects within an image. Typically, this requires training a machine learning model on a large dataset of labeled images. However, few-shot object localization aims to achieve this using only a small number of example images, similar to how humans can quickly learn to recognize new objects.
This is a valuable capability, as it could allow object detection systems to be quickly adapted to new scenarios or rare objects without needing massive training datasets. For example, in robotics or autonomous vehicles, being able to quickly localize novel objects could improve safety and adaptability. It could also benefit surveillance applications by allowing the system to be updated with new targets of interest.
The key challenge is figuring out how to extract meaningful information from just a handful of examples, rather than relying on the massive datasets typically used for object detection. The paper explores different techniques and architectures to address this problem.
Technical Explanation
The paper proposes a few-shot object localization framework that can efficiently locate objects in images using only a small number of annotated examples. The approach involves a two-stage process:
-
Feature Extraction: A feature extraction module is used to encode the input image and the few-shot query object into a shared feature space. This allows the model to identify relevant visual cues and similarities between the query object and the objects in the image.
-
Localization: A localization module then takes the encoded features and predicts the bounding boxes of the target objects in the image. This is done in a differentiable manner, allowing the entire framework to be trained end-to-end.
The key innovations include:
- A meta-learning approach that allows the model to rapidly adapt to new object categories with limited data.
- Attention mechanisms that help the model focus on the most relevant visual cues for the given query object.
- A spatial similarity learning component that models the spatial relationships between the query object and the target objects.
The paper evaluates the proposed framework on several few-shot object localization benchmarks, demonstrating improved performance compared to previous state-of-the-art methods.
Critical Analysis
The paper presents a compelling approach to the challenging problem of few-shot object localization. The authors have thoughtfully designed the architecture and training process to effectively leverage limited training data, which is a significant advancement.
However, the paper does not fully address the potential limitations and real-world challenges of this technology. For example, the experiments are conducted on relatively clean, controlled datasets, and it's unclear how well the model would perform in noisier, more complex environments. Additionally, the paper does not discuss potential biases or fairness issues that could arise from the training data or model design.
Further research is needed to understand the broader implications and practical considerations of deploying few-shot object localization systems, particularly in high-stakes applications like autonomous vehicles or surveillance. Careful evaluation of the model's robustness, generalization, and potential societal impacts would be valuable.
Conclusion
This paper presents an innovative approach to the problem of few-shot object localization, which could enable more flexible and efficient object detection systems. By leveraging meta-learning and spatial similarity modeling, the proposed framework can effectively locate objects using only a small number of training examples.
