Fewer Truncations Improve Language Modeling
2404.10830
1
0
Abstract
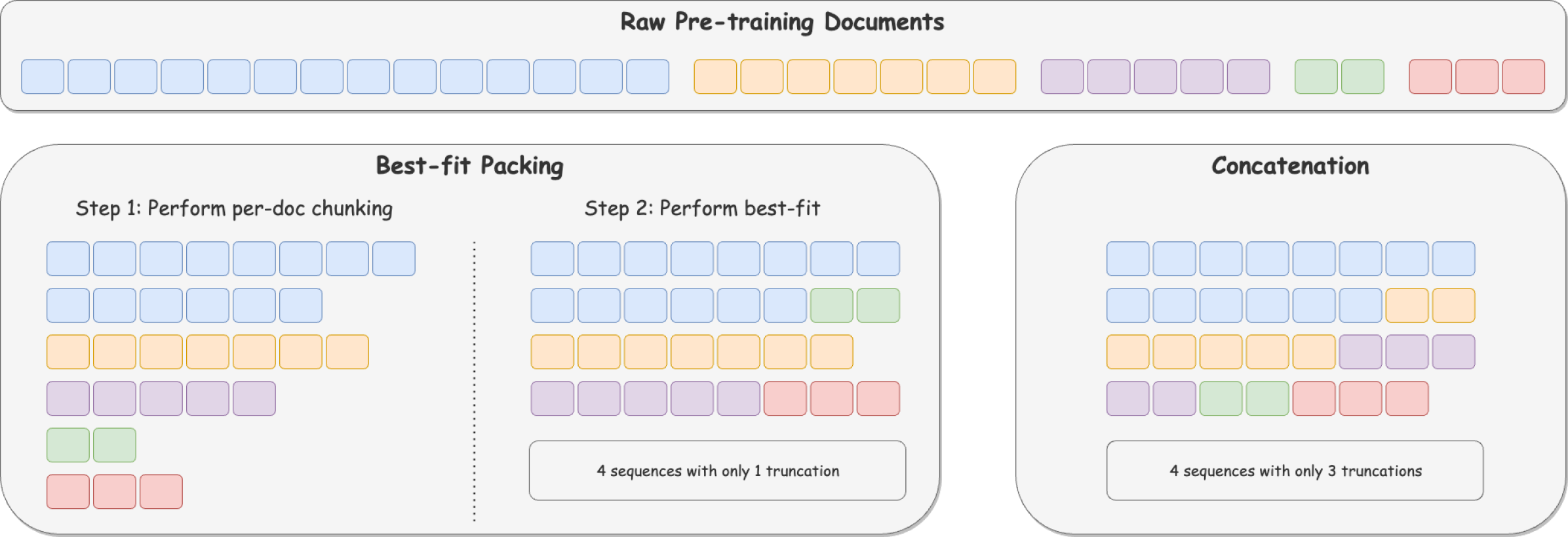
In large language model training, input documents are typically concatenated together and then split into sequences of equal length to avoid padding tokens. Despite its efficiency, the concatenation approach compromises data integrity -- it inevitably breaks many documents into incomplete pieces, leading to excessive truncations that hinder the model from learning to compose logically coherent and factually consistent content that is grounded on the complete context. To address the issue, we propose Best-fit Packing, a scalable and efficient method that packs documents into training sequences through length-aware combinatorial optimization. Our method completely eliminates unnecessary truncations while retaining the same training efficiency as concatenation. Empirical results from both text and code pre-training show that our method achieves superior performance (e.g., relatively +4.7% on reading comprehension; +16.8% in context following; and +9.2% on program synthesis), and reduces closed-domain hallucination effectively by up to 58.3%.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper examines the issue of "truncation" in language modeling, which can limit the performance of large language models.
- The researchers provide an analytical study and empirical results to show that reducing the amount of truncation can lead to significant improvements in language modeling.
- The key insight is that truncation can introduce biases and distortions that accumulate over long sequences, hampering the model's ability to capture long-range dependencies.
Plain English Explanation
Large language models, like the ones used for tasks like text generation and dialogue, are trained on massive amounts of text data. During training, these models often need to "truncate" or shorten the input sequences to fit within the memory constraints of the hardware.
However, the researchers argue that this truncation process can actually be detrimental to the model's performance. Imagine you're trying to understand a complex story, but every time the story gets too long, someone interrupts you and forces you to start over from the beginning. Over time, this would make it very difficult to follow the overall narrative and understand the relationships between different events and characters.
Similarly, the paper shows that the truncation process in language models can introduce biases and distortions that accumulate over long sequences, making it harder for the model to capture important long-range dependencies in the text. By reducing the amount of truncation, the researchers were able to significantly improve the performance of their language models, particularly on tasks that require understanding long-range context.
Technical Explanation
The researchers first provide an analytical study of the effects of truncation using a simplified stochastic process. They show that truncation can lead to biases and distortions in the model's internal representations, which become more pronounced as the sequence length increases.
