Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval
2404.04163
0
0
💬
Abstract
This study investigates the existence of positional biases in Transformer-based models for text representation learning, particularly in the context of web document retrieval. We build on previous research that demonstrated loss of information in the middle of input sequences for causal language models, extending it to the domain of representation learning. We examine positional biases at various stages of training for an encoder-decoder model, including language model pre-training, contrastive pre-training, and contrastive fine-tuning. Experiments with the MS-MARCO document collection reveal that after contrastive pre-training the model already generates embeddings that better capture early contents of the input, with fine-tuning further aggravating this effect.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This study investigates the existence of positional biases in Transformer-based models for text representation learning, particularly in the context of web document retrieval.
- The researchers build on previous research that demonstrated loss of information in the middle of input sequences for causal language models, extending it to the domain of representation learning.
- The study examines positional biases at various stages of training for an encoder-decoder model, including language model pre-training, contrastive pre-training, and contrastive fine-tuning.
Plain English Explanation
Transformer models are a type of artificial intelligence (AI) system that are widely used for understanding and generating text. This study looks at whether these models develop biases based on the position of information within the text they are trained on.
Previous research has shown that when Transformer models are used to predict the next word in a sentence (known as causal language modeling), they tend to lose information about the middle parts of the input text. This new study extends that finding to Transformer models that are used to learn general representations of text, rather than just predicting the next word.
The researchers examine how these positional biases develop at different stages of training the Transformer model - when it is first pre-trained on a large amount of text data, when it is further pre-trained using a technique called contrastive learning, and when it is fine-tuned for the specific task of retrieving relevant web documents.