The technical contributions, including the feature extraction and localization modules, demonstrate the potential of this approach. However, more research is needed to understand the real-world limitations and broader implications of this technology.
Overall, the paper provides a promising step forward in the field of few-shot object localization, with the potential to unlock new applications and opportunities in areas like robotics, surveillance, and autonomous vehicles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Few-shot Object Localization
Yunhan Ren, Bo Li, Chengyang Zhang, Yong Zhang, Baocai Yin
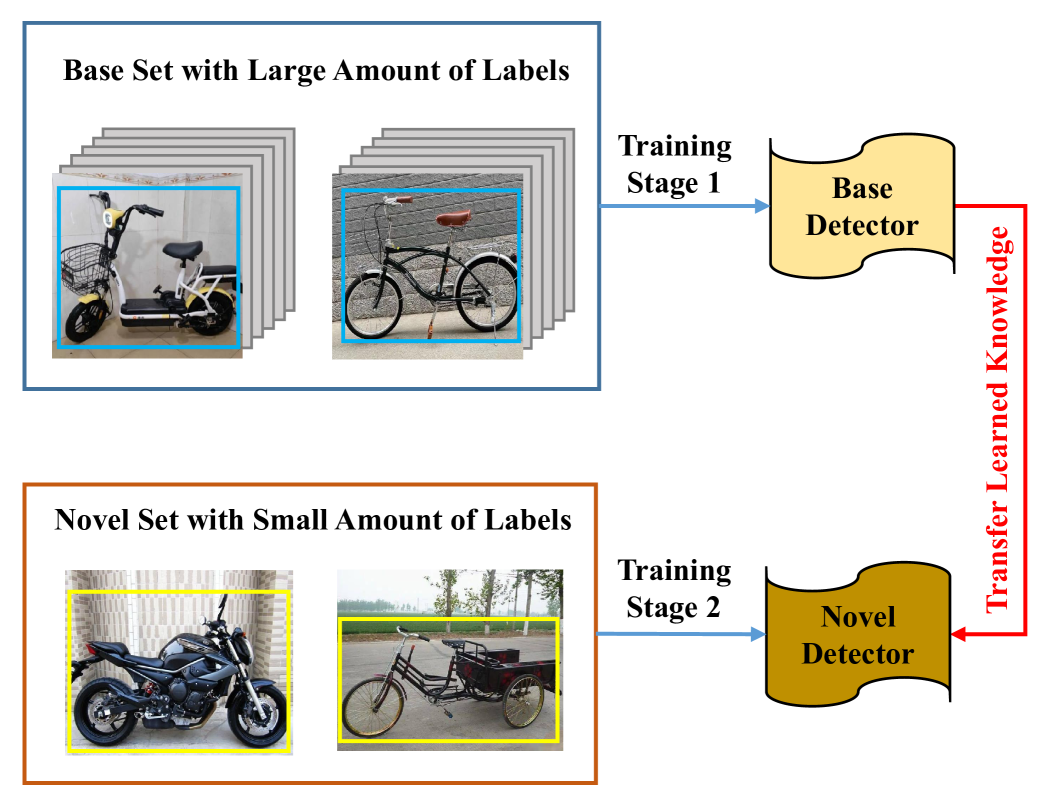
Existing object localization methods are tailored to locate specific classes of objects, relying heavily on abundant labeled data for model optimization. However, acquiring large amounts of labeled data is challenging in many real-world scenarios, significantly limiting the broader application of localization models. To bridge this research gap, this paper defines a novel task named Few-Shot Object Localization (FSOL), which aims to achieve precise localization with limited samples. This task achieves generalized object localization by leveraging a small number of labeled support samples to query the positional information of objects within corresponding images. To advance this field, we design an innovative high-performance baseline model. This model integrates a dual-path feature augmentation module to enhance shape association and gradient differences between supports and query images, alongside a self query module to explore the association between feature maps and query images. Experimental results demonstrate a significant performance improvement of our approach in the FSOL task, establishing an efficient benchmark for further research. All codes and data are available at https://github.com/Ryh1218/FSOL.
Read more6/6/2024
0
Few-Shot Object Detection: Research Advances and Challenges
Zhimeng Xin, Shiming Chen, Tianxu Wu, Yuanjie Shao, Weiping Ding, Xinge You
Object detection as a subfield within computer vision has achieved remarkable progress, which aims to accurately identify and locate a specific object from images or videos. Such methods rely on large-scale labeled training samples for each object category to ensure accurate detection, but obtaining extensive annotated data is a labor-intensive and expensive process in many real-world scenarios. To tackle this challenge, researchers have explored few-shot object detection (FSOD) that combines few-shot learning and object detection techniques to rapidly adapt to novel objects with limited annotated samples. This paper presents a comprehensive survey to review the significant advancements in the field of FSOD in recent years and summarize the existing challenges and solutions. Specifically, we first introduce the background and definition of FSOD to emphasize potential value in advancing the field of computer vision. We then propose a novel FSOD taxonomy method and survey the plentifully remarkable FSOD algorithms based on this fact to report a comprehensive overview that facilitates a deeper understanding of the FSOD problem and the development of innovative solutions. Finally, we discuss the advantages and limitations of these algorithms to summarize the challenges, potential research direction, and development trend of object detection in the data scarcity scenario.