To validate their analytical findings, the researchers then conduct empirical experiments on various language modeling tasks. They compare the performance of models trained with different levels of truncation, ranging from short (e.g., 128 tokens) to long (e.g., 2048 tokens). The results consistently demonstrate that reducing the amount of truncation leads to substantial improvements in the models' perplexity scores, a common metric for language model performance.
The researchers also investigate the impact of truncation on the models' ability to capture long-range dependencies. They find that with less truncation, the models are better able to maintain and utilize information from the earlier parts of the input sequence, leading to better overall language understanding.
Critical Analysis
The paper provides a thorough and well-designed study of the effects of truncation in language modeling. The analytical approach offers valuable insights into the underlying mechanisms and limitations of the truncation process.
However, the researchers acknowledge that their analysis is based on a simplified stochastic process, and the real-world dynamics of large language models may be more complex. Additionally, the empirical experiments are conducted on a limited set of tasks and datasets, and it would be interesting to see the results replicated on a wider range of benchmarks.
Another potential limitation is that the researchers do not explore the trade-offs between the benefits of reduced truncation and the increased computational requirements and memory footprint. In practice, language model developers may need to balance these considerations, especially when deploying models on resource-constrained hardware.
It would also be worth investigating the potential negative impacts of overly long sequences on model training and inference, as excessively long inputs could introduce other challenges, such as gradient instability or slower convergence.
Conclusion
This paper presents a compelling case for the importance of reducing truncation in language modeling. By providing both analytical and empirical evidence, the researchers demonstrate that fewer truncations can lead to significant improvements in a model's ability to capture long-range dependencies and overall language understanding.
The findings have important implications for the design and training of large language models, as well as their deployment in real-world applications. As the field of natural language processing continues to advance, addressing the "curse of truncation" could be a valuable step towards building more powerful and versatile language models that can better understand and generate human-like text.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval
Jo~ao Coelho, Bruno Martins, Jo~ao Magalh~aes, Jamie Callan, Chenyan Xiong
0
0
This study investigates the existence of positional biases in Transformer-based models for text representation learning, particularly in the context of web document retrieval. We build on previous research that demonstrated loss of information in the middle of input sequences for causal language models, extending it to the domain of representation learning. We examine positional biases at various stages of training for an encoder-decoder model, including language model pre-training, contrastive pre-training, and contrastive fine-tuning. Experiments with the MS-MARCO document collection reveal that after contrastive pre-training the model already generates embeddings that better capture early contents of the input, with fine-tuning further aggravating this effect.
4/8/2024
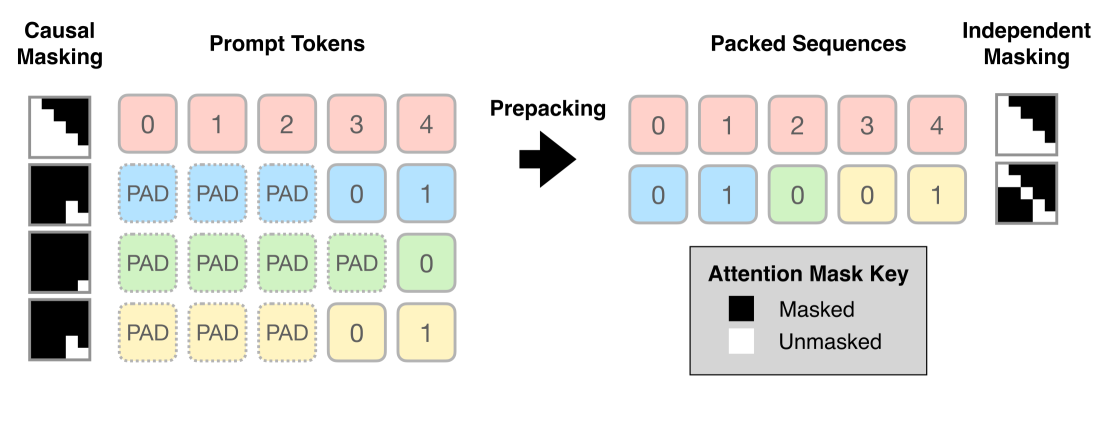
Prepacking: A Simple Method for Fast Prefilling and Increased Throughput in Large Language Models
Siyan Zhao, Daniel Israel, Guy Van den Broeck, Aditya Grover
0
0
During inference for transformer-based large language models (LLM), prefilling is the computation of the key-value (KV) cache for input tokens in the prompt prior to autoregressive generation. For longer input prompt lengths, prefilling will incur a significant overhead on decoding time. In this work, we highlight the following pitfall of prefilling: for batches containing high-varying prompt lengths, significant computation is wasted by the standard practice of padding sequences to the maximum length. As LLMs increasingly support longer context lengths, potentially up to 10 million tokens, variations in prompt lengths within a batch become more pronounced. To address this, we propose Prepacking, a simple yet effective method to optimize prefilling computation. To avoid redundant computation on pad tokens, prepacking combines prompts of varying lengths into a sequence and packs multiple sequences into a compact batch using a bin-packing algorithm. It then modifies the attention mask and positional encoding to compute multiple prefilled KV-caches for multiple prompts within a single sequence. On standard curated dataset containing prompts with varying lengths, we obtain a significant speed and memory efficiency improvements as compared to the default padding-based prefilling computation within Huggingface across a range of base model configurations and inference serving scenarios.