Technical Explanation
The study uses an encoder-decoder Transformer model architecture and examines positional biases at multiple stages of the training process:
-
Language Model Pre-training: The model is first pre-trained on a large corpus of text data to build general language understanding capabilities, similar to how techniques like those used in this paper can enhance sentence embeddings.
-
Contrastive Pre-training: The pre-trained model then undergoes additional contrastive pre-training, where it learns to differentiate between related and unrelated text passages, akin to how LLMs can be transformed into cross-modal, cross-lingual models.
-
Contrastive Fine-tuning: Finally, the model is fine-tuned on the specific task of web document retrieval using the MS-MARCO dataset, building on position-aware fine-tuning approaches.
Experiments on the MS-MARCO dataset reveal that after the contrastive pre-training stage, the model already generates embeddings that better capture the early contents of the input text. This effect is further amplified during the contrastive fine-tuning stage.
Critical Analysis
The paper acknowledges that the observed positional biases may be a result of the specific training setup and dataset used, and that further research is needed to understand the generalizability of these findings. As highlighted in this paper on when not to trust language models, it's important to carefully evaluate the limitations and potential issues with language models, especially when they are being used in high-stakes applications.
Additionally, the paper does not delve into the potential societal implications of these positional biases, such as how they may affect the fairness and inclusivity of text-based AI systems. Future research could explore these important considerations, particularly in the context of developing healthcare language model embedding spaces.
Conclusion