Read more4/9/2024

0
Beyond Few-shot Object Detection: A Detailed Survey
Vishal Chudasama, Hiran Sarkar, Pankaj Wasnik, Vineeth N Balasubramanian, Jayateja Kalla
Object detection is a critical field in computer vision focusing on accurately identifying and locating specific objects in images or videos. Traditional methods for object detection rely on large labeled training datasets for each object category, which can be time-consuming and expensive to collect and annotate. To address this issue, researchers have introduced few-shot object detection (FSOD) approaches that merge few-shot learning and object detection principles. These approaches allow models to quickly adapt to new object categories with only a few annotated samples. While traditional FSOD methods have been studied before, this survey paper comprehensively reviews FSOD research with a specific focus on covering different FSOD settings such as standard FSOD, generalized FSOD, incremental FSOD, open-set FSOD, and domain adaptive FSOD. These approaches play a vital role in reducing the reliance on extensive labeled datasets, particularly as the need for efficient machine learning models continues to rise. This survey paper aims to provide a comprehensive understanding of the above-mentioned few-shot settings and explore the methodologies for each FSOD task. It thoroughly compares state-of-the-art methods across different FSOD settings, analyzing them in detail based on their evaluation protocols. Additionally, it offers insights into their applications, challenges, and potential future directions in the evolving field of object detection with limited data.
Read more8/27/2024
0
The Solution for CVPR2024 Foundational Few-Shot Object Detection Challenge
Hongpeng Pan, Shifeng Yi, Shouwei Yang, Lei Qi, Bing Hu, Yi Xu, Yang Yang
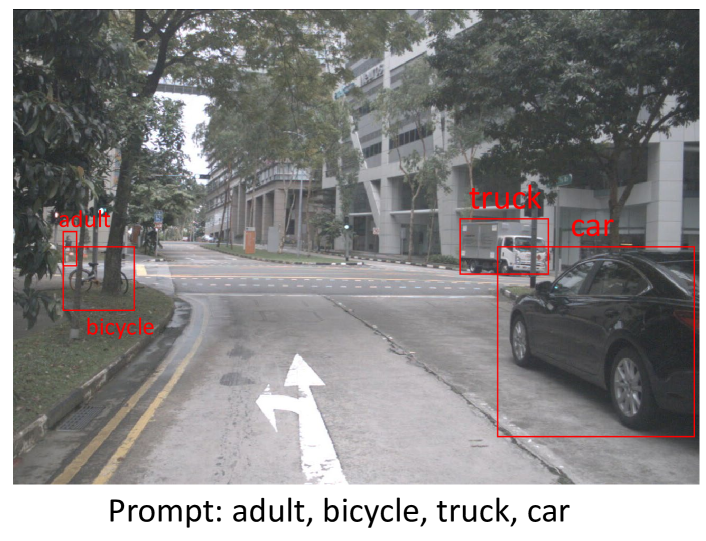
This report introduces an enhanced method for the Foundational Few-Shot Object Detection (FSOD) task, leveraging the vision-language model (VLM) for object detection. However, on specific datasets, VLM may encounter the problem where the detected targets are misaligned with the target concepts of interest. This misalignment hinders the zero-shot performance of VLM and the application of fine-tuning methods based on pseudo-labels. To address this issue, we propose the VLM+ framework, which integrates the multimodal large language model (MM-LLM). Specifically, we use MM-LLM to generate a series of referential expressions for each category. Based on the VLM predictions and the given annotations, we select the best referential expression for each category by matching the maximum IoU. Subsequently, we use these referential expressions to generate pseudo-labels for all images in the training set and then combine them with the original labeled data to fine-tune the VLM. Additionally, we employ iterative pseudo-label generation and optimization to further enhance the performance of the VLM. Our approach achieve 32.56 mAP in the final test.
Read more6/19/2024