4/16/2024
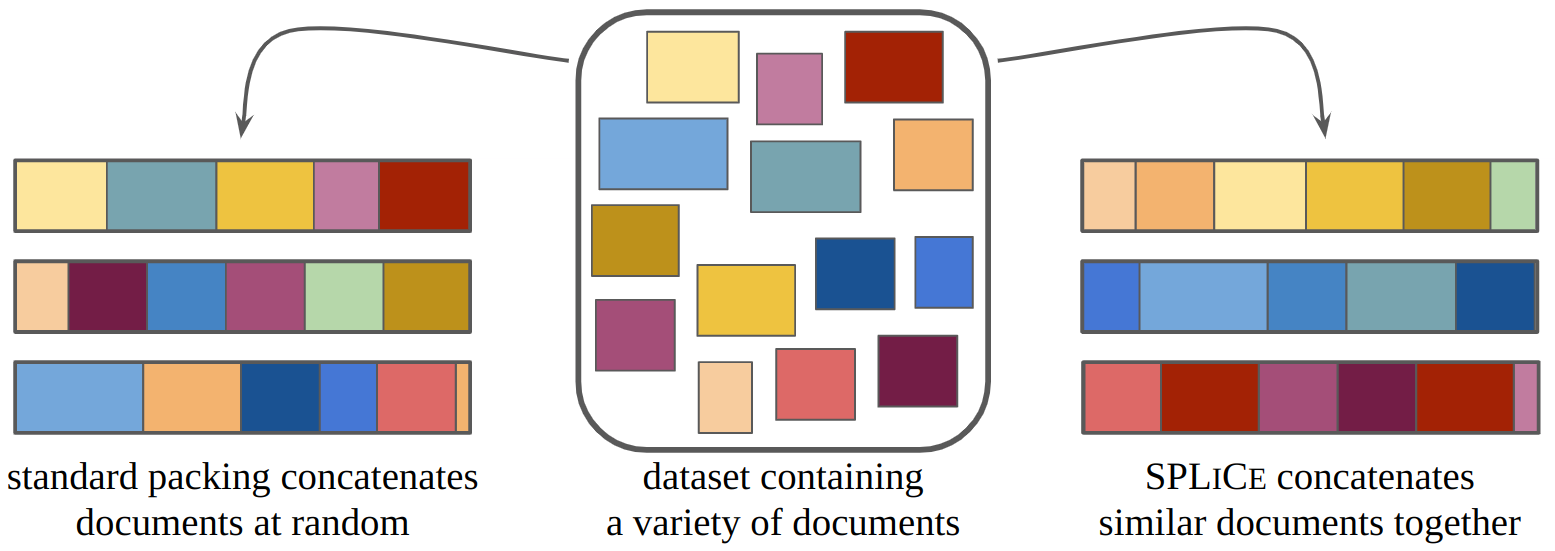
Structured Packing in LLM Training Improves Long Context Utilization
Konrad Staniszewski, Szymon Tworkowski, Yu Zhao, Sebastian Jaszczur, Henryk Michalewski, {L}ukasz Kuci'nski, Piotr Mi{l}o's
0
0
Recent developments in long-context large language models have attracted considerable attention. Yet, their real-world applications are often hindered by ineffective context information use. This work shows that structuring training data to increase semantic interdependence is an effective strategy for optimizing context utilization. To this end, we introduce Structured Packing for Long Context (SPLiCe), a method for creating training examples by using information retrieval methods to collate mutually relevant documents into a single training context. We empirically validate SPLiCe on large $3$B and $7$B models, showing perplexity improvements and better long-context utilization on downstream tasks. Remarkably, already relatively short fine-tuning with SPLiCe is enough to attain these benefits. Additionally, the comprehensive study of SPLiCe reveals intriguing transfer effects such as training on code data leading to perplexity improvements on text data.
4/29/2024
💬
The Ups and Downs of Large Language Model Inference with Vocabulary Trimming by Language Heuristics
Nikolay Bogoychev, Pinzhen Chen, Barry Haddow, Alexandra Birch
0
0
Deploying large language models (LLMs) encounters challenges due to intensive computational and memory requirements. Our research examines vocabulary trimming (VT) inspired by restricting embedding entries to the language of interest to bolster time and memory efficiency. While such modifications have been proven effective in tasks like machine translation, tailoring them to LLMs demands specific modifications given the diverse nature of LLM applications. We apply two language heuristics to trim the full vocabulary - Unicode-based script filtering and corpus-based selection - to different LLM families and sizes. The methods are straightforward, interpretable, and easy to implement. It is found that VT reduces the memory usage of small models by nearly 50% and has an upper bound of 25% improvement in generation speed. Yet, we reveal the limitations of these methods in that they do not perform consistently well for each language with diminishing returns in larger models.
4/30/2024