This study provides valuable insights into the positional biases that can arise in Transformer-based text representation learning models, particularly during contrastive pre-training and fine-tuning. These findings highlight the need for careful evaluation and mitigation of such biases to ensure the fairness and reliability of AI systems that rely on text understanding. As Transformer models continue to be widely adopted, addressing these issues will be crucial for realizing their full potential in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
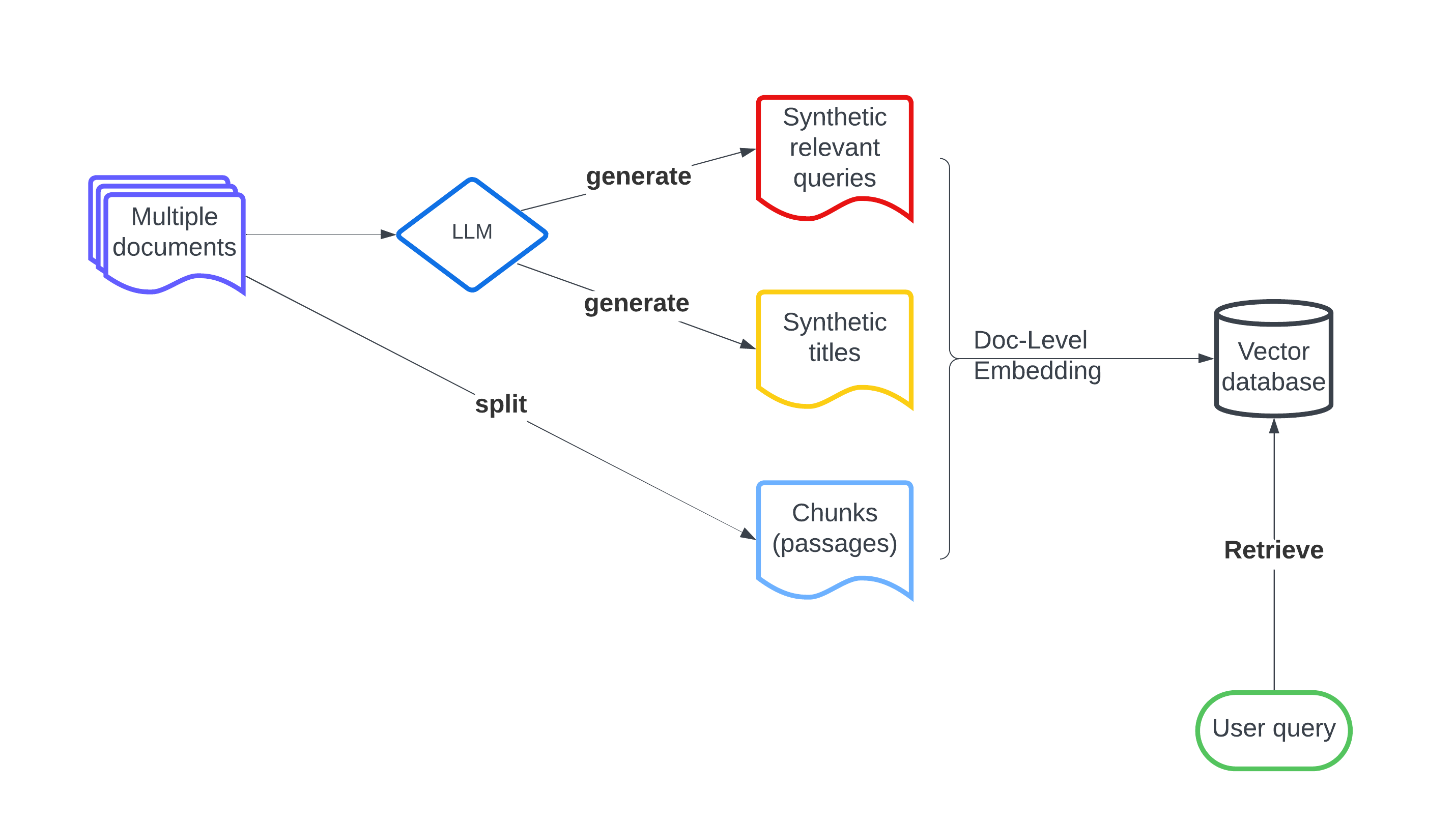
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
0
0
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
4/10/2024
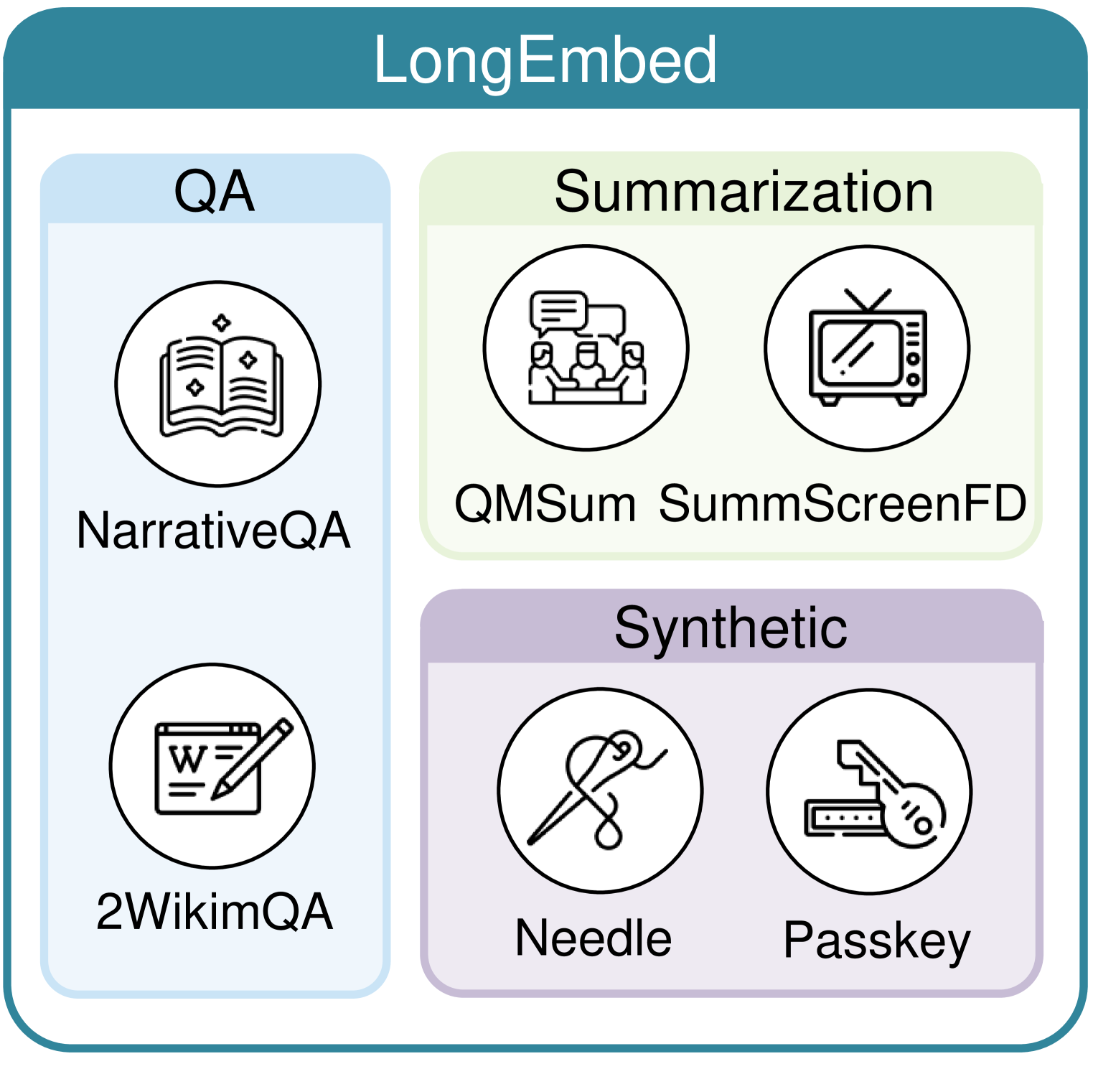
LongEmbed: Extending Embedding Models for Long Context Retrieval
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li
0
0
Embedding models play a pivot role in modern NLP applications such as IR and RAG. While the context limit of LLMs has been pushed beyond 1 million tokens, embedding models are still confined to a narrow context window not exceeding 8k tokens, refrained from application scenarios requiring long inputs such as legal contracts. This paper explores context window extension of existing embedding models, pushing the limit to 32k without requiring additional training. First, we examine the performance of current embedding models for long context retrieval on our newly constructed LongEmbed benchmark. LongEmbed comprises two synthetic tasks and four carefully chosen real-world tasks, featuring documents of varying length and dispersed target information. Benchmarking results underscore huge room for improvement in these models. Based on this, comprehensive experiments show that training-free context window extension strategies like position interpolation can effectively extend the context window of existing embedding models by several folds, regardless of their original context being 512 or beyond 4k. Furthermore, for models employing absolute position encoding (APE), we show the possibility of further fine-tuning to harvest notable performance gains while strictly preserving original behavior for short inputs. For models using rotary position embedding (RoPE), significant enhancements are observed when employing RoPE-specific methods, such as NTK and SelfExtend, indicating RoPE's superiority over APE for context window extension. To facilitate future research, we release E5-Base-4k and E5-RoPE-Base, along with the LongEmbed benchmark.
4/26/2024
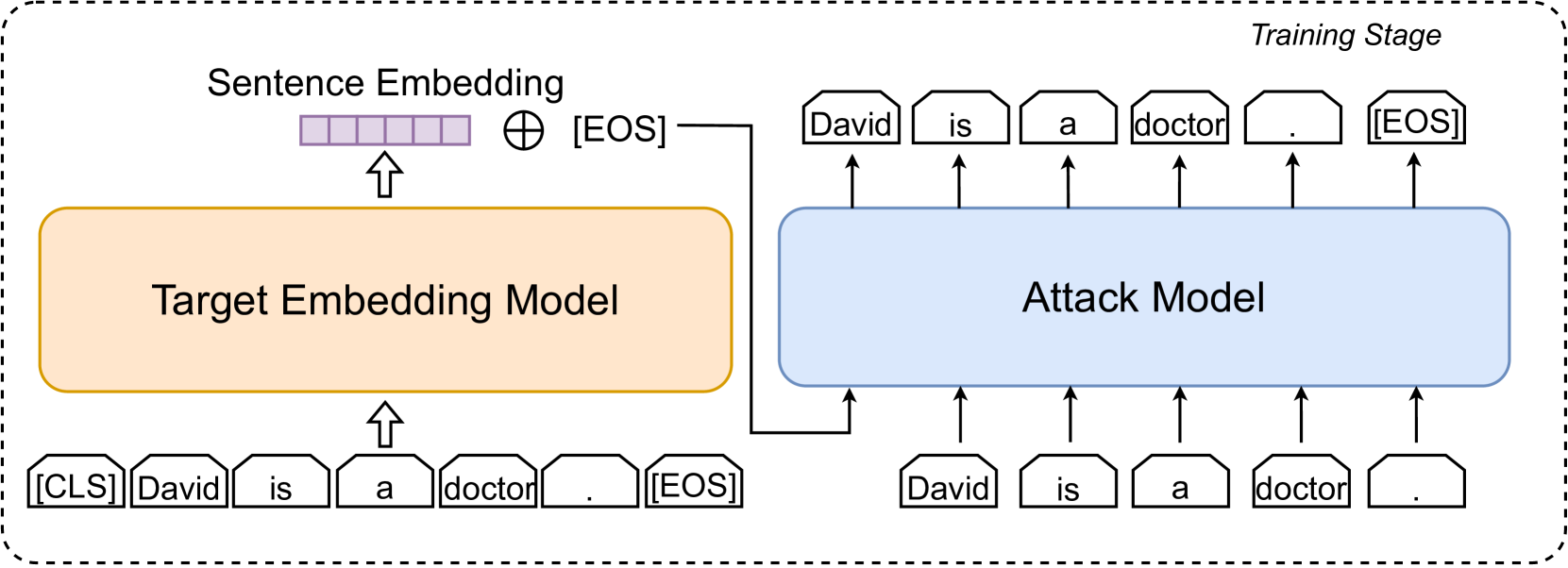
Understanding Privacy Risks of Embeddings Induced by Large Language Models
Zhihao Zhu, Ninglu Shao, Defu Lian, Chenwang Wu, Zheng Liu, Yi Yang, Enhong Chen
0
0
Large language models (LLMs) show early signs of artificial general intelligence but struggle with hallucinations. One promising solution to mitigate these hallucinations is to store external knowledge as embeddings, aiding LLMs in retrieval-augmented generation. However, such a solution risks compromising privacy, as recent studies experimentally showed that the original text can be partially reconstructed from text embeddings by pre-trained language models. The significant advantage of LLMs over traditional pre-trained models may exacerbate these concerns. To this end, we investigate the effectiveness of reconstructing original knowledge and predicting entity attributes from these embeddings when LLMs are employed. Empirical findings indicate that LLMs significantly improve the accuracy of two evaluated tasks over those from pre-trained models, regardless of whether the texts are in-distribution or out-of-distribution. This underscores a heightened potential for LLMs to jeopardize user privacy, highlighting the negative consequences of their widespread use. We further discuss preliminary strategies to mitigate this risk.
4/26/2024
💬
Technical Report: Impact of Position Bias on Language Models in Token Classification
Mehdi Ben Amor, Michael Granitzer, Jelena Mitrovi'c
0
0
Language Models (LMs) have shown state-of-the-art performance in Natural Language Processing (NLP) tasks. Downstream tasks such as Named Entity Recognition (NER) or Part-of-Speech (POS) tagging are known to suffer from data imbalance issues, particularly regarding the ratio of positive to negative examples and class disparities. This paper investigates an often-overlooked issue of encoder models, specifically the position bias of positive examples in token classification tasks. For completeness, we also include decoders in the evaluation. We evaluate the impact of position bias using different position embedding techniques, focusing on BERT with Absolute Position Embedding (APE), Relative Position Embedding (RPE), and Rotary Position Embedding (RoPE). Therefore, we conduct an in-depth evaluation of the impact of position bias on the performance of LMs when fine-tuned on token classification benchmarks. Our study includes CoNLL03 and OntoNote5.0 for NER, English Tree Bank UD_en, and TweeBank for POS tagging. We propose an evaluation approach to investigate position bias in transformer models. We show that LMs can suffer from this bias with an average drop ranging from 3% to 9% in their performance. To mitigate this effect, we propose two methods: Random Position Shifting and Context Perturbation, that we apply on batches during the training process. The results show an improvement of $approx$ 2% in the performance of the model on CoNLL03, UD_en, and TweeBank.
4/12/2024